Formát souboru LZMA
Jak přistupovat, upravovat, generovat, dekomprimovat a transformovat soubory LZMA
Formát archivního souboru LZMA
LZMA (Lempel-Ziv-Markov chain algorithm) je moderní algoritmus komprese dat známý svou vysokou účinností a výjimečným kompresním poměrem. LZMA, široce používaný v archivních formátech, jako je
7z
, účinně snižuje velikost souboru bez významné oběti na rychlosti dekomprese. Archivy LZMA zaručují zachování kvality a integrity dat, díky čemuž jsou dokonalým řešením pro efektivní ukládání a správu velkých datových sad.
Hlavní výhodou LZMA je jeho schopnost zpracovávat velké soubory a složité datové struktury s minimálními ztrátami. Použití LZMA umožňuje optimalizovat místo na disku a usnadňuje přenos souborů přes internet díky menší velikosti archivu. Díky tomu je LZMA oblíbenou volbou mezi vývojáři a správci systému pro efektivní správu dat.
Informace o archivu LZMA
Archivy LZMA podporují paralelizaci, která umožňuje efektivní využití vícejádrových procesorů pro rychlejší kompresi a dekompresi souborů. LZMA se navíc vyznačuje vysokou odolností proti poškození, díky čemuž je spolehlivou volbou pro dlouhodobé uchovávání důležitých dat. Algoritmus má také otevřený zdrojový kód, což usnadňuje jeho širokou implementaci a adaptaci v různých softwarových řešeních. Díky svým výhodám zůstává LZMA jedním z nejúčinnějších kompresních formátů, který poskytuje optimální správu dat uživatelům po celém světě.
Evoluce LZMA
Algoritmus LZMA, vyvinutý Igorem Pavlovem v roce 1998 jako součást projektu 7-Zip, měl za cíl vytvořit vysoce efektivní metodu komprese dat. Zpočátku stavěl na klasických algoritmech LZ77 a zahrnoval techniky, které významně zvýšily účinnost komprese. Postupně LZMA získala uznání pro svou schopnost zpracovávat velké datové sady s minimální spotřebou zdrojů. V roce 2001 se LZMA stal základním kompresním algoritmem pro formát 7z, který si rychle získal popularitu díky svému vynikajícímu výkonu. Kromě toho byl algoritmus integrován do mnoha archivátorů a systémů pro ukládání dat, zejména do softwarových produktů s otevřeným zdrojovým kódem. Dnes se LZMA neustále vyvíjí, udržuje si svou relevanci prostřednictvím neustálých aktualizací a optimalizací a upevňuje svou pozici jako nepostradatelný nástroj v digitálním světě.
Principy algoritmu LZMA
Algoritmus LZMA je založen na použití sekvenčního opakování v datech pro dosažení vysokého stupně komprese. Hlavní myšlenkou algoritmu je vytvořit a uložit slovník obsahující dříve nalezené podřetězce, které jsou pak nahrazeny odkazy v tomto slovníku. To vám umožní výrazně snížit množství dat, která mají být uložena nebo přenášena. Jednou z klíčových vlastností LZMA je použití kódování rozsahu namísto Huffmanova kódování. Rozsahové kódování nabízí lepší kompresi blíže k entropii dat a využívá binární formát, čímž se vyhne pomalým operacím dělení celých čísel.
LZMA používá algoritmus LZ77 k nalezení nejdelších shod ve vyrovnávací paměti vyhledávání a predikční vyrovnávací paměti a zapisuje je do komprimovaného souboru ve formě trojice (vzdálenost, délka, další znak). Pokud není nalezena žádná shoda, je k souboru připojen bajt v rozsahu [0,255]. Pokud je nalezena shoda, zaznamená se dvojice hodnot (vzdálenost a délka) zakódovaná metodou kódování rozsahu.
Pro zvýšení efektivity s velkou vyrovnávací pamětí ukládá algoritmus 4 nejběžnější vzdálenosti do vyhrazeného pole historie vzdáleností. Pokud se některá z těchto vzdáleností znovu objeví, jsou nahrazeny 2bitovým kódem odkazujícím na pole historie vzdáleností, čímž se sníží informace potřebné k uložení shody.
LZMA používá 2bajtový hash (aktuální bajt a následující bajt) k nalezení shod ve vyhledávacím bufferu. Velikost pole hash je přímo vázána na velikost slovníku. Například slovník o velikosti 1 GB používá pole hash 512 MB, které minimalizuje kolize ve funkci hash.
Tento víceúrovňový přístup poskytuje účinnou kompresi a ukládání dat bez významné spotřeby zdrojů, díky čemuž je LZMA jedním z nejúčinnějších algoritmů pro kompresi dat.
Výhody souborového formátu .lzma
Zde jsou hlavní výhody LZMA, díky nimž je atraktivní volbou pro mnoho aplikací pro kompresi dat.
- Vysoký kompresní poměr: LZMA poskytuje jeden z nejvyšších kompresních poměrů mezi existujícími algoritmy, což umožňuje výrazně snížit velikost souborů. Průměrné kompresní poměry přesahují 70 % ve srovnání s jinými archivními formáty.
- Rychlá dekomprese: Algoritmus je optimalizován pro rychlou dekompresi dat, díky čemuž je LZMA velmi vhodný pro použití v softwarových aplikacích a úložných systémech, kde je rychlé načítání dat zásadní.
- Efektivní správa velkých souborů: Vzhledem k velké velikosti vyrovnávací paměti pro vyhledávání může LZMA efektivně zpracovávat velké množství dat při zachování vysoké kompresní rychlosti.
- Spolehlivost a tolerance poškození: LZMA poskytuje vysokou odolnost proti poškození dat. I když se během ukládání nebo přenosu vyskytnou chyby, jeho konstrukce umožňuje určitou opravu chyb, minimalizuje ztrátu dat a zajišťuje integritu vašich informací během dlouhodobého ukládání.
- Otevřený zdrojový kód: Open source povaha algoritmu LZMA usnadňuje jeho širokou implementaci, adaptaci a integraci do různých softwarových řešení, čímž podporuje jeho přijetí a pokračující vývoj.
Operace podporované archivem LZMA
Aspose.ZIP umožňuje uživatelům extrahovat jednotlivé soubory i celý archiv. Pro .NET můžete použít LzmaArchiveClass k otevření souboru .lzma, poté můžete procházet jeho záznamy a extrahovat je do požadovaného umístění. Podobný přístup se používá v Javě, kde pomocí LzmaArchive otevřete soubor .lzma a extrahujete záznamy. Díky Aspose.ZIP se tyto operace stávají jednoduchými a pohodlnými pro uživatele jakékoli úrovně.
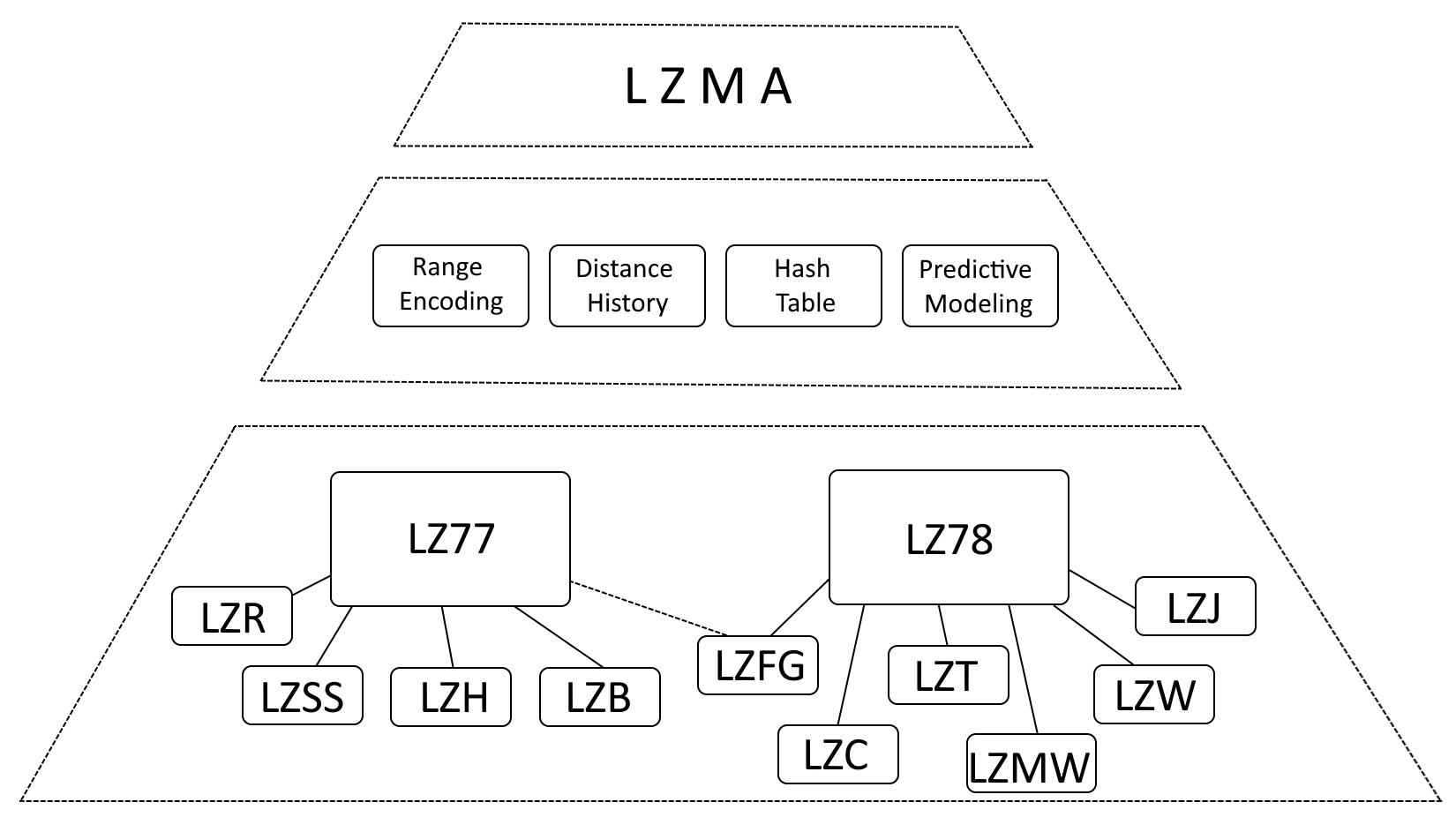
Struktura LZMA
I když je přesné říci, že LZMA je silně ovlivněna LZ77 (Lempel-Ziv 1977) a LZ78 (Lempel-Ziv 1978), je přesnější popsat LZMA jako evoluci těchto algoritmů, která zahrnuje významná vylepšení.
- Kódování rozsahu: LZMA nahrazuje Huffmanovo kódování kódováním rozsahu, což je efektivnější metoda reprezentace dat.
- Historie vzdáleností: LZMA uchovává historii často používaných vzdáleností, čímž urychluje detekci shody.
- Hashovací tabulka: LZMA využívá hašovací tabulku k urychlení hledání odpovídajících sekvencí.
- Prediktivní modelování: LZMA zahrnuje techniky prediktivního modelování pro předvídání nadcházejících datových vzorů a dále zvyšuje kompresi.
Vnitřní struktura archivu LZMA
- Metadata souboru - Podobně jako archiv tar, každý soubor ukládá základní informace, jako je čas úpravy a oprávnění. Tato část je však flexibilní a umožňuje vynechat nebo zahrnout další podrobnosti, jako jsou seznamy řízení přístupu (ACL) nebo rozšířené atributy (EA), na základě vašich potřeb. Pro zajištění integrity dat se doporučuje zahrnout silnou hashovací funkci (jako SHA1) pro běžné soubory.
- Více toků obsahu - Na rozdíl od tradičních archivů mohou mít soubory ve vnitřním datovém souboru více než jeden datový tok. To je užitečné pro ukládání rozšířených atributů nebo větví prostředků spojených se souborem.
- Záhlaví - Vnitřní indexový soubor obsahuje záhlaví souborů, která zrcadlí ty, které jsou rozptýleny ve vnitřním datovém souboru. Ale pokud jsou uloženy odděleně, záhlaví indexu musí odkazovat na počáteční pozici jejich odpovídajících dat v datovém souboru. Kromě toho položky adresáře v indexu vypisují obsažené soubory a jejich odpovídající offsety v rámci vnitřního indexu souborů.
- Odůvodnění duplicitních metadat - Tato volba designu zajišťuje efektivní streamování/dekódování dat a náhodný přístup k souborům. Navíc se metadata dobře komprimují, což vede k minimální režii úložiště. Testy ukazují, že metadata obvykle zabírají méně než 0,3 % úložného prostoru, takže kompromis se vyplatí.
- Záhlaví bloků - Záhlaví bloků, podobně jako vnější soubor, obsahuje informace o velikosti bloku a unikátní sekvenci identifikátorů.
Příklady použití LZMA Python
Pomocí Aspose.ZIP via Python API můžete snadno spravovat archivy LZMA ve svých aplikacích, čímž eliminujete potřebu dalšího externího softwaru. Rozhraní API zahrnuje třídu LzmaArchive , která zjednodušuje práci s archivy LZMA, a třídu LzmaCompressionSettings , která umožňuje přizpůsobit nastavení komprese pro optimální výkon a zmenšení velikosti souboru.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Další informace o archivech LZMA
Lidé se ptali
1. Jaké formáty souborů používají kompresi LZMA?
LZMA není samotný formát souboru, ale kompresní algoritmus používaný v různých formátech archivů. Některé běžné příklady zahrnují 7z, XZ a příležitostně ZIP. Když narazíte na soubor s těmito příponami, může být komprimován pomocí LZM
2. Je LZMA open-source?
Ano, LZMA je open-source algoritmus, díky kterému je volně dostupný pro použití a integraci do různých softwarových řešení. Tato open-source povaha přispěla k jeho širokému přijetí a pokračujícímu vývoji.
3. Jaké jsou některé alternativy k LZMA?
Několik kompresních algoritmů nabízí různé kompromisy. ZIP dobře vyvažuje kompresi a rychlost, BZIP2 poskytuje vysokou kompresi za cenu rychlosti ve srovnání s LZMA, zatímco XZ, založený na LZMA, nabízí silnou kompresi a běžně se používá v prostředí Linuxu.