LZMA-Dateiformat
So greifen Sie auf LZMA-Dateien zu, ändern, generieren, dekomprimieren und transformieren sie
LZMA-Archivdateiformat
LZMA (Lempel-Ziv-Markov-Kettenalgorithmus) ist ein moderner Datenkomprimierungsalgorithmus, der für seine hohe Effizienz und sein außergewöhnliches Komprimierungsverhältnis bekannt ist. LZMA wird häufig in Archivformaten wie
7z
verwendet und reduziert effektiv die Dateigröße, ohne die Dekomprimierungsgeschwindigkeit wesentlich zu beeinträchtigen. LZMA-Archive garantieren die Wahrung der Datenqualität und -integrität und machen sie zu einer perfekten Lösung für die effiziente Speicherung und Verwaltung großer Datenmengen.
Der Hauptvorteil von LZMA ist seine Fähigkeit, große Dateien und komplexe Datenstrukturen mit minimalem Verlust zu verarbeiten. Durch die Verwendung von LZMA können Sie den Speicherplatz optimieren und die Dateiübertragung über das Internet aufgrund einer geringeren Archivgröße erleichtern. Dies macht LZMA bei Entwicklern und Systemadministratoren zu einer beliebten Wahl für effizientes Datenmanagement.
Über LZMA-Archivinformationen
LZMA-Archive unterstützen die Parallelisierung, was eine effiziente Nutzung von Mehrkernprozessoren für eine schnellere Dateikomprimierung und -dekomprimierung ermöglicht. Darüber hinaus zeichnet sich LZMA durch seine hohe Widerstandsfähigkeit gegen Beschädigungen aus, was es zu einer zuverlässigen Wahl für die Langzeitspeicherung wichtiger Daten macht. Der Algorithmus verfügt außerdem über Open-Source-Code, was seine breite Implementierung und Anpassung in verschiedene Softwarelösungen erleichtert. Aufgrund seiner Vorteile bleibt LZMA eines der effizientesten Komprimierungsformate und bietet Benutzern weltweit eine optimale Datenverwaltung.
Entwicklung des LZMA
Der LZMA-Algorithmus, der 1998 von Igor Pavlov im Rahmen des 7-Zip-Projekts entwickelt wurde, zielte darauf ab, eine hocheffiziente Methode zur Datenkomprimierung zu schaffen. Ursprünglich basierte es auf den klassischen LZ77-Algorithmen und beinhaltete Techniken, die die Komprimierungseffizienz erheblich steigerten. Nach und nach erlangte LZMA Anerkennung für seine Fähigkeit, große Datensätze mit minimalem Ressourcenverbrauch zu verarbeiten. Im Jahr 2001 wurde LZMA zum zentralen Komprimierungsalgorithmus für das 7z-Format, das aufgrund seiner herausragenden Leistung schnell an Popularität gewann. Darüber hinaus wurde der Algorithmus in zahlreiche Archivierungs- und Datenspeichersysteme integriert, insbesondere in Open-Source-Softwareprodukte. Heute entwickelt sich LZMA weiter, behält seine Relevanz durch kontinuierliche Aktualisierungen und Optimierungen bei und festigt seine Position als unverzichtbares Werkzeug in der digitalen Welt.
Prinzipien des LZMA-Algorithmus
Der LZMA-Algorithmus basiert auf der Verwendung sequenzieller Wiederholungen in den Daten, um einen hohen Komprimierungsgrad zu erreichen. Die Hauptidee des Algorithmus besteht darin, ein Wörterbuch mit zuvor gefundenen Teilzeichenfolgen zu erstellen und zu speichern, die dann durch Referenzen in diesem Wörterbuch ersetzt werden. Dadurch können Sie die Menge der zu speichernden oder zu übertragenden Daten deutlich reduzieren. Eines der Hauptmerkmale von LZMA ist die Verwendung der Bereichskodierung anstelle der Huffman-Kodierung. Die Bereichskodierung bietet eine bessere Komprimierung näher an der Datenentropie und verwendet ein Binärformat, wodurch langsame ganzzahlige Divisionsoperationen vermieden werden.
LZMA verwendet den LZ77-Algorithmus, um die längsten Übereinstimmungen im Suchpuffer und im Vorhersagepuffer zu finden und schreibt sie in Form eines Tripletts (Abstand, Länge, nächstes Zeichen) in eine komprimierte Datei. Wenn keine Übereinstimmung gefunden wird, wird ein Byte im Bereich [0,255] an die Datei angehängt. Wenn eine Übereinstimmung gefunden wird, wird ein durch die Bereichskodierungsmethode kodiertes Wertepaar (Entfernung und Länge) aufgezeichnet.
Um die Effizienz bei einem großen Suchpuffer zu verbessern, speichert der Algorithmus die vier häufigsten Entfernungen in einem speziellen Entfernungsverlaufs-Array. Wenn eine dieser Entfernungen erneut auftritt, wird sie durch einen 2-Bit-Code ersetzt, der auf das Entfernungsverlaufs-Array verweist, wodurch die zum Speichern der Übereinstimmung erforderlichen Informationen reduziert werden.
LZMA verwendet einen 2-Byte-Hash (das aktuelle Byte und das nächste Byte), um Übereinstimmungen im Suchpuffer zu finden. Die Größe des Hash-Arrays hängt direkt von der Wörterbuchgröße ab. Beispielsweise verwendet ein 1-GB-Wörterbuch ein 512-MB-Hash-Array, wodurch Kollisionen in der Hashing-Funktion minimiert werden.
Dieser mehrstufige Ansatz ermöglicht eine effiziente Datenkomprimierung und -speicherung ohne nennenswerten Ressourcenverbrauch und macht LZMA zu einem der effizientesten Datenkomprimierungsalgorithmen.
Vorteile des .lzma-Dateiformats
Hier sind die Hauptvorteile von LZMA aufgeführt, die es für viele Datenkomprimierungsanwendungen zu einer attraktiven Wahl machen.
- Hohes Komprimierungsverhältnis: LZMA bietet eines der höchsten Komprimierungsverhältnisse unter den vorhandenen Algorithmen, wodurch Sie die Dateigröße erheblich reduzieren können. Die durchschnittliche Komprimierungsrate liegt im Vergleich zu anderen Archivformaten bei über 70 %.
- Schnelle Dekomprimierung: Der Algorithmus ist für eine schnelle Datendekomprimierung optimiert, wodurch sich LZMA gut für den Einsatz in Softwareanwendungen und Speichersystemen eignet, bei denen ein schneller Datenabruf unerlässlich ist.
- Effiziente Verwaltung großer Dateien: Aufgrund der großen Größe des Suchpuffers kann LZMA große Datenmengen effizient verarbeiten und gleichzeitig eine hohe Komprimierungsrate beibehalten.
- Zuverlässigkeit und Schadenstoleranz: LZMA bietet eine hohe Widerstandsfähigkeit gegen Datenschäden. Selbst wenn während der Speicherung oder Übertragung Fehler auftreten, ermöglicht sein Design eine gewisse Fehlerkorrektur, wodurch Datenverluste minimiert und die Integrität Ihrer Informationen während der Langzeitspeicherung sichergestellt werden.
- Offener Quellcode: Der Open-Source-Charakter des LZMA-Algorithmus erleichtert seine weit verbreitete Implementierung, Anpassung und Integration in verschiedene Softwarelösungen und fördert so seine Einführung und ständige Weiterentwicklung.
Vom LZMA-Archiv unterstützte Vorgänge
Mit Aspose.ZIP können Benutzer sowohl einzelne Dateien als auch das gesamte Archiv extrahieren. Für .NET können Sie die LzmaArchiveClass verwenden, um eine .lzma-Datei zu öffnen, dann können Sie deren Datensätze durchgehen und sie an den gewünschten Speicherort extrahieren. Ein ähnlicher Ansatz wird in Java verwendet, wo Sie LzmaArchive verwenden, um die .lzma-Datei zu öffnen und die Datensätze zu extrahieren. Dank Aspose.ZIP werden diese Vorgänge für Benutzer aller Erfahrungsstufen einfach und bequem.
LZMA-Struktur
Während es richtig ist zu sagen, dass LZMA stark von LZ77 (Lempel-Ziv 1977) und LZ78 (Lempel-Ziv 1978) beeinflusst ist, ist es präziser, LZMA als eine Weiterentwicklung dieser Algorithmen zu beschreiben, die erhebliche Verbesserungen beinhaltet.
- Bereichskodierung: LZMA ersetzt die Huffman-Kodierung durch Bereichskodierung, eine effizientere Datendarstellungsmethode.
- Entfernungsverlauf: LZMA verwaltet einen Verlauf häufig verwendeter Entfernungen und beschleunigt so die Erkennung von Übereinstimmungen.
- Hash-Tabelle: LZMA verwendet eine Hash-Tabelle, um die Suche nach passenden Sequenzen zu beschleunigen.
- Prädiktive Modellierung: LZMA integriert prädiktive Modellierungstechniken, um bevorstehende Datenmuster zu antizipieren und so die Komprimierung weiter zu verbessern.
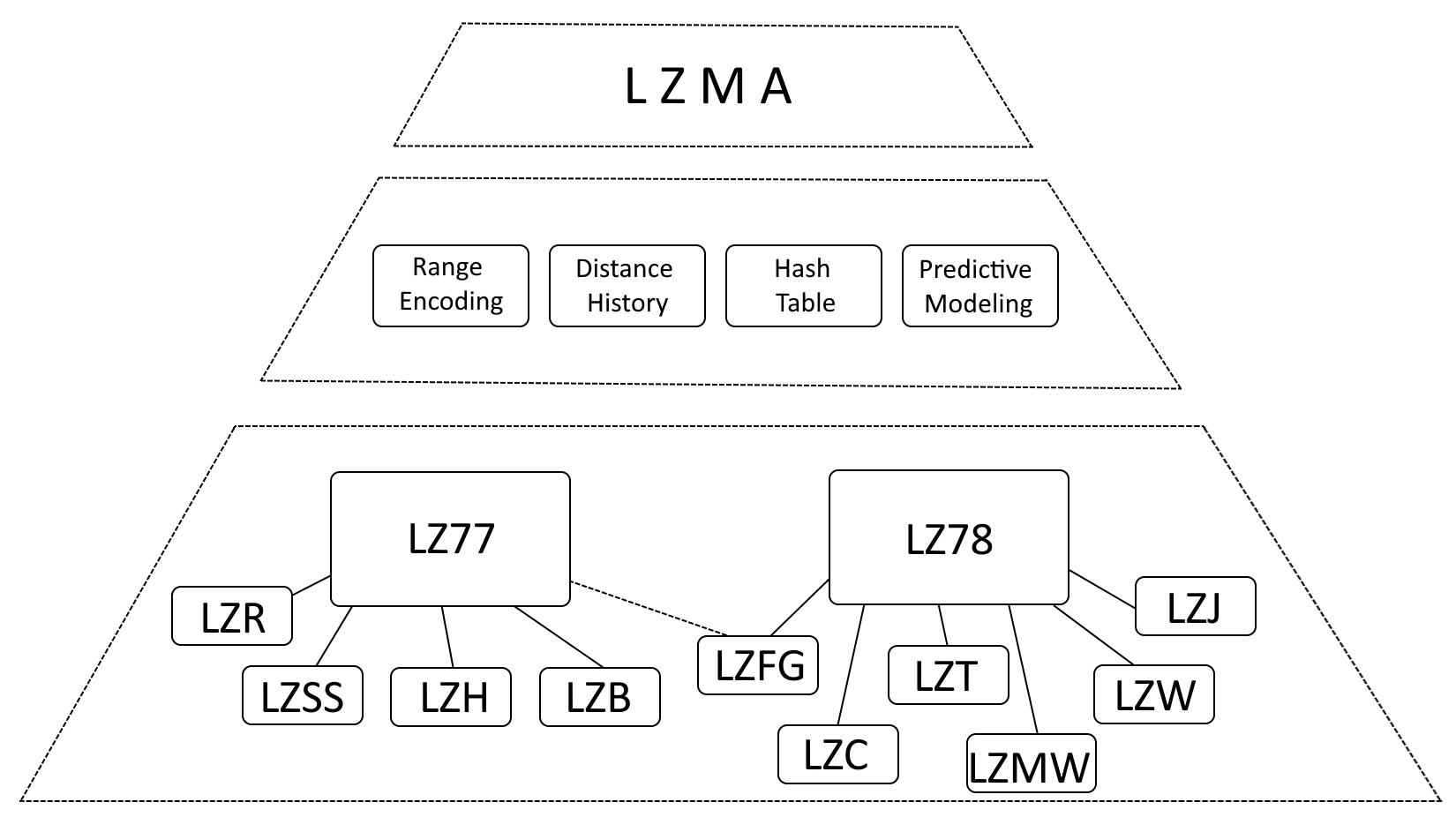
Innere LZMA-Archivstruktur
- Dateimetadaten – Ähnlich wie bei einem TAR-Archiv speichert jede Datei grundlegende Informationen wie Änderungszeit und Berechtigungen. Dieser Abschnitt ist jedoch flexibel und ermöglicht je nach Bedarf das Weglassen oder Einfügen zusätzlicher Details wie Zugriffskontrolllisten (ACLs) oder erweiterter Attribute (EAs). Es wird empfohlen, eine starke Hash-Funktion (wie SHA1) für reguläre Dateien einzuschließen, um die Datenintegrität sicherzustellen.
- Mehrere Inhaltsströme – Im Gegensatz zu herkömmlichen Archiven können Dateien mehr als einen Datenstrom innerhalb der inneren Datendatei haben. Dies ist nützlich zum Speichern erweiterter Attribute oder Ressourcenzweige, die mit der Datei verknüpft sind.
- Header – Die innere Indexdatei enthält Dateiheader und spiegelt die in der inneren Datendatei verstreuten Header wider. Bei separater Speicherung müssen die Indexheader jedoch auf die Startposition der entsprechenden Daten innerhalb der Datendatei verweisen. Darüber hinaus listen Verzeichniseinträge im Index ihre enthaltenen Dateien und ihre entsprechenden Offsets innerhalb des inneren Dateiindex auf.
- Begründung für doppelte Metadaten – Diese Designwahl gewährleistet sowohl effizientes Daten-Streaming/-Dekodierung als auch zufälligen Dateizugriff. Darüber hinaus lassen sich Metadaten gut komprimieren, was zu einem minimalen Speicheraufwand führt. Tests zeigen, dass Metadaten normalerweise weniger als 0,3 % des Speicherplatzes belegen, sodass sich der Kompromiss lohnt.
- Blockheader – Blockheader enthalten, ähnlich wie die äußere Datei, Informationen zur Blockgröße und eine eindeutige Kennungssequenz.
Beispiele für die Verwendung von LZMA Python
Mit der API Aspose.ZIP via Python können Sie LZMA-Archive in Ihren Anwendungen einfach verwalten, sodass keine andere externe Software erforderlich ist. Die API umfasst die LzmaArchive-Klasse , die die Arbeit mit LZMA-Archiven vereinfacht, und die LzmaCompressionSettings-Klasse , mit dem Sie die Komprimierungseinstellungen für optimale Leistung und Reduzierung der Dateigröße anpassen können.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Zusätzliche Informationen zu den LZMA-Archiven
Die Leute haben gefragt
1. Welche Dateiformate verwenden die LZMA-Komprimierung?
LZMA ist kein Dateiformat selbst, sondern ein Komprimierungsalgorithmus, der in verschiedenen Archivformaten verwendet wird. Einige gängige Beispiele sind 7z, XZ und gelegentlich ZIP. Wenn Sie auf eine Datei mit diesen Erweiterungen stoßen, ist sie möglicherweise mit LZM komprimiert
2. Ist LZMA Open Source?
Ja, LZMA ist ein Open-Source-Algorithmus, der zur Nutzung und Integration in verschiedene Softwarelösungen frei verfügbar ist. Dieser Open-Source-Charakter hat zu seiner breiten Akzeptanz und kontinuierlichen Weiterentwicklung beigetragen.
3. Welche Alternativen gibt es zu LZMA?
Mehrere Komprimierungsalgorithmen bieten unterschiedliche Kompromisse. ZIP bietet ein gutes Gleichgewicht zwischen Komprimierung und Geschwindigkeit, BZIP2 bietet im Vergleich zu LZMA eine hohe Komprimierung auf Kosten der Geschwindigkeit, während XZ, basierend auf LZMA, eine starke Komprimierung bietet und häufig in Linux-Umgebungen verwendet wird.