Formato de archivo LZMA
Cómo acceder, modificar, generar, descomprimir y transformar archivos LZMA
Formato de archivo de archivo LZMA
LZMA (algoritmo de cadena Lempel-Ziv-Markov) es un algoritmo de compresión de datos moderno conocido por su alta eficiencia y su excepcional relación de compresión. Ampliamente utilizado en formatos de archivo como
7z
, LZMA reduce efectivamente el tamaño del archivo sin un sacrificio significativo en la velocidad de descompresión. Los archivos LZMA garantizan la preservación de la calidad e integridad de los datos, lo que los convierte en una solución perfecta para almacenar y administrar grandes conjuntos de datos de manera eficiente.
La principal ventaja de LZMA es su capacidad para manejar archivos grandes y estructuras de datos complejas con una pérdida mínima. El uso de LZMA le permite optimizar el espacio en disco y facilita la transferencia de archivos a través de Internet debido a un tamaño de archivo más pequeño. Esto convierte a LZMA en una opción popular entre los desarrolladores y administradores de sistemas para una gestión de datos eficiente.
Acerca de la información del archivo LZMA
Los archivos LZMA admiten la paralelización, lo que permite un uso eficiente de procesadores multinúcleo para una compresión y descompresión de archivos más rápida. Además, LZMA destaca por su alta resistencia a los daños, lo que lo convierte en una opción confiable para el almacenamiento a largo plazo de datos importantes. El algoritmo también cuenta con código fuente abierto, lo que facilita su amplia implementación y adaptación en diversas soluciones de software. Debido a sus ventajas, LZMA sigue siendo uno de los formatos de compresión más eficientes y proporciona una gestión de datos óptima para usuarios de todo el mundo.
Evolución de la LZMA
El algoritmo LZMA, desarrollado por Igor Pavlov en 1998 como parte del proyecto 7-Zip, tenía como objetivo crear un método de compresión de datos altamente eficiente. Inicialmente, se basó en los algoritmos clásicos LZ77, incorporando técnicas que aumentaron significativamente la eficiencia de la compresión. Poco a poco, LZMA fue ganando reconocimiento por su capacidad para procesar grandes conjuntos de datos con un consumo mínimo de recursos. En 2001, LZMA se convirtió en el algoritmo de compresión central para el formato 7z, que rápidamente ganó popularidad debido a su excelente rendimiento. Además, el algoritmo se ha integrado en numerosos archivadores y sistemas de almacenamiento de datos, especialmente en productos de software de código abierto. Hoy, LZMA continúa evolucionando, manteniendo su relevancia a través de continuas actualizaciones y optimizaciones, solidificando su posición como una herramienta indispensable en el mundo digital.
Principios del algoritmo LZMA
El algoritmo LZMA se basa en el uso de repeticiones secuenciales en los datos para conseguir un alto grado de compresión. La idea principal del algoritmo es construir y almacenar un diccionario que contenga subcadenas encontradas anteriormente, que luego se reemplazan por referencias en este diccionario. Esto le permite reducir significativamente la cantidad de datos que se almacenarán o transmitirán. Una de las características clave de LZMA es el uso de codificación de rango en lugar de codificación Huffman. La codificación de rango ofrece una mejor compresión más cercana a la entropía de los datos y utiliza un formato binario, evitando operaciones lentas de división de enteros.
LZMA utiliza el algoritmo LZ77 para encontrar las coincidencias más largas en el búfer de búsqueda y el búfer de predicción, escribiéndolas en un archivo comprimido en forma de triplete (distancia, longitud, siguiente carácter). Si no se encuentra ninguna coincidencia, se agrega al archivo un byte en el rango [0,255]. Si se encuentra una coincidencia, se registra un par de valores (distancia y longitud) codificados mediante el método de codificación de rango.
Para mejorar la eficiencia con un búfer de búsqueda grande, el algoritmo almacena las 4 distancias más comunes en una matriz de historial de distancias dedicada. Si alguna de estas distancias reaparece, se reemplaza con un código de 2 bits que hace referencia a la matriz del historial de distancias, lo que reduce la información necesaria para almacenar la coincidencia.
LZMA utiliza un hash de 2 bytes (el byte actual y el siguiente byte) para encontrar coincidencias en el búfer de búsqueda. El tamaño de la matriz hash está directamente relacionado con el tamaño del diccionario. Por ejemplo, un diccionario de 1 GB utiliza una matriz hash de 512 MB, lo que minimiza las colisiones en la función hash.
Este enfoque multinivel proporciona compresión y almacenamiento de datos eficientes sin un consumo significativo de recursos, lo que convierte a LZMA en uno de los algoritmos de compresión de datos más eficientes.
Beneficios del formato de archivo .lzma
Estas son las principales ventajas de LZMA, lo que lo convierte en una opción atractiva para muchas aplicaciones de compresión de datos.
- Alta relación de compresión: LZMA proporciona una de las relaciones de compresión más altas entre los algoritmos existentes, lo que le permite reducir significativamente el tamaño de los archivos. Los índices de compresión promedio superan el 70% en comparación con otros formatos de archivo.
- Descompresión rápida: El algoritmo está optimizado para una descompresión rápida de datos, lo que hace que LZMA sea ideal para su uso en aplicaciones de software y sistemas de almacenamiento donde la recuperación rápida de datos es esencial.
- Gestión eficiente de archivos grandes: Debido al gran tamaño del búfer de búsqueda, LZMA puede procesar eficientemente grandes cantidades de datos manteniendo una alta tasa de compresión.
- Confiabilidad y tolerancia al daño: LZMA proporciona una alta resistencia al daño de los datos. Incluso si se producen errores durante el almacenamiento o la transmisión, su diseño permite cierta corrección de errores, minimizando la pérdida de datos y garantizando la integridad de su información durante el almacenamiento a largo plazo.
- Código fuente abierto: La naturaleza de código abierto del algoritmo LZMA facilita su implementación, adaptación e integración generalizada en diversas soluciones de software, promoviendo su adopción y desarrollo continuo.
Operaciones compatibles con el archivo LZMA
Aspose.ZIP permite a los usuarios extraer tanto archivos individuales como el archivo completo. Para .NET, puede usar LzmaArchiveClass para abrir un archivo .lzma, luego puede recorrer sus registros y extraerlos a la ubicación deseada. En Java se utiliza un enfoque similar, donde se utiliza LzmaArchive para abrir el archivo .lzma y extraer los registros. Gracias a Aspose.ZIP, estas operaciones se vuelven simples y convenientes para usuarios de cualquier nivel.
estructura LZMA
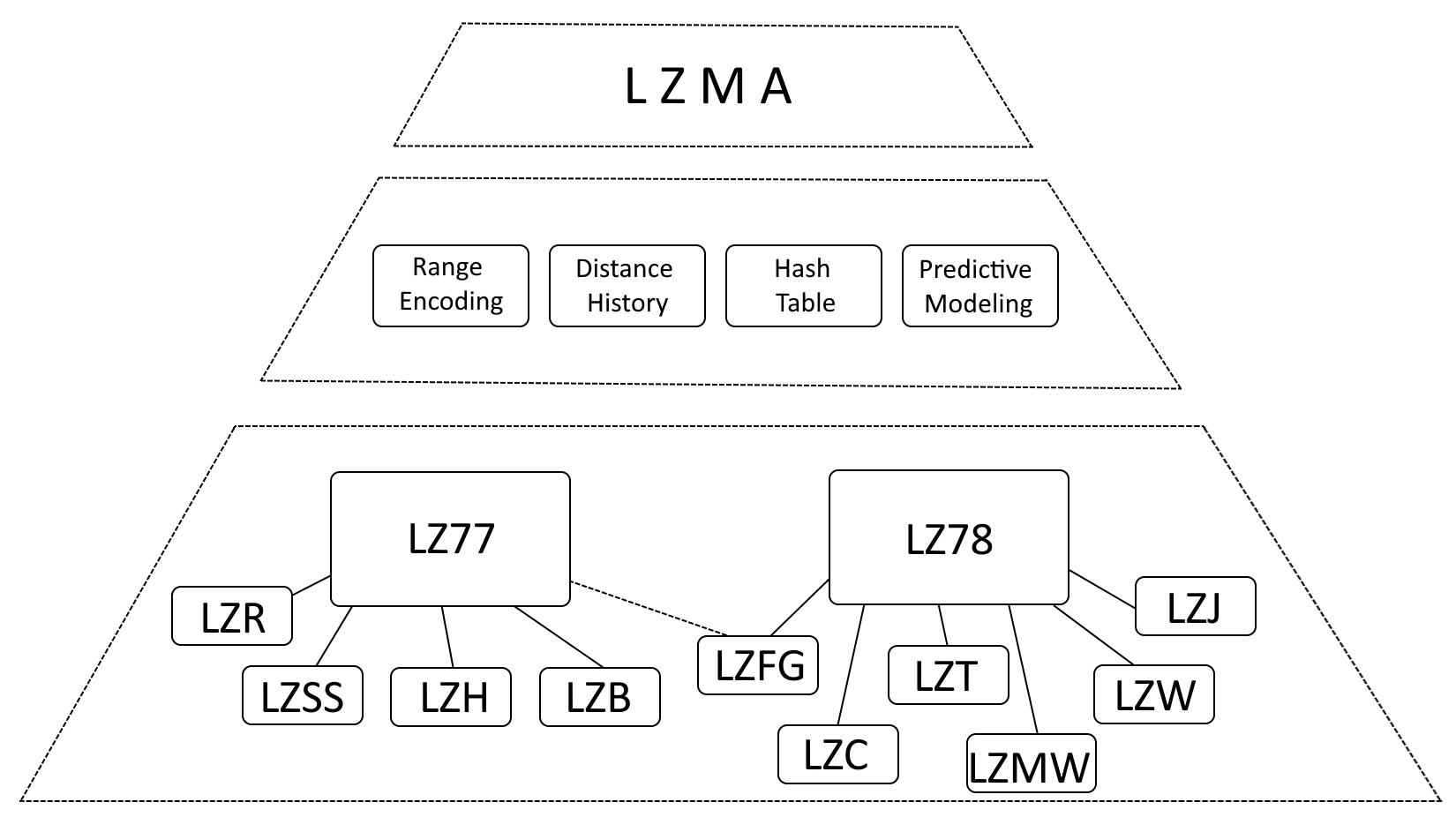
Si bien es exacto decir que LZMA está fuertemente influenciado por LZ77 (Lempel-Ziv 1977) y LZ78 (Lempel-Ziv 1978), es más preciso describir LZMA como una evolución de estos algoritmos, incorporando mejoras significativas.
- Codificación de rango: LZMA reemplaza la codificación de Huffman con codificación de rango, un método de representación de datos más eficiente.
- Historial de distancias: LZMA mantiene un historial de distancias utilizadas con frecuencia, lo que acelera la detección de coincidencias.
- Tabla hash: LZMA emplea una tabla hash para acelerar la búsqueda de secuencias coincidentes.
- Modelado predictivo: LZMA incorpora técnicas de modelado predictivo para anticipar patrones de datos futuros, mejorando aún más la compresión.
Estructura de archivo interior LZMA
- Metadatos de archivo: similar a un archivo tar, cada archivo almacena información básica como la hora de modificación y los permisos. Sin embargo, esta sección es flexible y permite omitir o incluir detalles adicionales como listas de control de acceso (ACL) o atributos extendidos (EA) según sus necesidades. Se recomienda incluir una función hash sólida (como SHA1) para archivos normales para garantizar la integridad de los datos.
- Múltiples flujos de contenido: a diferencia de los archivos tradicionales, los archivos pueden tener más de un flujo de datos dentro del archivo de datos interno. Esto es útil para almacenar atributos extendidos o bifurcaciones de recursos asociados con el archivo.
- Encabezados: el archivo de índice interno contiene encabezados de archivo, reflejando los que se encuentran dispersos por el archivo de datos interno. Pero, cuando se almacenan por separado, los encabezados de índice deben hacer referencia a la posición inicial de sus datos correspondientes dentro del archivo de datos. Además, las entradas del directorio en el índice enumeran los archivos que contienen y sus desplazamientos correspondientes dentro del índice del archivo interno.
- Justificación de los metadatos duplicados: esta elección de diseño garantiza una transmisión/decodificación de datos eficiente y un acceso aleatorio a los archivos. Además, los metadatos se comprimen bien, lo que resulta en una sobrecarga de almacenamiento mínima. Las pruebas muestran que los metadatos normalmente ocupan menos del 0,3 % del espacio de almacenamiento, lo que hace que la compensación valga la pena.
- Encabezados de bloque: los encabezados de bloque, similares al archivo externo, contienen información sobre el tamaño del bloque y una secuencia de identificador única.
Ejemplos de uso de LZMA Python
Con la API Aspose.ZIP vía Python , puede administrar fácilmente archivos LZMA en sus aplicaciones, eliminando la necesidad de otro software externo. La API incluye la clase LzmaArchive , que simplifica el trabajo con archivos LZMA, y la clase LzmaCompressionSettings , que le permite personalizar la configuración de compresión para un rendimiento óptimo y una reducción del tamaño del archivo.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Información adicional sobre los archivos LZMA
La gente ha estado preguntando
1. ¿Qué formatos de archivo utilizan la compresión LZMA?
LZMA no es un formato de archivo en sí, sino un algoritmo de compresión utilizado en varios formatos de archivo. Algunos ejemplos comunes incluyen 7z, XZ y ocasionalmente ZIP. Cuando encuentre un archivo con estas extensiones, es posible que esté comprimido usando LZM
2. ¿LZMA es de código abierto?
Sí, LZMA es un algoritmo de código abierto, lo que lo hace disponible gratuitamente para su uso e integración en diversas soluciones de software. Esta naturaleza de código abierto ha contribuido a su adopción generalizada y a su desarrollo continuo.
3. ¿Cuáles son algunas alternativas a LZMA?
Varios algoritmos de compresión ofrecen diferentes compensaciones. ZIP equilibra bien la compresión y la velocidad, BZIP2 proporciona una alta compresión a costa de la velocidad en comparación con LZMA, mientras que XZ, basado en LZMA, ofrece una fuerte compresión y se usa comúnmente en entornos Linux.