Format de fichier LZMA
Comment accéder, modifier, générer, décompresser et transformer les fichiers LZMA
Format de fichier d'archive LZMA
LZMA (algorithme de chaîne de Lempel-Ziv-Markov) est un algorithme de compression de données moderne réputé pour sa haute efficacité et son taux de compression exceptionnel. Largement utilisé dans les formats d’archives tels que
7z
, LZMA réduit efficacement la taille des fichiers sans sacrifier de manière significative la vitesse de décompression. Les archives LZMA garantissent la préservation de la qualité et de l’intégrité des données, ce qui en fait une solution parfaite pour stocker et gérer efficacement de grands ensembles de données.
Le principal avantage de LZMA est sa capacité à gérer des fichiers volumineux et des structures de données complexes avec une perte minimale. L’utilisation de LZMA vous permet d’optimiser l’espace disque et facilite le transfert de fichiers sur Internet grâce à une taille d’archive plus petite. Cela fait de LZMA un choix populaire parmi les développeurs et les administrateurs système pour une gestion efficace des données.
À propos des informations sur les archives LZMA
Les archives LZMA prennent en charge la parallélisation, ce qui permet une utilisation efficace des processeurs multicœurs pour une compression et une décompression plus rapides des fichiers. De plus, LZMA se distingue par sa haute résistance aux dommages, ce qui en fait un choix fiable pour le stockage à long terme de données importantes. L’algorithme dispose également d’un code open source, ce qui facilite sa large mise en œuvre et son adaptation dans diverses solutions logicielles. Grâce à ses avantages, LZMA reste l’un des formats de compression les plus efficaces, offrant une gestion optimale des données aux utilisateurs du monde entier.
Évolution du LZMA
L’algorithme LZMA, développé par Igor Pavlov en 1998 dans le cadre du projet 7-Zip, visait à créer une méthode de compression de données très efficace. Initialement, il s’appuyait sur les algorithmes classiques du LZ77, incorporant des techniques qui augmentaient considérablement l’efficacité de la compression. Peu à peu, LZMA a été reconnu pour sa capacité à traiter de grands ensembles de données avec une consommation de ressources minimale. En 2001, LZMA est devenu l’algorithme de compression principal du format 7z, qui a rapidement gagné en popularité en raison de ses performances exceptionnelles. De plus, l’algorithme a été intégré dans de nombreux archiveurs et systèmes de stockage de données, notamment des produits logiciels open source. Aujourd’hui, LZMA continue d’évoluer, maintenant sa pertinence grâce à des mises à jour et des optimisations continues, renforçant ainsi sa position d’outil indispensable dans le monde numérique.
Principes de l'algorithme LZMA
L’algorithme LZMA est basé sur l’utilisation de répétitions séquentielles dans les données pour atteindre un degré élevé de compression. L’idée principale de l’algorithme est de construire et de stocker un dictionnaire contenant des sous-chaînes précédemment rencontrées, qui sont ensuite remplacées par des références dans ce dictionnaire. Cela vous permet de réduire considérablement la quantité de données à stocker ou à transmettre. L’une des principales caractéristiques de LZMA est son utilisation du codage par plage au lieu du codage de Huffman. Le codage par plage offre une meilleure compression, plus proche de l’entropie des données et utilise un format binaire, évitant ainsi les opérations lentes de division d’entiers.
LZMA utilise l’algorithme LZ77 pour trouver les correspondances les plus longues dans le tampon de recherche et le tampon de prédiction, en les écrivant dans un fichier compressé sous la forme d’un triplet (distance, longueur, caractère suivant). Si aucune correspondance n’est trouvée, un octet dans la plage [0,255] est ajouté au fichier. Si une correspondance est trouvée, une paire de valeurs (distance et longueur) codées par la méthode de codage de plage est enregistrée.
Pour améliorer l’efficacité avec un grand tampon de recherche, l’algorithme stocke les 4 distances les plus courantes dans un tableau d’historique de distance dédié. Si l’une de ces distances réapparaît, elle est remplacée par un code à 2 bits faisant référence au tableau d’historique des distances, réduisant ainsi les informations nécessaires au stockage de la correspondance.
LZMA utilise un hachage de 2 octets (l’octet actuel et l’octet suivant) pour trouver des correspondances dans le tampon de recherche. La taille du tableau de hachage est directement liée à la taille du dictionnaire. Par exemple, un dictionnaire de 1 Go utilise un tableau de hachage de 512 Mo, ce qui minimise les collisions dans la fonction de hachage.
Cette approche multi-niveaux fournit une compression et un stockage efficaces des données sans consommation significative de ressources, faisant de LZMA l’un des algorithmes de compression de données les plus efficaces.
Avantages du format de fichier .lzma
Voici les principaux avantages de LZMA, qui en font un choix attractif pour de nombreuses applications de compression de données.
- Taux de compression élevé: LZMA fournit l’un des taux de compression les plus élevés parmi les algorithmes existants, ce qui vous permet de réduire considérablement la taille des fichiers. Les taux de compression moyens dépassent 70 % par rapport aux autres formats d’archives.
- Décompression rapide: L’algorithme est optimisé pour une décompression rapide des données, ce qui rend LZMA bien adapté à une utilisation dans les applications logicielles et les systèmes de stockage où une récupération rapide des données est essentielle.
- Gestion efficace des fichiers volumineux: En raison de la grande taille du tampon de recherche, LZMA peut traiter efficacement de grandes quantités de données tout en maintenant un taux de compression élevé.
- Fiabilité et tolérance aux dommages: LZMA offre une haute résistance aux dommages aux données. Même si des erreurs se produisent pendant le stockage ou la transmission, sa conception permet une certaine correction des erreurs, minimisant ainsi la perte de données et garantissant l’intégrité de vos informations pendant le stockage à long terme.
- Code open source: La nature open source de l’algorithme LZMA facilite sa mise en œuvre, son adaptation et son intégration généralisées dans diverses solutions logicielles, favorisant son adoption et son développement continu.
Opérations prises en charge par les archives LZMA
Aspose.ZIP permet aux utilisateurs d’extraire à la fois des fichiers individuels et l’intégralité de l’archive. Pour .NET, vous pouvez utiliser LzmaArchiveClass pour ouvrir un fichier .lzma, puis parcourir ses enregistrements et les extraire à l’emplacement souhaité. Une approche similaire est utilisée en Java, où vous utilisez LzmaArchive pour ouvrir le fichier .lzma et extraire les enregistrements. Grâce à Aspose.ZIP, ces opérations deviennent simples et pratiques pour les utilisateurs de tout niveau.
Structure du LZMA
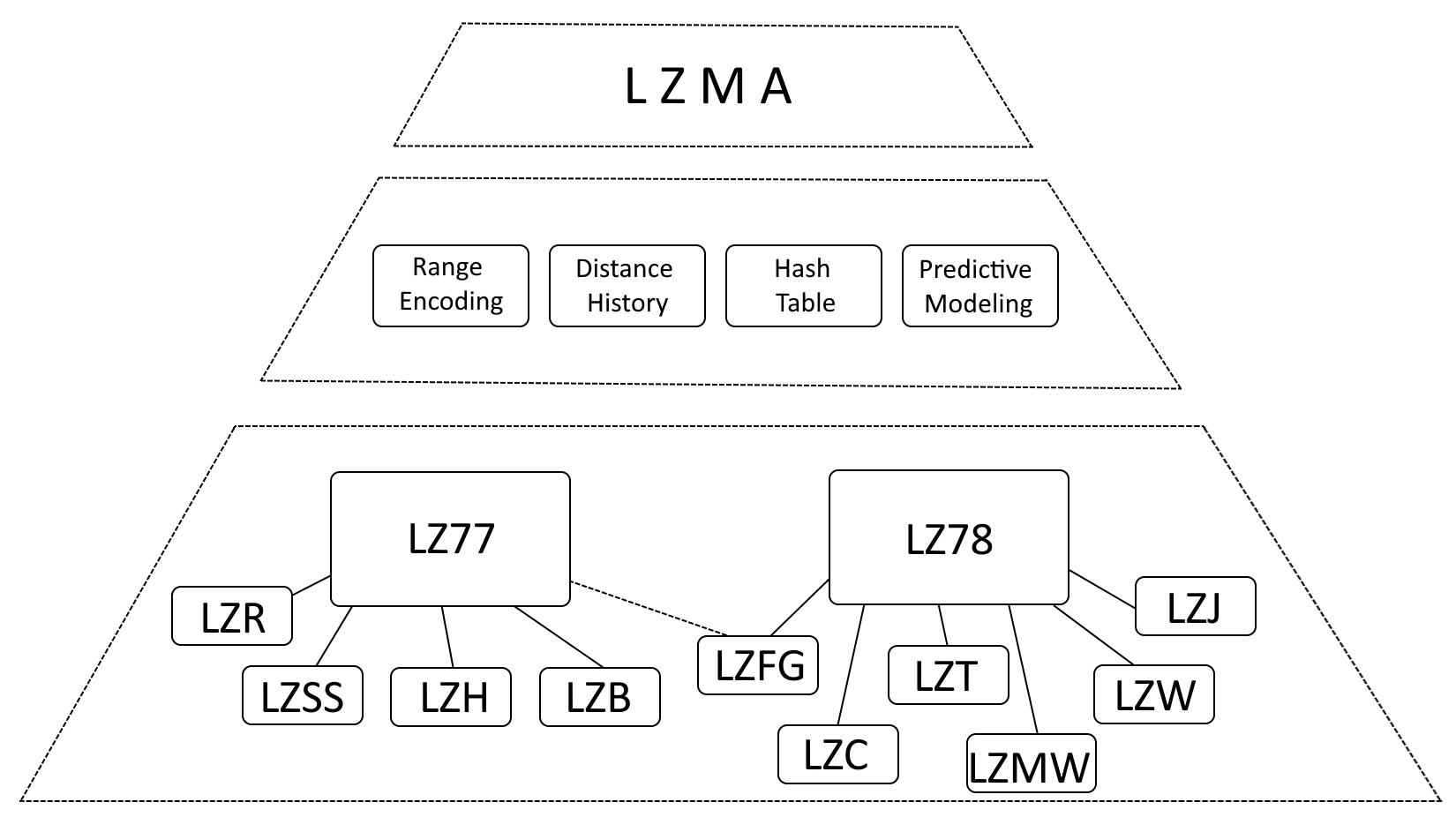
S’il est exact de dire que LZMA est fortement influencé par LZ77 (Lempel-Ziv 1977) et LZ78 (Lempel-Ziv 1978), il est plus précis de décrire LZMA comme une évolution de ces algorithmes, incorporant des améliorations significatives.
- Range Encoding: LZMA remplace le codage de Huffman par le range encoding, une méthode de représentation des données plus efficace.
- Historique des distances: LZMA conserve un historique des distances fréquemment utilisées, accélérant ainsi la détection des correspondances.
- Table de hachage: LZMA utilise une table de hachage pour accélérer la recherche de séquences correspondantes.
- Modélisation prédictive: LZMA intègre des techniques de modélisation prédictive pour anticiper les modèles de données à venir, améliorant ainsi encore la compression.
Structure d'archive interne LZMA
- Métadonnées de fichier - Semblable à une archive tar, chaque fichier stocke des informations de base telles que l’heure de modification et les autorisations. Cependant, cette section est flexible et permet d’omettre ou d’inclure des détails supplémentaires tels que des listes de contrôle d’accès (ACL) ou des attributs étendus (EA) en fonction de vos besoins. Il est recommandé d’inclure une fonction de hachage puissante (comme SHA1) pour les fichiers normaux afin de garantir l’intégrité des données.
- Flux de contenu multiples - Contrairement aux archives traditionnelles, les fichiers peuvent contenir plusieurs flux de données dans le fichier de données interne. Ceci est utile pour stocker les attributs étendus ou les branches de ressources associées au fichier.
- En-têtes - Le fichier d’index interne contient les en-têtes de fichiers, reflétant ceux dispersés dans le fichier de données interne. Mais, lorsqu’ils sont stockés séparément, les en-têtes d’index doivent faire référence à la position de départ de leurs données correspondantes dans le fichier de données. De plus, les entrées de répertoire dans l’index répertorient les fichiers contenus et leurs décalages correspondants dans l’index de fichier interne.
- Justification des métadonnées en double - Ce choix de conception garantit à la fois un streaming/décodage efficace des données et un accès aléatoire aux fichiers. De plus, les métadonnées se compressent bien, ce qui entraîne une surcharge de stockage minimale. Les tests montrent que les métadonnées occupent généralement moins de 0,3 % de l’espace de stockage, ce qui rend le compromis intéressant.
- En-têtes de bloc - Les en-têtes de bloc, similaires au fichier externe, contiennent des informations sur la taille du bloc et une séquence d’identifiants unique.
Exemples d'utilisation de LZMA Python
Avec l’API Aspose.ZIP via Python , vous pouvez facilement gérer les archives LZMA dans vos applications, éliminant ainsi le besoin d’autres logiciels externes. L’API comprend la classe LzmaArchive , qui simplifie le travail avec les archives LZMA, et la classe LzmaCompressionSettings , qui vous permet de personnaliser les paramètres de compression pour des performances optimales et une réduction de la taille des fichiers.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Informations supplémentaires sur les archives LZMA
Les gens ont demandé
1. Quels formats de fichiers utilisent la compression LZMA ?
LZMA n’est pas un format de fichier en soi mais un algorithme de compression utilisé dans différents formats d’archives. Quelques exemples courants incluent 7z, XZ et parfois ZIP. Lorsque vous rencontrez un fichier avec ces extensions, il peut être compressé à l’aide de LZM
2. LZMA est-il open source ?
Oui, LZMA est un algorithme open source, ce qui le rend librement disponible pour utilisation et intégration dans diverses solutions logicielles. Cette nature open source a contribué à son adoption généralisée et à son développement continu.
3. Quelles sont les alternatives à LZMA ?
Plusieurs algorithmes de compression proposent différents compromis. ZIP équilibre bien compression et vitesse, BZIP2 offre une compression élevée au détriment de la vitesse par rapport à LZMA, tandis que XZ, basé sur LZMA, offre une forte compression et est couramment utilisé dans les environnements Linux.