Format de fichier Z
Principales fonctionnalités du fichier Z - Comment ouvrir, compresser, extraire et gérer les archives Z
Format d'archive Z
Le format de fichier Z est un format de compression hérité largement utilisé sur les systèmes UNIX dans les années 1980 et 1990. Il utilise l’algorithme Lempel-Ziv-Welch (LZW) pour compresser les fichiers, réduisant ainsi considérablement leur taille tout en préservant l’intégrité des données. Bien que largement supplantés par des formats plus modernes comme gzip et bzip2, les fichiers Z sont toujours présents dans les systèmes et archives existants.
Informations générales sur les archives Z
Les archives Z sont un format de compression de fichiers existant principalement utilisé sur les systèmes UNIX et les premiers systèmes Linux. Ils utilisent l’algorithme Lempel-Ziv-Welch (LZW), qui était une méthode révolutionnaire de compression de données lors de son introduction. Le format Z est conçu pour réduire la taille des fichiers en codant efficacement les modèles de données répétitifs, ce qui le rend utile pour économiser l’espace disque et la bande passante à l’ère des capacités de stockage limitées. Les archives Z compressent généralement des fichiers individuels plutôt que des répertoires entiers, bien qu’elles puissent être combinées avec des outils tels que tar pour archiver et compresser plusieurs fichiers à la fois. Bien que le format Z ait été largement remplacé par des méthodes de compression plus modernes, il reste une partie importante de l’histoire de l’informatique et est encore présent dans certaines archives logicielles plus anciennes et dans les systèmes basés sur UNIX.
Informations sur l'historique des archives Z
- Années 1980: Le format Z a été développé au début d’UNIX comme moyen de compresser efficacement des fichiers et d’économiser de l’espace de stockage, qui était à l’époque une ressource précieuse.
- 1983: L’utilitaire de compression, qui crée des archives Z, est introduit dans le système d’exploitation UNIX. Il est rapidement devenu un outil standard pour la compression de fichiers dans les environnements UNIX.
- Fin des années 1980: à mesure que les systèmes UNIX se généralisaient, le format Z a été largement utilisé dans la distribution de logiciels, en particulier pour l’envoi et le stockage de fichiers volumineux sur des réseaux.
- Années 1990: L’introduction de formats de compression plus avancés comme gzip et bzip2 ont commencé à supplanter le format Z en raison de leurs taux de compression plus élevés et de leurs fonctionnalités supplémentaires.
- Années 2000: Même si le format Z est tombé en disgrâce pour la plupart des applications modernes, il a continué à être pris en charge dans les systèmes UNIX et Linux pour une compatibilité ascendante avec les logiciels plus anciens.
- Présent: Bien que largement obsolète, le format Z est encore rencontré dans les systèmes existants et dans certains cas d’utilisation spécifiques où la compatibilité avec les anciens outils UNIX est requise.
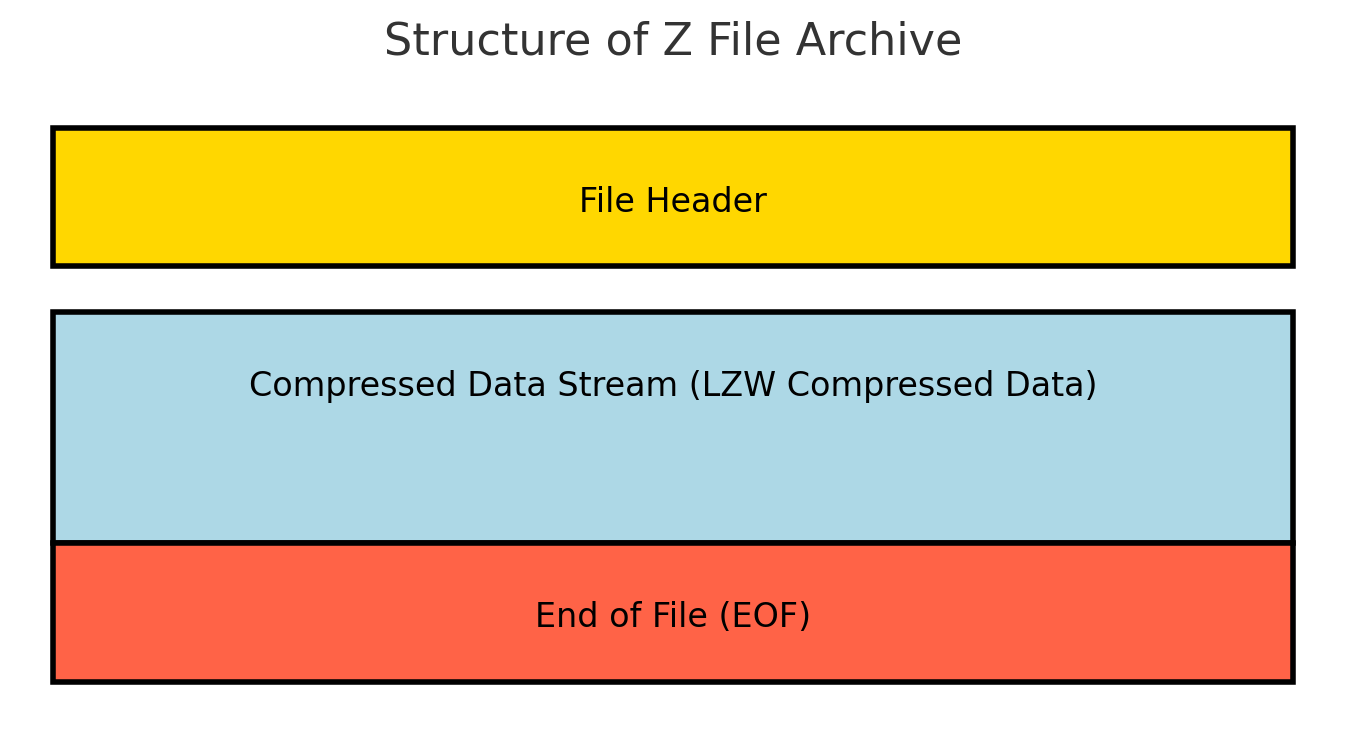
Structure de l'archive Z
Le format d’archive Z est relativement simple comparé aux formats de compression plus modernes. Il a été conçu pour la compression d’un seul fichier et ne dispose pas de certaines des fonctionnalités avancées des formats plus récents. Voici un aperçu de la structure d’une archive Z:
- En-tête: L’en-tête d’une archive Z contient des métadonnées de base, y compris un nombre magique (0x1f9d) qui identifie le fichier en tant qu’archive Z. Il peut également inclure des indicateurs de contrôle qui dictent les paramètres de compression, bien que ceux-ci soient minimes par rapport aux formats modernes.
- Flux de données compressé: Le composant principal de l’archive Z est le flux de données compressé, où les données du fichier sont stockées après avoir été traitées par l’algorithme de compression LZW (Lempel-Ziv-Welch). Les données sont compressées en un seul flux continu, ce qui signifie que l’intégralité du fichier doit être décompressée pour accéder à n’importe quelle partie des données.
- Marqueur de fin de fichier (EOF): Le format Z n’a pas de pied de page formel comme certains autres formats. Au lieu de cela, la fin du flux de données compressé marque la conclusion de l’archive. Il n’y a pas de somme de contrôle intégrée ni de fonctionnalités de vérification d’intégrité dans le format Z de base.
Méthodes de compression Z
Le format Z repose uniquement sur l’algorithme de compression LZW (Lempel-Ziv-Welch). Cette méthode était innovante pour l’époque et se distingue par son équilibre entre simplicité et efficacité. Voici un aperçu plus approfondi de la méthode de compression utilisée dans les archives Z:
- Compression LZW: L’algorithme LZW est une technique de compression basée sur un dictionnaire qui remplace les séquences de données répétitives par des codes plus courts, réduisant ainsi la taille globale du fichier. Il s’agit d’une méthode de compression sans perte, ce qui signifie que les données originales peuvent être parfaitement reconstruites à partir du fichier compressé. LZW est devenu populaire au début de la compression de fichiers en raison de ses vitesses de compression et de décompression relativement rapides.
- Aucun filtre ou méthode supplémentaire: Contrairement aux formats de compression modernes qui peuvent prendre en charge divers filtres et méthodes de compression supplémentaires, le format Z utilise uniquement LZW sans filtres ni améliorations facultatifs. Cette simplicité est à la fois une force et une limite, car elle rend le format facile à mettre en œuvre mais moins flexible et efficace par rapport aux formats plus récents.
- Aucun contrôle d’intégrité: Le format Z n’inclut pas de mécanismes de somme de contrôle intégrés comme CRC32 ou SHA-256 pour vérifier l’intégrité des données. Par conséquent, la détection de corruption au sein d’une archive Z est plus difficile et s’appuie plutôt sur des méthodes externes ou sur le comportement du processus de décompression.
Opérations prises en charge par l'extension .Z
Aspose.ZIP offre une prise en charge complète pour travailler avec les archives Z, couramment utilisées dans les systèmes d’exploitation de type Unix. Cette fonctionnalité simplifie la gestion et la manipulation des fichiers compressés au sein de vos applications. Voici comment Aspose.ZIP vous permet:
- Archives d’extraction Z: Extrayez facilement tout le contenu d’une archive .z. Aspose.ZIP garantit que l’intégrité et la structure originale de vos données sont maintenues pendant le processus d’extraction.
- Extraction sélective précise: Ciblez des fichiers spécifiques dans une archive .z pour l’extraction. Cela vous permet de récupérer des données de manière sélective en fonction des noms de fichiers ou d’autres critères, optimisant ainsi votre flux de travail et gagnant du temps.
- Compression simplifiée: Créez des archives Z à partir de fichiers et de répertoires directement dans vos applications. Aspose.ZIP utilise la méthode de compression efficace LZMA2 pour réduire considérablement la taille des fichiers, économisant ainsi un espace de stockage précieux. Tirez parti de cette fonctionnalité pour archiver des données, des sauvegardes ou une transmission efficace de fichiers.
- Options de personnalisation: Affinez votre processus de compression en ajustant les niveaux de compression et d’autres paramètres. Aspose.ZIP vous permet de trouver un équilibre entre la vitesse de compression et la taille du fichier obtenu. Vous pouvez adapter le processus pour l’optimiser pour une compression plus rapide ou obtenir une compression maximale pour des besoins spécifiques.
Structure de l'archive de fichiers Z
Le format de fichier .Z, une méthode de compression héritée, est structuré pour fournir une compression basique et efficace à l’aide de l’algorithme LZW. Bien que plus simple que moderne comme les formats .xz , la structure de fichier Z reste cruciale pour comprendre comment les données étaient traitées dans les premiers systèmes UNIX. Voici un aperçu de la structure d’une archive .Z:
- En-tête du fichier:
- Magic Bytes: Le fichier commence par un nombre magique (0x1f9d), qui l’identifie comme un fichier compressé .Z. Ceci est crucial pour reconnaître le type de fichier lors de la décompression.
- Indicateurs: l’en-tête peut inclure des indicateurs de base qui déterminent la manière dont la compression a été effectuée. Ces indicateurs peuvent indiquer si certaines fonctionnalités facultatives, comme l’utilisation de codes de longueur variable, sont utilisées.
- Flux de données compressé:
- Données compressées LZW: le corps principal du fichier .Z contient les données réelles du fichier compressées à l’aide de l’algorithme LZW (Lempel-Ziv-Welch). Les données sont stockées sous la forme d’un flux unique et continu d’informations compressées, ce qui réduit la redondance en codant des modèles de données répétitifs avec des codes plus courts.
- Pas de blocs ni de segmentation: contrairement aux formats plus complexes qui divisent les données en blocs ou segments pour une compression indépendante et une récupération plus facile des erreurs, le format Z compresse l’intégralité du fichier en une seule fois. Cette simplicité était avantageuse pour les ressources informatiques limitées de l’époque mais peut s’avérer un inconvénient si le fichier est corrompu.
- Marqueur de fin de fichier (EOF):
- Terminaison implicite: le format Z n’a pas de marqueur ou de pied de page explicite de fin de fichier. Le flux de données compressé s’exécute simplement jusqu’à ce que la fin du fichier soit atteinte. Le processus de décompression se poursuit jusqu’à ce que toutes les données soient extraites ou jusqu’à ce qu’une erreur soit rencontrée.
- Aucun contrôle d’intégrité intégré: contrairement aux formats de compression modernes, les archives .Z n’incluent pas de sommes de contrôle ou d’autres mécanismes de vérification de l’intégrité des données dans la structure du fichier. Ce manque de détection d’erreur intégrée signifie qu’une corruption ne peut être remarquée lors de la décompression que si les données de sortie sont incomplètes ou incorrectes.
- Métadonnées facultatives:
- Métadonnées minimales: le format de fichier Z est très basique et ne prend pas en charge les métadonnées supplémentaires telles que les noms de fichiers, les horodatages ou les attributs étendus dans le fichier compressé. De telles informations devraient être traitées en externe, généralement par le système de fichiers ou les fichiers qui l’accompagnent.
Popularité du format d'archive Z
Le format de fichier .Z était très populaire au début des systèmes UNIX et Linux, principalement dans les années 1980 et 1990. Il est devenu un standard pour compresser des fichiers sur ces plateformes en raison de son utilisation relativement efficace de l’espace de stockage et de ses temps de décompression rapides. Le format était couramment utilisé pour distribuer des logiciels, des mises à jour du système et des fichiers de données volumineux, en particulier dans les environnements où la capacité de stockage était limitée. Bien que le format Z ait été largement remplacé par des formats de compression plus modernes comme gzip et bzip2 , il reste pris en charge pour la compatibilité existante sur de nombreux systèmes UNIX et Linux. Malgré son déclin en termes d’usage général, le format Z est encore rencontré dans certains contextes d’archives et dans des référentiels de logiciels plus anciens, conservant une place de niche mais un rôle important dans l’histoire de l’informatique.
Exemples d'utilisation des archives Z
Cette section fournit des exemples de code montrant comment compresser et décompresser des archives Z à l’aide de C# et Java. Vous trouverez ci-dessous des exemples utilisant la classe ZArchive pour travailler avec des fichiers Z, illustrant comment ils peuvent être gérés par programme dans les environnements C# et Java.
Сompress the Z file into .Z extension via C# using ZArchive instance.
using (FileStream source = File.Open("alice29.txt", FileMode.Open, FileAccess.Read))
{
using (ZArchive archive = new ZArchive())
{
archive.SetSource(source);
archive.Save("alice29.txt.Z");
}
}
Open Z Archive via C#
FileInfo fi = new FileInfo("data.bin.Z");
using (ZArchive archive = new ZArchive(fi.OpenRead()))
{
archive.Extract("data.bin");
}
Сompress the Z file into .Z extension via Java using ZArchive instance.
try (FileInputStream source = new FileInputStream("alice29.txt")) {
try (ZArchive archive = new ZArchive()) {
archive.setSource(source);
archive.save("alice29.txt.Z");
}
} catch (IOException ex) {
}
Open Z Archive via Java
try (ZArchive archive = new ZArchive("data.bin.Z")) {
archive.extract("data.bin");
}
Informations Complémentaires
Les gens ont demandé
1. Qu’est-ce qu’un fichier Z et en quoi est-il différent des autres formats de fichiers compressés comme ZIP ou GZIP ?
Un fichier Z est une archive compressée créée à l’aide de l’algorithme Lempel-Ziv-Welch (LZW), couramment utilisé sur les systèmes UNIX. Contrairement à ZIP ou GZIP, qui sont plus modernes et offrent de meilleurs taux de compression et des fonctionnalités supplémentaires, le format Z est plus simple et était populaire au début de l’informatique. Les fichiers Z sont généralement rencontrés dans les anciennes distributions de logiciels ou les systèmes hérités.
2. Les fichiers Z sont-ils encore couramment utilisés aujourd’hui ?
Les fichiers Z ne sont pas couramment utilisés aujourd’hui, car ils ont été largement remplacés par des formats de compression plus efficaces tels que GZIP, BZIP2 et XZ. Cependant, les fichiers Z sont toujours pris en charge sur de nombreux systèmes UNIX et Linux pour des raisons de compatibilité avec les anciens systèmes, et ils peuvent toujours être rencontrés dans des archives de logiciels plus anciennes.
3. Puis-je convertir un fichier Z dans un autre format comme ZIP ou GZIP ?
Oui, il est possible de convertir un fichier Z dans un autre format à la volée. Vous pouvez extraire une entrée spécifique d’une archive Z directement en mémoire sans créer de fichier intermédiaire. Cela permet une intégration transparente avec d’autres formats de compression comme gzip ou zip.