LZMA फ़ाइल स्वरूप
LZMA फ़ाइलों तक कैसे पहुँचें, संशोधित करें, जेनरेट करें, डीकंप्रेस करें और रूपांतरित करें
LZMA पुरालेख फ़ाइल स्वरूप
LZMA (लेम्पेल-ज़िव-मार्कोव चेन एल्गोरिदम) एक आधुनिक डेटा संपीड़न एल्गोरिदम है जो अपनी उच्च दक्षता और असाधारण संपीड़न अनुपात के लिए प्रसिद्ध है।
7z
जैसे संग्रह प्रारूपों में व्यापक रूप से उपयोग किया जाता है, एलजेडएमए डीकंप्रेसन गति में महत्वपूर्ण बदलाव के बिना फ़ाइल आकार को प्रभावी ढंग से कम कर देता है। LZMA अभिलेखागार डेटा की गुणवत्ता और अखंडता के संरक्षण की गारंटी देता है, जिससे वे बड़े डेटासेट को कुशलतापूर्वक संग्रहीत और प्रबंधित करने के लिए एक आदर्श समाधान बन जाते हैं।
LZMA का मुख्य लाभ बड़ी फ़ाइलों और जटिल डेटा संरचनाओं को न्यूनतम नुकसान के साथ संभालने की क्षमता है। LZMA का उपयोग करने से आप डिस्क स्थान को अनुकूलित कर सकते हैं और छोटे संग्रह आकार के कारण इंटरनेट पर फ़ाइल स्थानांतरण की सुविधा प्रदान कर सकते हैं। यह LZMA को कुशल डेटा प्रबंधन के लिए डेवलपर्स और सिस्टम प्रशासकों के बीच एक लोकप्रिय विकल्प बनाता है।
एलजेडएमए पुरालेख सूचना के बारे में
LZMA अभिलेखागार समानांतरीकरण का समर्थन करता है, जो तेज़ फ़ाइल संपीड़न और डीकंप्रेसन के लिए मल्टी-कोर प्रोसेसर के कुशल उपयोग की अनुमति देता है। इसके अलावा, LZMA को क्षति के प्रति उच्च प्रतिरोध के लिए जाना जाता है, जो इसे महत्वपूर्ण डेटा के दीर्घकालिक भंडारण के लिए एक विश्वसनीय विकल्प बनाता है। एल्गोरिदम में ओपन सोर्स कोड भी है, जो विभिन्न सॉफ्टवेयर समाधानों में इसके व्यापक कार्यान्वयन और अनुकूलन की सुविधा प्रदान करता है। अपने फायदों के कारण, LZMA सबसे कुशल संपीड़न प्रारूपों में से एक बना हुआ है, जो दुनिया भर के उपयोगकर्ताओं के लिए इष्टतम डेटा प्रबंधन प्रदान करता है।
एलजेएमए का विकास
7-ज़िप प्रोजेक्ट के हिस्से के रूप में 1998 में इगोर पावलोव द्वारा विकसित LZMA एल्गोरिथ्म का उद्देश्य एक अत्यधिक कुशल डेटा संपीड़न विधि बनाना था। प्रारंभ में, इसने क्लासिक LZ77 एल्गोरिदम पर निर्माण किया, जिसमें ऐसी तकनीकों को शामिल किया गया, जिन्होंने संपीड़न दक्षता को महत्वपूर्ण रूप से बढ़ाया। धीरे-धीरे, LZMA ने न्यूनतम संसाधन खपत के साथ बड़े डेटासेट को संसाधित करने की अपनी क्षमता के लिए मान्यता प्राप्त की। 2001 में, LZMA 7z प्रारूप के लिए मुख्य संपीड़न एल्गोरिदम बन गया, जिसने अपने उत्कृष्ट प्रदर्शन के कारण तेजी से लोकप्रियता हासिल की। इसके अलावा, एल्गोरिदम को कई संग्रहकर्ताओं और डेटा भंडारण प्रणालियों, विशेष रूप से ओपन-सोर्स सॉफ़्टवेयर उत्पादों में एकीकृत किया गया है। आज, LZMA लगातार विकसित हो रहा है, निरंतर अपडेट और अनुकूलन के माध्यम से अपनी प्रासंगिकता बनाए रखता है, डिजिटल दुनिया में एक अपरिहार्य उपकरण के रूप में अपनी स्थिति मजबूत करता है।
LZMA एल्गोरिथम के सिद्धांत
LZMA एल्गोरिथ्म उच्च स्तर के संपीड़न को प्राप्त करने के लिए डेटा में अनुक्रमिक दोहराव के उपयोग पर आधारित है। एल्गोरिदम का मुख्य विचार एक शब्दकोश का निर्माण और भंडारण करना है जिसमें पहले से सामना किए गए सबस्ट्रिंग शामिल हैं, जिन्हें बाद में इस शब्दकोश में संदर्भों द्वारा प्रतिस्थापित किया जाता है। यह आपको संग्रहीत या प्रसारित किए जाने वाले डेटा की मात्रा को काफी कम करने की अनुमति देता है। LZMA की प्रमुख विशेषताओं में से एक हफ़मैन कोडिंग के बजाय रेंज एन्कोडिंग का उपयोग है। रेंज एन्कोडिंग डेटा की एन्ट्रापी के करीब बेहतर संपीड़न प्रदान करती है और धीमी पूर्णांक विभाजन संचालन से बचते हुए, बाइनरी प्रारूप का उपयोग करती है।
LZMA खोज बफ़र और पूर्वानुमान बफ़र में सबसे लंबे मिलान खोजने के लिए LZ77 एल्गोरिथ्म का उपयोग करता है, उन्हें एक संपीड़ित फ़ाइल में ट्रिपलेट (दूरी, लंबाई, अगला वर्ण) के रूप में लिखता है। यदि कोई मिलान नहीं मिलता है, तो फ़ाइल में [0,255] श्रेणी में एक बाइट जोड़ा जाता है। यदि कोई मिलान पाया जाता है, तो रेंज एन्कोडिंग विधि द्वारा एन्कोड किए गए मानों (दूरी और लंबाई) की एक जोड़ी रिकॉर्ड की जाती है।
बड़े खोज बफ़र के साथ दक्षता में सुधार करने के लिए, एल्गोरिदम एक समर्पित दूरी इतिहास सरणी में 4 सबसे सामान्य दूरियों को संग्रहीत करता है। यदि इनमें से कोई भी दूरी फिर से दिखाई देती है, तो उन्हें दूरी इतिहास सरणी को संदर्भित करने वाले 2-बिट कोड से बदल दिया जाता है, जिससे मिलान को संग्रहीत करने के लिए आवश्यक जानकारी कम हो जाती है।
LZMA खोज बफ़र में मिलान खोजने के लिए 2-बाइट हैश (वर्तमान बाइट और अगला बाइट) का उपयोग करता है। हैश सरणी का आकार सीधे शब्दकोश आकार से जुड़ा होता है। उदाहरण के लिए, 1 जीबी शब्दकोश 512 एमबी हैश सरणी का उपयोग करता है, जो हैशिंग फ़ंक्शन में टकराव को कम करता है।
यह बहु-स्तरीय दृष्टिकोण महत्वपूर्ण संसाधन खपत के बिना कुशल डेटा संपीड़न और भंडारण प्रदान करता है, जिससे LZMA सबसे कुशल डेटा संपीड़न एल्गोरिदम में से एक बन जाता है।
.lzma फ़ाइल-प्रारूप के लाभ
यहां LZMA के मुख्य लाभ हैं, जो इसे कई डेटा संपीड़न अनुप्रयोगों के लिए एक आकर्षक विकल्प बनाते हैं।
- उच्च संपीड़न अनुपात: LZMA मौजूदा एल्गोरिदम के बीच उच्चतम संपीड़न अनुपात में से एक प्रदान करता है, जो आपको फ़ाइल आकार को महत्वपूर्ण रूप से कम करने की अनुमति देता है। अन्य संग्रह प्रारूपों की तुलना में औसत संपीड़न अनुपात 70% से अधिक है।
- तेजी से डीकंप्रेसन: एल्गोरिदम को तेजी से डेटा डीकंप्रेसन के लिए अनुकूलित किया गया है, जो एलजेएमए को सॉफ्टवेयर अनुप्रयोगों और भंडारण प्रणालियों में उपयोग के लिए उपयुक्त बनाता है जहां तेजी से डेटा पुनर्प्राप्ति आवश्यक है।
- बड़ी फ़ाइलों का कुशल प्रबंधन: खोज बफ़र के बड़े आकार के कारण, LZMA उच्च संपीड़न दर को बनाए रखते हुए बड़ी मात्रा में डेटा को कुशलतापूर्वक संसाधित कर सकता है।
- विश्वसनीयता और क्षति सहनशीलता: LZMA डेटा क्षति के लिए उच्च प्रतिरोध प्रदान करता है। भले ही भंडारण या ट्रांसमिशन के दौरान त्रुटियां होती हैं, इसका डिज़ाइन कुछ त्रुटि सुधार की अनुमति देता है, डेटा हानि को कम करता है और दीर्घकालिक भंडारण के दौरान आपकी जानकारी की अखंडता सुनिश्चित करता है।
- ओपन सोर्स कोड: एलजेडएमए एल्गोरिदम की ओपन-सोर्स प्रकृति इसके व्यापक कार्यान्वयन, अनुकूलन और विभिन्न सॉफ्टवेयर समाधानों में एकीकरण की सुविधा प्रदान करती है, इसके अपनाने और चल रहे विकास को बढ़ावा देती है।
LZMA पुरालेख समर्थित संचालन
Aspose.ZIP उपयोगकर्ताओं को व्यक्तिगत फ़ाइलें और संपूर्ण संग्रह दोनों निकालने की अनुमति देता है। .NET के लिए, आप .lzma फ़ाइल खोलने के लिए LzmaArchiveClass का उपयोग कर सकते हैं, फिर आप इसके रिकॉर्ड के माध्यम से कदम उठा सकते हैं और उन्हें वांछित स्थान पर निकाल सकते हैं। जावा में एक समान दृष्टिकोण का उपयोग किया जाता है, जहां आप .lzma फ़ाइल को खोलने और रिकॉर्ड निकालने के लिए LzmaArchive का उपयोग करते हैं। Aspose.ZIP के लिए धन्यवाद, ये ऑपरेशन किसी भी स्तर के उपयोगकर्ताओं के लिए सरल और सुविधाजनक हो जाते हैं।
एलजेएमए संरचना
हालाँकि यह कहना सही है कि LZMA LZ77 (लेम्पेल-ज़िव 1977) और LZ78 (लेम्पेल-ज़िव 1978) से काफी प्रभावित है, लेकिन LZMA को इन एल्गोरिदम के विकास के रूप में वर्णित करना अधिक सटीक है, जिसमें महत्वपूर्ण संवर्द्धन शामिल हैं।
- <मजबूत >रेंज एन्कोडिंग: LZMA ने हफ़मैन कोडिंग को रेंज एन्कोडिंग से बदल दिया है, जो एक अधिक कुशल डेटा प्रतिनिधित्व विधि है।
- दूरी का इतिहास: LZMA अक्सर उपयोग की जाने वाली दूरियों का इतिहास बनाए रखता है, जिससे मिलान का पता लगाने में तेजी आती है।
- हैश तालिका: LZMA मिलान अनुक्रमों की खोज में तेजी लाने के लिए एक हैश तालिका का उपयोग करता है।
- भविष्य कहनेवाला मॉडलिंग: LZMA आगामी डेटा पैटर्न का पूर्वानुमान लगाने, संपीड़न को और बढ़ाने के लिए पूर्वानुमानित मॉडलिंग तकनीकों को शामिल करता है।
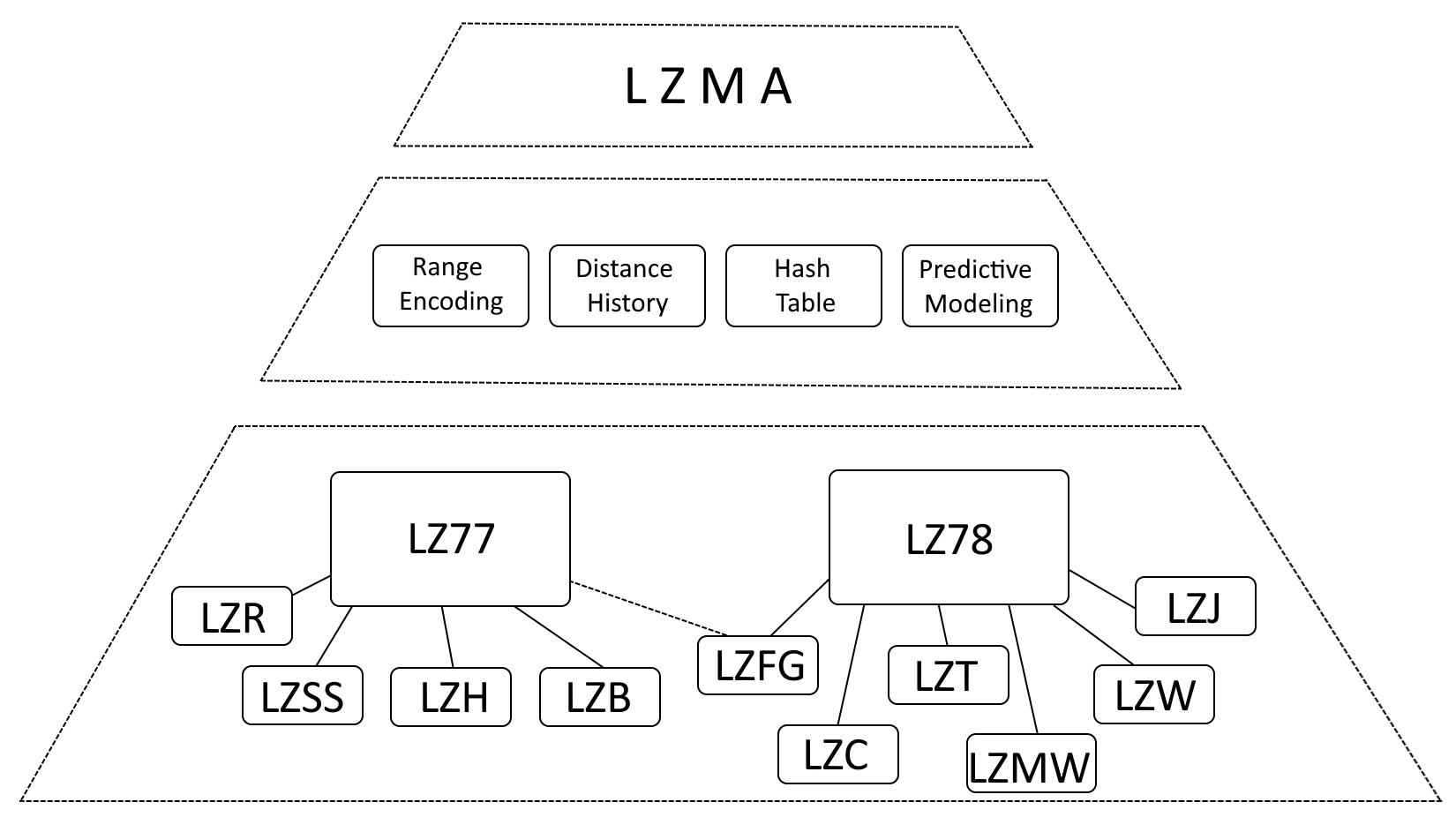
आंतरिक LZMA पुरालेख संरचना
- फ़ाइल मेटाडेटा - टार संग्रह के समान, प्रत्येक फ़ाइल संशोधन समय और अनुमतियों जैसी बुनियादी जानकारी संग्रहीत करती है। हालाँकि, यह अनुभाग लचीला है और आपकी आवश्यकताओं के आधार पर एक्सेस कंट्रोल लिस्ट (एसीएल) या विस्तारित विशेषताओं (ईए) जैसे अतिरिक्त विवरणों को छोड़ने या शामिल करने की अनुमति देता है। डेटा अखंडता सुनिश्चित करने के लिए नियमित फ़ाइलों के लिए एक मजबूत हैश फ़ंक्शन (जैसे SHA1) शामिल करने की अनुशंसा की जाती है।
- एकाधिक सामग्री स्ट्रीम - पारंपरिक अभिलेखागार के विपरीत, फ़ाइलों में आंतरिक डेटा फ़ाइल के भीतर एक से अधिक डेटा स्ट्रीम हो सकती हैं। यह फ़ाइल से जुड़े विस्तारित विशेषताओं या संसाधन फ़ोर्क को संग्रहीत करने के लिए उपयोगी है।
- हेडर - आंतरिक सूचकांक फ़ाइल फ़ाइल हेडर रखती है, जो आंतरिक डेटा फ़ाइल में बिखरे हुए हेडर को प्रतिबिंबित करती है। लेकिन, जब अलग से संग्रहीत किया जाता है, तो इंडेक्स हेडर को डेटा फ़ाइल के भीतर उनके संबंधित डेटा की शुरुआती स्थिति का संदर्भ देना चाहिए। इसके अतिरिक्त, इंडेक्स में निर्देशिका प्रविष्टियाँ उनकी निहित फ़ाइलों और आंतरिक फ़ाइल इंडेक्स के भीतर उनके संबंधित ऑफसेट को सूचीबद्ध करती हैं।
- डुप्लिकेट मेटाडेटा के लिए तर्क - यह डिज़ाइन विकल्प कुशल डेटा स्ट्रीमिंग/डिकोडिंग और रैंडम फ़ाइल एक्सेस दोनों सुनिश्चित करता है। इसके अतिरिक्त, मेटाडेटा अच्छी तरह से संपीड़ित होता है, जिसके परिणामस्वरूप न्यूनतम भंडारण ओवरहेड होता है। परीक्षणों से पता चलता है कि मेटाडेटा आम तौर पर भंडारण स्थान के 0.3% से कम पर कब्जा करता है, जिससे व्यापार-बंद सार्थक हो जाता है।
- ब्लॉक हेडर - बाहरी फ़ाइल के समान ब्लॉक हेडर में ब्लॉक आकार की जानकारी और एक विशिष्ट पहचानकर्ता अनुक्रम होता है।
एलजेडएमए पायथन का उपयोग करने के उदाहरण
Aspose.ZIP via Python API के साथ, आप अन्य बाहरी सॉफ़्टवेयर की आवश्यकता को समाप्त करते हुए, अपने अनुप्रयोगों में LZMA अभिलेखागार को आसानी से प्रबंधित कर सकते हैं। एपीआई में LzmaArchive क्लास शामिल है, जो LZMA आर्काइव्स के साथ काम करना आसान बनाता है, और LzmaCompressionSettings क्लास , जो आपको इष्टतम प्रदर्शन और फ़ाइल आकार में कमी के लिए संपीड़न सेटिंग्स को अनुकूलित करने की अनुमति देता है।
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
LZMA-अभिलेखागार के बारे में अतिरिक्त जानकारी
लोग पूछ रहे हैं
1. कौन से फ़ाइल स्वरूप LZMA संपीड़न का उपयोग करते हैं?
LZMA स्वयं एक फ़ाइल प्रारूप नहीं है, बल्कि विभिन्न संग्रह प्रारूपों में उपयोग किया जाने वाला एक संपीड़न एल्गोरिदम है। कुछ सामान्य उदाहरणों में 7z, XZ और कभी-कभी ZIP शामिल हैं। जब आपके सामने इन एक्सटेंशन वाली कोई फ़ाइल आती है, तो उसे LZM का उपयोग करके संपीड़ित किया जा सकता है
2. क्या LZMA खुला स्रोत है?
हाँ, LZMA एक ओपन-सोर्स एल्गोरिदम है, जो इसे विभिन्न सॉफ़्टवेयर समाधानों में उपयोग और एकीकरण के लिए स्वतंत्र रूप से उपलब्ध कराता है। इस ओपन-सोर्स प्रकृति ने इसके व्यापक रूप से अपनाने और चल रहे विकास में योगदान दिया है।
3. LZMA के कुछ विकल्प क्या हैं?
कई संपीड़न एल्गोरिदम अलग-अलग ट्रेड-ऑफ़ प्रदान करते हैं। ज़िप संपीड़न और गति को अच्छी तरह से संतुलित करता है, BZIP2 LZMA की तुलना में गति की कीमत पर उच्च संपीड़न प्रदान करता है, जबकि LZMA पर आधारित XZ, मजबूत संपीड़न प्रदान करता है और आमतौर पर लिनक्स वातावरण में उपयोग किया जाता है।