LZMA fájlformátum
Hogyan lehet elérni, módosítani, előállítani, kicsomagolni és átalakítani az LZMA fájlokat
LZMA archív fájlformátum
Az LZMA (Lempel-Ziv-Markov láncalgoritmus) egy modern adattömörítési algoritmus, amely nagy hatékonyságáról és kivételes tömörítési arányáról híres. Az olyan archív formátumokban széles körben használt LZMA, mint a
7z
, hatékonyan csökkenti a fájlméretet anélkül, hogy a kitömörítési sebességet jelentős mértékben feláldozná. Az LZMA archívumok garantálják az adatok minőségének és integritásának megőrzését, így tökéletes megoldást jelentenek a nagy adatkészletek hatékony tárolására és kezelésére.
Az LZMA fő előnye, hogy képes nagy fájlokat és összetett adatstruktúrákat minimális veszteséggel kezelni. Az LZMA használata lehetővé teszi a lemezterület optimalizálását, és megkönnyíti a fájlátvitelt az interneten a kisebb archívumméret miatt. Ez teszi az LZMA-t népszerű választássá a fejlesztők és a rendszergazdák körében a hatékony adatkezelés érdekében.
Az LZMA archívuminformációiról
Az LZMA archívumok támogatják a párhuzamosítást, amely lehetővé teszi a többmagos processzorok hatékony használatát a gyorsabb fájltömörítés és kitömörítés érdekében. Ezenkívül az LZMA kiváló sérülésállóságáról ismert, így megbízható választás a fontos adatok hosszú távú tárolására. Az algoritmus nyílt forráskóddal is rendelkezik, amely megkönnyíti annak széles körű implementálását és adaptálását különféle szoftveres megoldásokban. Előnyei miatt az LZMA továbbra is az egyik leghatékonyabb tömörítési formátum, amely optimális adatkezelést biztosít a felhasználók számára világszerte.
Az LZMA evolúciója
Az Igor Pavlov által 1998-ban, a 7-Zip projekt részeként kifejlesztett LZMA algoritmus célja egy rendkívül hatékony adattömörítési módszer létrehozása volt. Kezdetben a klasszikus LZ77 algoritmusokra épült, és olyan technikákat tartalmazott, amelyek jelentősen növelték a tömörítési hatékonyságot. Az LZMA fokozatosan elismerést szerzett arról, hogy képes nagy adatkészleteket minimális erőforrás-felhasználással feldolgozni. 2001-ben az LZMA lett a 7z formátum alapvető tömörítési algoritmusa, amely kiemelkedő teljesítményének köszönhetően gyorsan népszerűvé vált. Ezenkívül az algoritmust számos archiválóba és adattároló rendszerbe integrálták, különösen a nyílt forráskódú szoftvertermékekbe. Manapság az LZMA tovább fejlődik, folyamatos frissítésekkel és optimalizálásokkal megőrzi relevanciáját, megszilárdítva pozícióját a digitális világban nélkülözhetetlen eszközként.
Az LZMA algoritmus alapelvei
Az LZMA algoritmus az adatok szekvenciális ismétlődéseinek felhasználásán alapul a nagyfokú tömörítés elérése érdekében. Az algoritmus fő ötlete egy olyan szótár felépítése és tárolása, amely korábban találkozott részkarakterláncokat tartalmaz, amelyeket aztán hivatkozásokkal helyettesítenek ebben a szótárban. Ezzel jelentősen csökkenthető a tárolandó vagy továbbítandó adatok mennyisége. Az LZMA egyik legfontosabb jellemzője, hogy Huffman kódolás helyett tartománykódolást használ. A tartománykódolás jobb tömörítést kínál, közelebb az adatok entrópiájához, és bináris formátumot használ, elkerülve a lassú egész osztási műveleteket.
Az LZMA az LZ77 algoritmust használja, hogy megtalálja a leghosszabb egyezéseket a keresési pufferben és a predikciós pufferben, és egy tömörített fájlba írja őket triplet formájában (távolság, hossz, következő karakter). Ha nem található egyezés, egy bájt a [0,255] tartományba kerül a fájlhoz. Ha talál egyezést, a rendszer rögzíti a tartománykódolási módszerrel kódolt értékpárt (távolság és hosszúság).
A hatékonyság növelése érdekében a nagy keresési pufferrel az algoritmus a 4 leggyakoribb távolságot egy dedikált távolságtörténeti tömbben tárolja. Ha ezen távolságok bármelyike újra megjelenik, akkor a helyükre egy 2 bites kód kerül, amely a távolságtörténeti tömbre hivatkozik, csökkentve az egyezés tárolásához szükséges információkat.
Az LZMA 2 bájtos hash-t (az aktuális és a következő bájtot) használ az egyezések megtalálásához a keresési pufferben. A hash tömb mérete közvetlenül kapcsolódik a szótár méretéhez. Például egy 1 GB-os szótár 512 MB-os hash tömböt használ, amely minimalizálja az ütközéseket a kivonatolási függvényben.
Ez a többszintű megközelítés hatékony adattömörítést és tárolást biztosít jelentős erőforrás-felhasználás nélkül, így az LZMA az egyik leghatékonyabb adattömörítési algoritmus.
Az .lzma fájlformátum előnyei
Íme az LZMA fő előnyei, amelyek vonzó választássá teszik számos adattömörítési alkalmazáshoz.
- Magas tömörítési arány: Az LZMA a létező algoritmusok közül az egyik legmagasabb tömörítési arányt biztosítja, amely lehetővé teszi a fájlméret jelentős csökkentését. Az átlagos tömörítési arány meghaladja a 70%-ot más archív formátumokhoz képest.
- Gyors kitömörítés: Az algoritmust a gyors adatkitömörítésre optimalizálták, így az LZMA jól használható szoftveralkalmazásokban és tárolórendszerekben, ahol elengedhetetlen a gyors adatvisszakeresés.
- Nagy fájlok hatékony kezelése: A keresési puffer nagy mérete miatt az LZMA hatékonyan képes nagy mennyiségű adatot feldolgozni, miközben magas tömörítési arányt tart fenn.
- Megbízhatóság és sérüléstűrés: Az LZMA nagy ellenállást biztosít az adatok sérülésével szemben. Még ha hibák is előfordulnak a tárolás vagy az átvitel során, kialakítása lehetővé teszi a hibajavítást, minimálisra csökkenti az adatvesztést és biztosítja az adatok integritását a hosszú távú tárolás során.
- Nyílt forráskód: Az LZMA algoritmus nyílt forráskódú jellege elősegíti széleskörű implementációját, adaptálását és különféle szoftvermegoldásokba való integrálását, elősegítve annak elfogadását és folyamatos fejlesztését.
LZMA Archívum Támogatott műveletek
Az Aspose.ZIP lehetővé teszi a felhasználók számára az egyes fájlok és a teljes archívum kibontását. .NET esetén az LzmaArchiveClass segítségével megnyithat egy .lzma fájlt, majd átlépheti a rekordjait, és kibonthatja azokat a kívánt helyre. Hasonló megközelítést használ a Java, ahol az LzmaArchive segítségével nyissa meg az .lzma fájlt és bontsa ki a rekordokat. Az Aspose.ZIP-nek köszönhetően ezek a műveletek egyszerűvé és kényelmessé válnak bármilyen szintű felhasználó számára.
LZMA szerkezet
Bár helyes azt mondani, hogy az LZMA-t erősen befolyásolja az LZ77 (Lempel-Ziv 1977) és az LZ78 (Lempel-Ziv 1978), pontosabb az LZMA-t ezeknek az algoritmusoknak a fejlődéseként leírni, amely jelentős fejlesztéseket tartalmaz.
- >Tartománykódolás: Az LZMA a Huffman-kódolást tartománykódolással helyettesíti, amely egy hatékonyabb adatábrázolási módszer.
- Távolságelőzmények: Az LZMA megőrzi a gyakran használt távolságok előzményeit, felgyorsítva a mérkőzések észlelését.
- Kivonattábla: Az LZMA hash táblát használ a megfelelő szekvenciák keresésének felgyorsítására.
- Prediktív modellezés: Az LZMA prediktív modellezési technikákat tartalmaz a közelgő adatminták előrejelzésére, tovább javítva a tömörítést.
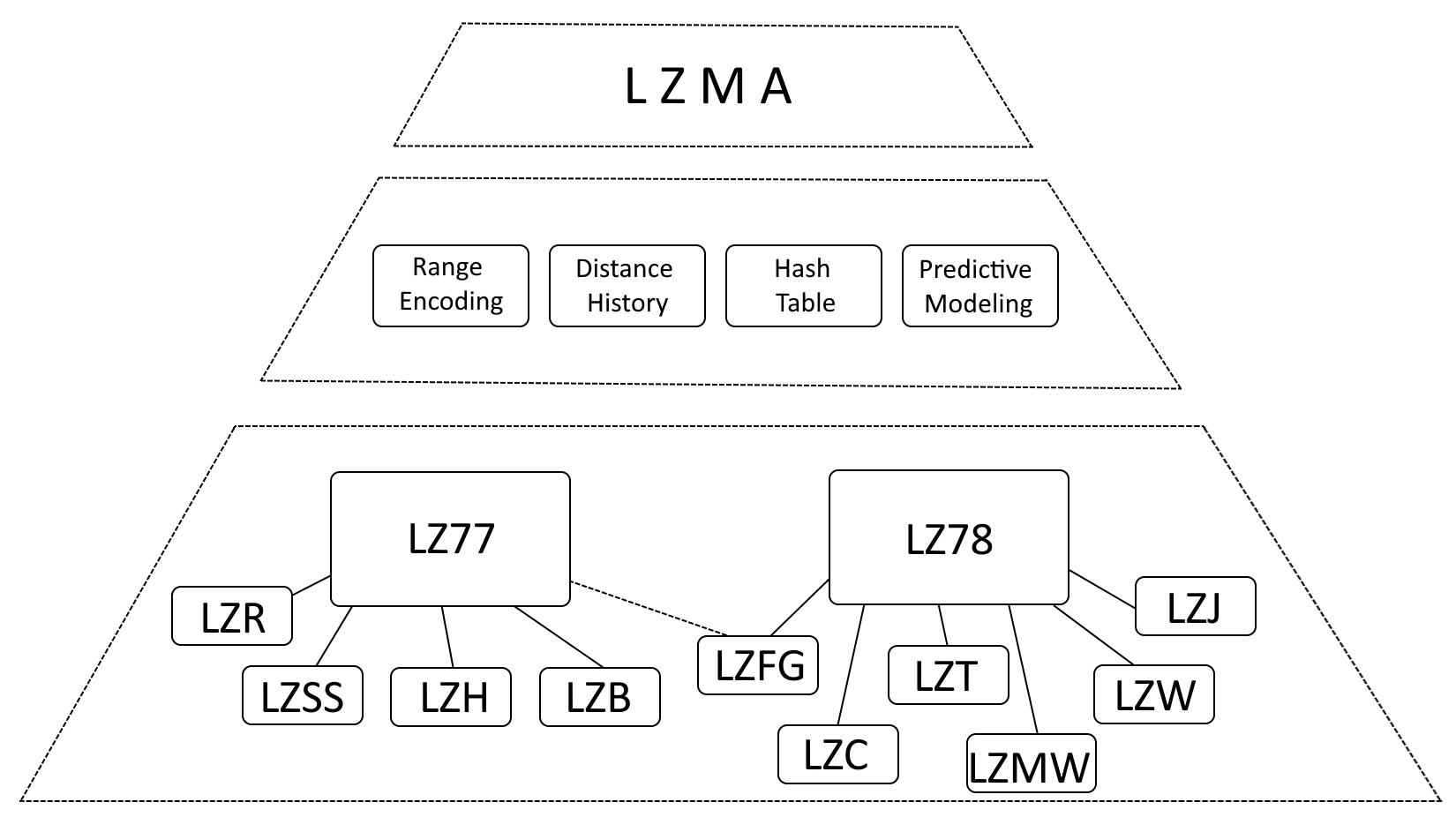
Belső LZMA archívum struktúra
- Fájl metaadatai - A tar archívumhoz hasonlóan minden fájl alapvető információkat tárol, például a módosítási időt és az engedélyeket. Ez a szakasz azonban rugalmas, és lehetővé teszi további részletek, például hozzáférés-vezérlési listák (ACL-ek) vagy kiterjesztett attribútumok (EA-k) kihagyását vagy belefoglalását az Ön igényei szerint. Javasoljuk, hogy a rendszeres fájlokhoz erős hash funkciót (például SHA1) használjon az adatok integritásának biztosítása érdekében.
- Több tartalomfolyam - A hagyományos archívumokkal ellentétben a fájlok egynél több adatfolyamot tartalmazhatnak a belső adatfájlon belül. Ez hasznos a fájlhoz társított kiterjesztett attribútumok vagy erőforrás-elágazások tárolására.
- Fejlécek - A belső indexfájl a fájlfejléceket tartalmazza, tükrözve a belső adatfájlban szétszórtakat. Ha azonban külön tárolják, az indexfejléceknek hivatkozniuk kell a megfelelő adatok kiindulási helyzetére az adatfájlban. Ezenkívül az indexben lévő könyvtárbejegyzések felsorolják a benne lévő fájlokat és a megfelelő eltolásokat a belső fájlindexen belül.
- Az ismétlődő metaadatok indoklása - Ez a tervezési választás biztosítja a hatékony adatfolyam-továbbítást/dekódolást és a véletlenszerű fájlhozzáférést. Ezenkívül a metaadatok jól tömörülnek, ami minimális tárolási többletköltséget eredményez. A tesztek azt mutatják, hogy a metaadatok általában a tárhely kevesebb, mint 0,3%-át foglalják el, így megéri a kompromisszum.
- Blokkfejlécek - A blokkfejlécek a külső fájlhoz hasonlóan blokkméret-információkat és egyedi azonosító sorozatot tartalmaznak.
Példák az LZMA Python használatára
Az Aspose.ZIP via Python API-val könnyedén kezelheti alkalmazásaiban az LZMA archívumokat, így nincs szükség más külső szoftverekre. Az API tartalmazza az LzmaArchive osztályt , amely leegyszerűsíti az LZMA archívumokkal való munkát, és az LzmaCompressionSettings osztályt , amely lehetővé teszi a tömörítési beállítások testreszabását az optimális teljesítmény és a fájlméret csökkentése érdekében.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
További információk az LZMA-archívumokról
Az emberek kérdezték
1. Milyen fájlformátumok használnak LZMA tömörítést?
Az LZMA nem egy fájlformátum, hanem egy tömörítési algoritmus, amelyet különféle archív formátumokban használnak. Néhány gyakori példa a 7z, XZ és esetenként ZIP. Ha ilyen kiterjesztésű fájlokkal találkozik, előfordulhat, hogy az LZM segítségével tömörítve van
2. Az LZMA nyílt forráskódú?
Igen, az LZMA egy nyílt forráskódú algoritmus, amely szabadon elérhetővé teszi a használatát és a különféle szoftvermegoldásokba való integrálását. Ez a nyílt forráskódú természet hozzájárult annak széles körű elterjedéséhez és folyamatos fejlesztéséhez.
3. Mik az LZMA alternatívái?
Számos tömörítési algoritmus kínál különböző kompromisszumokat. A ZIP jól kiegyensúlyozza a tömörítést és a sebességet, a BZIP2 nagy tömörítést biztosít gyorsaság árán az LZMA-hoz képest, míg az LZMA-n alapuló XZ erős tömörítést kínál, és általában Linux környezetekben használják.