Formato file LZMA
Come accedere, modificare, generare, decomprimere e trasformare i file LZMA
Formato file di archivio LZMA
LZMA (algoritmo a catena Lempel-Ziv-Markov) è un moderno algoritmo di compressione dei dati rinomato per la sua alta efficienza e l’eccezionale rapporto di compressione. Ampiamente utilizzato nei formati di archivio come
7z
, LZMA riduce efficacemente le dimensioni del file senza sacrificare in modo significativo la velocità di decompressione. Gli archivi LZMA garantiscono la conservazione della qualità e dell’integrità dei dati, rendendoli una soluzione perfetta per archiviare e gestire in modo efficiente set di dati di grandi dimensioni.
Il vantaggio principale di LZMA è la sua capacità di gestire file di grandi dimensioni e strutture di dati complesse con una perdita minima. L’uso di LZMA consente di ottimizzare lo spazio su disco e facilita il trasferimento di file su Internet grazie alle dimensioni dell’archivio inferiori. Ciò rende LZMA una scelta popolare tra sviluppatori e amministratori di sistema per una gestione efficiente dei dati.
Informazioni sull'archivio LZMA
Gli archivi LZMA supportano la parallelizzazione, che consente un uso efficiente di processori multi-core per una compressione e decompressione dei file più rapida. Inoltre, LZMA è noto per la sua elevata resistenza ai danni, che lo rende una scelta affidabile per l’archiviazione a lungo termine di dati importanti. L’algoritmo dispone anche di codice open source, che ne facilita l’ampia implementazione e adattamento in varie soluzioni software. Grazie ai suoi vantaggi, LZMA rimane uno dei formati di compressione più efficienti, fornendo una gestione ottimale dei dati per gli utenti di tutto il mondo.
Evoluzione dell'LZMA
L’algoritmo LZMA, sviluppato da Igor Pavlov nel 1998 come parte del progetto 7-Zip, mirava a creare un metodo di compressione dei dati altamente efficiente. Inizialmente, si basava sui classici algoritmi LZ77, incorporando tecniche che aumentavano significativamente l’efficienza della compressione. A poco a poco, LZMA ha ottenuto il riconoscimento per la sua capacità di elaborare grandi set di dati con un consumo minimo di risorse. Nel 2001, LZMA è diventato l’algoritmo di compressione principale per il formato 7z, che ha rapidamente guadagnato popolarità grazie alle sue prestazioni eccezionali. Inoltre, l’algoritmo è stato integrato in numerosi archiviatori e sistemi di archiviazione dati, in particolare in prodotti software open source. Oggi, LZMA continua ad evolversi, mantenendo la sua rilevanza attraverso continui aggiornamenti e ottimizzazioni, consolidando la sua posizione come strumento indispensabile nel mondo digitale.
Principi dell'algoritmo LZMA
L’algoritmo LZMA si basa sull’uso di ripetizioni sequenziali nei dati per ottenere un elevato grado di compressione. L’idea principale dell’algoritmo è costruire e memorizzare un dizionario contenente le sottostringhe precedentemente incontrate, che vengono poi sostituite dai riferimenti in questo dizionario. Ciò consente di ridurre notevolmente la quantità di dati da archiviare o trasmettere. Una delle caratteristiche principali di LZMA è l’uso della codifica range invece della codifica Huffman. La codifica dell’intervallo offre una migliore compressione più vicina all’entropia dei dati e utilizza un formato binario, evitando operazioni lente di divisione di numeri interi.
LZMA utilizza l’algoritmo LZ77 per trovare le corrispondenze più lunghe nel buffer di ricerca e nel buffer di previsione, scrivendole in un file compresso sotto forma di tripletta (distanza, lunghezza, carattere successivo). Se non viene trovata alcuna corrispondenza, al file viene aggiunto un byte nell’intervallo [0,255]. Se viene trovata una corrispondenza, viene registrata una coppia di valori (distanza e lunghezza) codificati dal metodo di codifica dell’intervallo.
Per migliorare l’efficienza con un ampio buffer di ricerca, l’algoritmo memorizza le 4 distanze più comuni in un array cronologico delle distanze dedicato. Se una qualsiasi di queste distanze riappare, viene sostituita con un codice a 2 bit che fa riferimento all’array della cronologia delle distanze, riducendo le informazioni necessarie per memorizzare la corrispondenza.
LZMA utilizza un hash di 2 byte (il byte corrente e il byte successivo) per trovare corrispondenze nel buffer di ricerca. La dimensione dell’array hash è direttamente legata alla dimensione del dizionario. Ad esempio, un dizionario da 1 GB utilizza un array hash da 512 MB, che riduce al minimo le collisioni nella funzione di hashing.
Questo approccio multilivello fornisce un’efficiente compressione e archiviazione dei dati senza un consumo significativo di risorse, rendendo LZMA uno degli algoritmi di compressione dei dati più efficienti.
Vantaggi del formato file .lzma
Ecco i principali vantaggi di LZMA, che lo rendono una scelta interessante per molte applicazioni di compressione dei dati.
- Rapporto di compressione elevato: LZMA fornisce uno dei rapporti di compressione più elevati tra gli algoritmi esistenti, che consente di ridurre significativamente le dimensioni dei file. I rapporti di compressione medi superano il 70% rispetto ad altri formati di archivio.
- Decompressione rapida: l’algoritmo è ottimizzato per la decompressione rapida dei dati, rendendo LZMA adatto per l’uso in applicazioni software e sistemi di archiviazione in cui è essenziale il recupero rapido dei dati.
- Gestione efficiente di file di grandi dimensioni: grazie alle grandi dimensioni del buffer di ricerca, LZMA può elaborare in modo efficiente grandi quantità di dati mantenendo un elevato tasso di compressione.
- Affidabilità e tolleranza ai danni: LZMA offre un’elevata resistenza ai danni ai dati. Anche se si verificano errori durante l’archiviazione o la trasmissione, il suo design consente la correzione degli errori, riducendo al minimo la perdita di dati e garantendo l’integrità delle informazioni durante l’archiviazione a lungo termine.
- Codice open source: la natura open source dell’algoritmo LZMA ne facilita l’implementazione diffusa, l’adattamento e l’integrazione in varie soluzioni software, promuovendone l’adozione e lo sviluppo continuo.
Operazioni supportate dall'archivio LZMA
Aspose.ZIP consente agli utenti di estrarre sia singoli file che l’intero archivio. Per .NET, puoi utilizzare LzmaArchiveClass per aprire un file .lzma, quindi puoi scorrere i suoi record ed estrarli nella posizione desiderata. Un approccio simile viene utilizzato in Java, dove si utilizza LzmaArchive per aprire il file .lzma ed estrarre i record. Grazie ad Aspose.ZIP queste operazioni diventano semplici e convenienti per utenti di qualsiasi livello.
struttura LZMA
Sebbene sia corretto affermare che LZMA è fortemente influenzato da LZ77 (Lempel-Ziv 1977) e LZ78 (Lempel-Ziv 1978), è più preciso descrivere LZMA come un’evoluzione di questi algoritmi, incorporando miglioramenti significativi.
- Codifica intervallo: LZMA sostituisce la codifica Huffman con la codifica intervallo, un metodo di rappresentazione dei dati più efficiente.
- Cronologia delle distanze: LZMA mantiene una cronologia delle distanze utilizzate di frequente, accelerando il rilevamento della corrispondenza.
- Tabella hash: LZMA utilizza una tabella hash per accelerare la ricerca di sequenze corrispondenti.
- Modellazione predittiva: LZMA incorpora tecniche di modellazione predittiva per anticipare i futuri modelli di dati, migliorando ulteriormente la compressione.
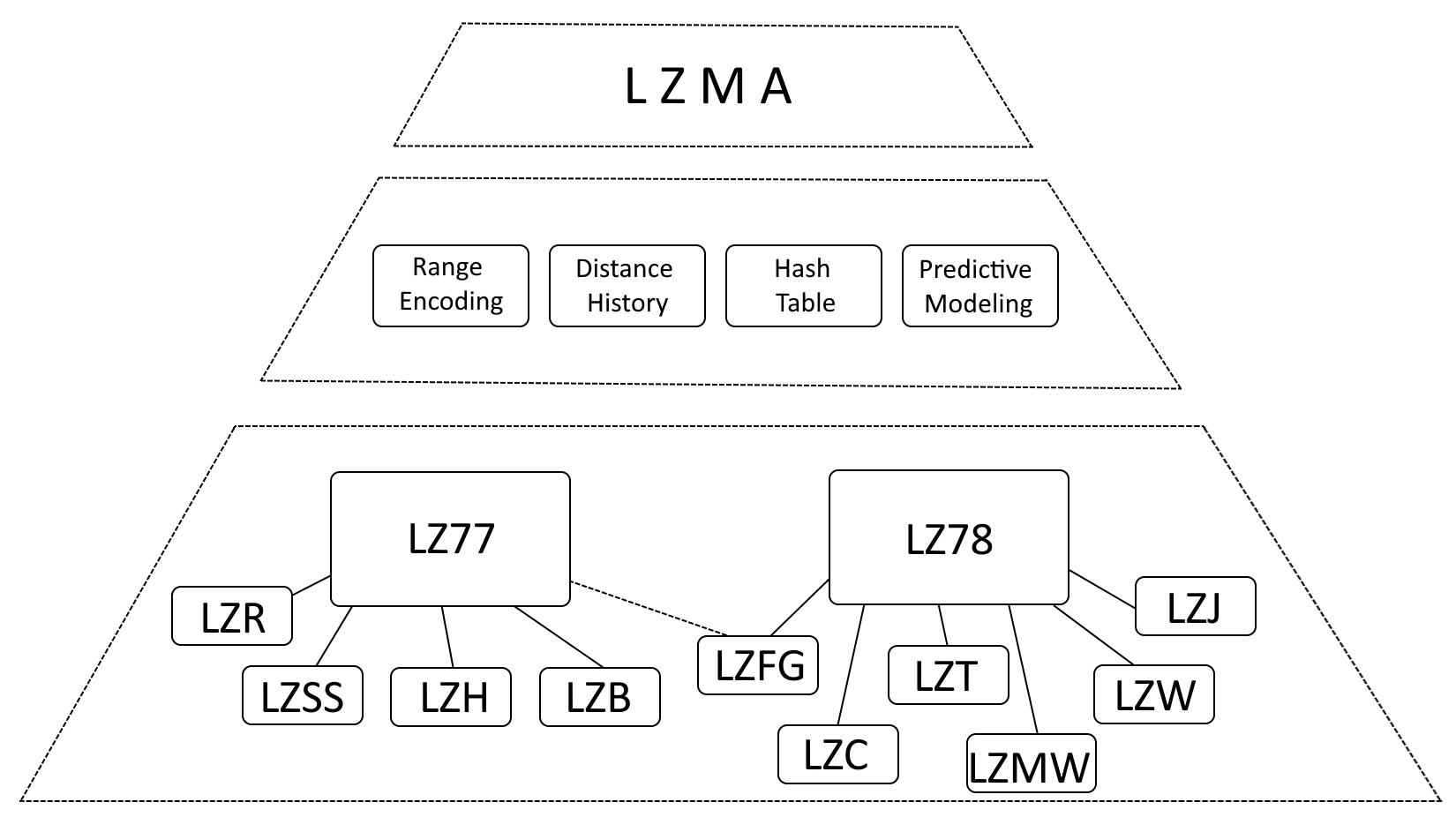
Struttura interna dell'archivio LZMA
- Metadati dei file: simile a un archivio tar, ogni file memorizza informazioni di base come l’ora della modifica e le autorizzazioni. Tuttavia, questa sezione è flessibile e consente di omettere o includere dettagli aggiuntivi come elenchi di controllo degli accessi (ACL) o attributi estesi (EA) in base alle proprie esigenze. Si consiglia di includere una funzione hash potente (come SHA1) per i file normali per garantire l’integrità dei dati.
- Flussi di contenuto multipli - A differenza degli archivi tradizionali, i file possono avere più di un flusso di dati all’interno del file di dati interno. Ciò è utile per memorizzare attributi estesi o fork di risorse associati al file.
- Intestazioni - Il file di indice interno contiene le intestazioni dei file, rispecchiando quelle sparse nel file di dati interno. Ma, se archiviate separatamente, le intestazioni dell’indice devono fare riferimento alla posizione iniziale dei dati corrispondenti all’interno del file di dati. Inoltre, le voci di directory nell’indice elencano i file contenuti e i relativi offset all’interno dell’indice dei file interni.
- Motivazione per i metadati duplicati - Questa scelta di progettazione garantisce sia uno streaming/decodifica efficiente dei dati che un accesso casuale ai file. Inoltre, i metadati vengono compressi bene, con un conseguente sovraccarico di archiviazione minimo. I test mostrano che i metadati occupano in genere meno dello 0,3% dello spazio di archiviazione, rendendo utile il compromesso.
- Intestazioni di blocco: le intestazioni di blocco, simili al file esterno, contengono informazioni sulla dimensione del blocco e una sequenza di identificatori univoci.
Esempi di utilizzo di LZMA Python
Con l’API Aspose.ZIP tramite Python , puoi gestire facilmente gli archivi LZMA nelle tue applicazioni, eliminando la necessità di altri software esterni. L’API include la classe LzmaArchive , che semplifica il lavoro con gli archivi LZMA, e la classe LzmaCompressionSettings , che consente di personalizzare le impostazioni di compressione per prestazioni ottimali e riduzione delle dimensioni del file.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Ulteriori informazioni sugli archivi LZMA
La gente se lo è chiesto
1. Quali formati di file utilizzano la compressione LZMA?
LZMA non è un formato di file in sé ma un algoritmo di compressione utilizzato all’interno di vari formati di archivio. Alcuni esempi comuni includono 7z, XZ e occasionalmente ZIP. Quando incontri un file con queste estensioni, potrebbe essere compresso utilizzando LZM
2. LZMA è open source?
Sì, LZMA è un algoritmo open source, che lo rende liberamente disponibile per l’uso e l’integrazione in varie soluzioni software. Questa natura open source ha contribuito alla sua adozione diffusa e allo sviluppo continuo.
3. Quali sono alcune alternative a LZMA?
Diversi algoritmi di compressione offrono diversi compromessi. ZIP bilancia bene compressione e velocità, BZIP2 fornisce un’elevata compressione a scapito della velocità rispetto a LZMA, mentre XZ, basato su LZMA, offre una compressione elevata ed è comunemente utilizzato in ambienti Linux.