LZMA ファイル形式
LZMA ファイルにアクセス、変更、生成、解凍、変換する方法
LZMA アーカイブ ファイル形式
LZMA (Lempel-Ziv-Markov 連鎖アルゴリズム) は、その高効率と優れた圧縮率で知られる最新のデータ圧縮アルゴリズムです。
7z
などのアーカイブ形式で広く使用されている LZMA は、解凍速度を大幅に犠牲にすることなく、ファイル サイズを効果的に削減します。 LZMA アーカイブはデータの品質と整合性の保持を保証し、大規模なデータセットを効率的に保存および管理するための完璧なソリューションとなります。
LZMA の主な利点は、大きなファイルや複雑なデータ構造を損失を最小限に抑えて処理できることです。 LZMA を使用すると、ディスク容量が最適化され、アーカイブ サイズが小さくなるため、インターネット経由でのファイル転送が容易になります。このため、LZMA は効率的なデータ管理のために開発者やシステム管理者の間で人気の選択肢となっています。
LZMAアーカイブ情報について
LZMA アーカイブは並列化をサポートしているため、マルチコア プロセッサを効率的に使用してファイルの圧縮と解凍を高速化できます。さらに、LZMA は損傷に対する耐性が高いことで知られており、重要なデータの長期保存に信頼できる選択肢となります。このアルゴリズムにはオープン ソース コードもあり、さまざまなソフトウェア ソリューションでの広範な実装と適応が容易になります。その利点により、LZMA は依然として最も効率的な圧縮形式の 1 つであり、世界中のユーザーに最適なデータ管理を提供します。
LZMAの進化
LZMA アルゴリズムは、7-Zip プロジェクトの一環として 1998 年に Igor Pavlov によって開発され、高効率のデータ圧縮方法を作成することを目的としていました。当初は、圧縮効率を大幅に向上させる技術を組み込んだ、古典的な LZ77 アルゴリズムに基づいて構築されていました。 LZMA は、最小限のリソース消費で大規模なデータセットを処理できる能力が徐々に認知されるようになりました。 2001 年に、LZMA は 7z フォーマットのコア圧縮アルゴリズムとなり、その優れたパフォーマンスにより急速に人気を博しました。 さらに、このアルゴリズムは、数多くのアーカイバーやデータ ストレージ システム、特にオープンソース ソフトウェア製品に統合されています。現在、LZMA は進化を続けており、継続的な更新と最適化を通じて関連性を維持し、デジタル世界で不可欠なツールとしての地位を固めています。
LZMA アルゴリズムの原理
LZMA アルゴリズムは、高度な圧縮を達成するためにデータ内での連続的な繰り返しの使用に基づいています。このアルゴリズムの主なアイデアは、以前に検出された部分文字列を含む辞書を構築して保存し、その後、この辞書内の参照に置き換えることです。これにより、保存または送信されるデータの量を大幅に削減できます。 LZMA の重要な機能の 1 つは、ハフマン コーディングの代わりにレンジ エンコーディングを使用することです。範囲エンコードは、データのエントロピーに近い圧縮率を実現し、バイナリ形式を利用して、低速な整数除算演算を回避します。
LZMA は、LZ77 アルゴリズムを使用して検索バッファーと予測バッファー内で最長一致を検索し、それらを 3 つの要素 (距離、長さ、次の文字) の形式で圧縮ファイルに書き込みます。一致するものが見つからない場合は、範囲 [0,255] のバイトがファイルに追加されます。一致が見つかった場合は、範囲エンコード方式でエンコードされた値のペア (距離と長さ) が記録されます。
大規模な検索バッファで効率を向上させるために、アルゴリズムは、最も一般的な 4 つの距離を専用の距離履歴配列に保存します。これらの距離のいずれかが再発した場合、それらは距離履歴配列を参照する 2 ビット コードに置き換えられ、一致を保存するために必要な情報が削減されます。
LZMA は、2 バイトのハッシュ (現在のバイトと次のバイト) を使用して、検索バッファ内で一致を見つけます。ハッシュ配列のサイズは辞書のサイズに直接関係します。たとえば、1 GB の辞書は 512 MB のハッシュ配列を使用するため、ハッシュ関数内の衝突が最小限に抑えられます。
このマルチレベルのアプローチは、リソースを大幅に消費することなく効率的なデータ圧縮とストレージを提供し、LZMA を最も効率的なデータ圧縮アルゴリズムの 1 つとしています。
.lzma ファイル形式の利点
LZMA が多くのデータ圧縮アプリケーションにとって魅力的な選択肢となる主な利点は次のとおりです。
- 高い圧縮率: LZMA は、既存のアルゴリズムの中で最も高い圧縮率の 1 つを提供し、ファイル サイズを大幅に削減できます。他のアーカイブ形式と比較して、平均圧縮率は 70% を超えます。
- 高速解凍: アルゴリズムは高速データ解凍用に最適化されており、LZMA は迅速なデータ取得が不可欠なソフトウェア アプリケーションやストレージ システムでの使用に適しています。
- 大きなファイルの効率的な管理: 検索バッファのサイズが大きいため、LZMA は高い圧縮率を維持しながら大量のデータを効率的に処理できます。
- 信頼性と損傷耐性: LZMA はデータ損傷に対する高い耐性を提供します。保管中または送信中にエラーが発生した場合でも、ある程度のエラー修正が可能な設計になっているため、データ損失が最小限に抑えられ、長期保管中の情報の完全性が保証されます。
- オープン ソース コード: LZMA アルゴリズムのオープンソースの性質により、その広範な実装、適応、およびさまざまなソフトウェア ソリューションへの統合が容易になり、その採用と継続的な開発が促進されます。
LZMA アーカイブでサポートされる操作
Aspose.ZIP を使用すると、ユーザーは個々のファイルとアーカイブ全体の両方を抽出できます。 .NET の場合、 LzmaArchiveClass を使用して .lzma ファイルを開き、そのレコードをステップ実行して目的の場所に抽出できます。 Java でも同様のアプローチが使用されており、LzmaArchive を使用して .lzma ファイルを開いてレコードを抽出します。 Aspose.ZIP のおかげで、これらの操作は、あらゆるレベルのユーザーにとって簡単かつ便利になります。
LZMA構造
LZMA が LZ77 (Lempel-Ziv 1977) および LZ78 (Lempel-Ziv 1978) の影響を強く受けていると言うのは正確ですが、LZMA はこれらのアルゴリズムの進化であり、大幅な機能強化が組み込まれていると表現する方が正確です。
- レンジ エンコーディング: LZMA は、ハフマン コーディングを、より効率的なデータ表現方法であるレンジ エンコーディングに置き換えます。
- 距離履歴: LZMA は頻繁に使用される距離の履歴を保持し、一致検出を高速化します。
- ハッシュ テーブル: LZMA は、一致するシーケンスの検索を迅速化するためにハッシュ テーブルを採用します。
- 予測モデリング: LZMA には、今後のデータ パターンを予測する予測モデリング技術が組み込まれており、圧縮をさらに強化します。
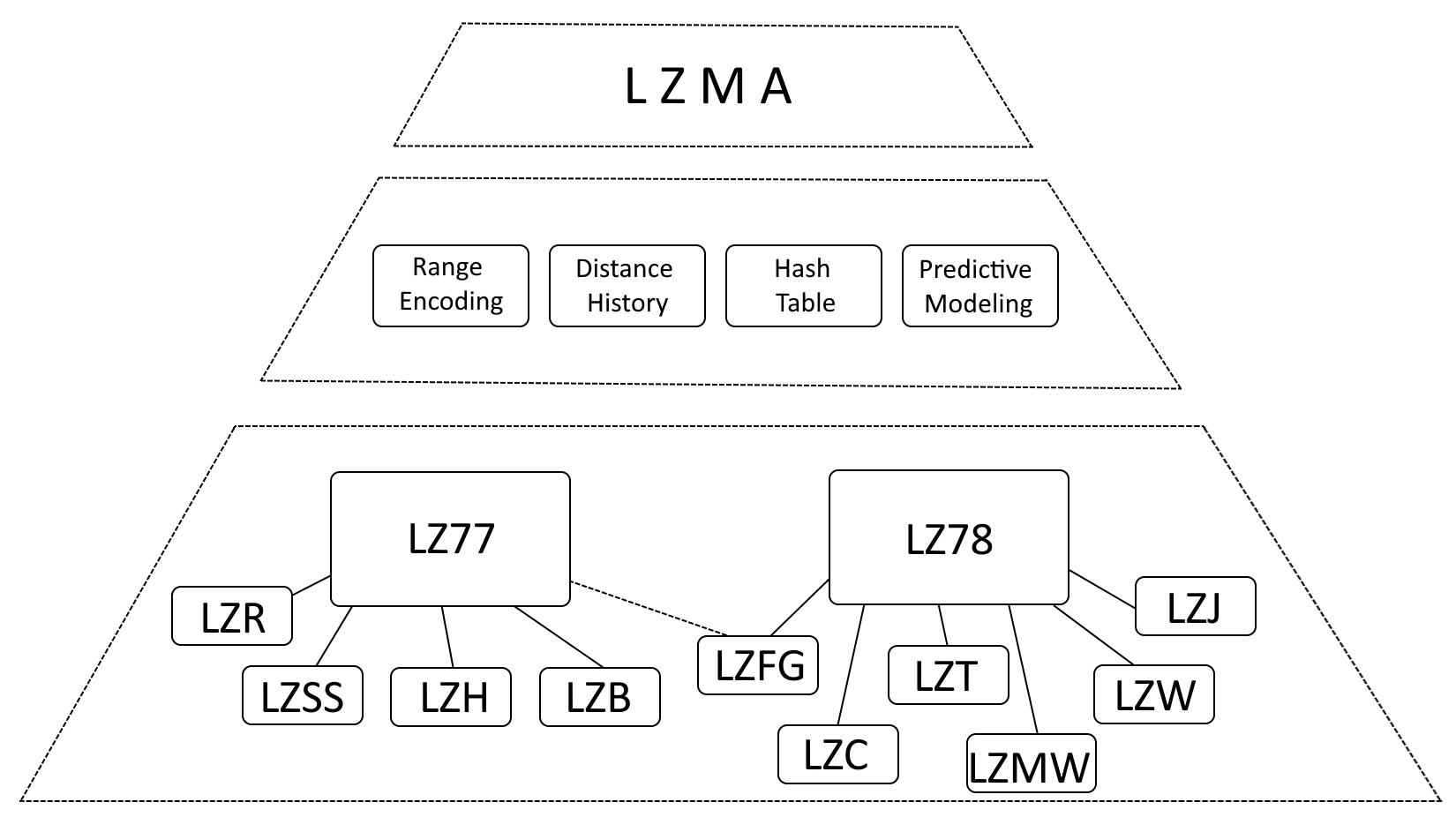
LZMA 内部アーカイブ構造
- ファイル メタデータ - tar アーカイブと同様に、各ファイルには変更時間やアクセス許可などの基本情報が保存されます。ただし、このセクションは柔軟であり、ニーズに応じて、アクセス コントロール リスト (ACL) や拡張属性 (EA) などの追加の詳細を省略したり、追加したりできます。データの整合性を確保するために、通常のファイルには強力なハッシュ関数 (SHA1 など) を含めることをお勧めします。
- 複数のコンテンツ ストリーム - 従来のアーカイブとは異なり、ファイルは内部データ ファイル内に複数のデータ ストリームを持つことができます。これは、ファイルに関連付けられた拡張属性またはリソース フォークを保存するのに役立ちます。
- ヘッダー - 内部インデックス ファイルはファイル ヘッダーを保持し、内部データ ファイル全体に散在するヘッダーをミラーリングします。ただし、個別に保存する場合、インデックス ヘッダーはデータ ファイル内の対応するデータの開始位置を参照する必要があります。さらに、インデックス内のディレクトリ エントリには、それに含まれるファイルと、内部ファイル インデックス内の対応するオフセットがリストされます。
- 重複メタデータの理論的根拠 - この設計選択により、効率的なデータ ストリーミング/デコードとランダム ファイル アクセスの両方が保証されます。さらに、メタデータは適切に圧縮されるため、ストレージのオーバーヘッドが最小限に抑えられます。テストによると、メタデータが占有するストレージ容量は通常 0.3% 未満であるため、トレードオフを行う価値はあります。
- ブロック ヘッダー - ブロック ヘッダーには、外部ファイルと同様に、ブロック サイズ情報と一意の識別子のシーケンスが含まれています。
LZMA Python の使用例
Aspose.ZIP via Python API を使用すると、アプリケーションで LZMA アーカイブを簡単に管理できるため、他の外部ソフトウェアが必要なくなります。 API には、LZMA アーカイブの操作を簡素化する LzmaArchive クラス と LzmaCompressionSettings クラス を使用すると、最適なパフォーマンスとファイル サイズの削減のために圧縮設定をカスタマイズできます。
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
LZMA アーカイブに関する追加情報
h2: LZMA アーカイブに関する追加情報
人々は尋ねてきました
1. LZMA 圧縮を使用するファイル形式は何ですか?
LZMA はファイル形式そのものではなく、さまざまなアーカイブ形式内で使用される圧縮アルゴリズムです。一般的な例としては、7z、XZ、場合によっては ZIP などがあります。これらの拡張子を持つファイルが見つかった場合、LZM を使用して圧縮されている可能性があります。
2. LZMA はオープンソースですか?
はい、LZMA はオープンソース アルゴリズムであり、自由に使用したり、さまざまなソフトウェア ソリューションに統合したりできます。このオープンソースの性質が、その広範な採用と継続的な開発に貢献しています。
3. LZMA の代替手段には何がありますか?
いくつかの圧縮アルゴリズムには、異なるトレードオフがあります。 ZIP は圧縮と速度のバランスが取れており、BZIP2 は LZMA と比較して速度を犠牲にして高圧縮を提供します。一方、LZMA に基づく XZ は強力な圧縮を提供し、Linux 環境で一般的に使用されます。