LZ 파일 형식
LZ 아카이브의 주요 기능 - LZ 아카이브 열기, 압축, 추출 및 관리 방법
LZ 아카이브 형식
LZ는 효율적인 데이터 압축을 위해 설계된 아카이브 형식으로, 저장 공간을 줄이고 데이터 전송을 최적화하는 것이 중요한 환경에서 주로 사용됩니다. LZ(Lempel-Ziv) 압축 알고리즘을 활용하는 이 형식은 속도와 리소스 효율성에 중점을 두고 대용량 데이터를 압축하는 기능으로 잘 알려져 있습니다. LZ 아카이브는 빠른 압축 및 압축 해제 주기가 필요한 시나리오에서 특히 널리 사용되므로 소프트웨어 배포 및 실시간 데이터 처리 모두에 적합합니다.
일반 LZ 아카이브 정보
LZ 아카이브는 Lempel-Ziv 알고리즘을 기본 압축 방법으로 활용하는 압축 파일 형식입니다. 속도와 단순함으로 잘 알려진 LZ 아카이브는 최대 압축 비율보다 효율적인 압축을 우선시합니다. 따라서 실시간 데이터 처리 또는 임베디드 시스템과 같이 빠른 압축 및 압축 해제가 필요한 애플리케이션에 적합합니다. .lz 확장자는 LZ 압축 파일의 가장 일반적인 확장자입니다. hile LZ 아카이브는 빠른 압축을 제공하지만 압축 비율 및 메타데이터 측면에서 제한이 있어 대규모 데이터 세트를 아카이브하거나 파일 속성을 보존하는 데 적합하지 않습니다. ZIP, gzip 및 XZ와 같은 최신 압축 형식은 향상된 기능과 성능으로 인해 많은 응용 프로그램에서 LZ를 대체했습니다.
LZ 아카이브 역사
- 1977년: LZ77 알고리즘을 도입한 이스라엘 컴퓨터 과학자 Abraham Lempel과 Jacob Ziv가 LZ 압축의 기반을 마련했습니다. 이는 반복되는 데이터 패턴을 압축하기 위해 슬라이딩 윈도우를 사용하는 무손실 데이터 압축을 위해 최초로 널리 채택된 알고리즘이었습니다.
- 1978년: Lempel과 Ziv는 사전 기반 접근 방식을 활용한 LZ77보다 개선된 LZ78 알고리즘을 도입했습니다. 이 알고리즘은 압축 효율성을 더욱 향상시켰으며 이후의 많은 압축 기술에 영감을 주었습니다.
- 1984년: Terry Welch는 LZ78 알고리즘을 기반으로 LZW(Lempel-Ziv-Welch)를 개발했습니다. LZW는 Unix 압축 명령 및 GIF 이미지 형식의 사용을 통해 대중화되었습니다. LZW는 상용 응용 프로그램에서 최초로 널리 사용되는 압축 알고리즘 중 하나였습니다.
- 1990년대: LZ 알고리즘의 변형이 계속 발전하여 7z 및 XZ 와 같은 형식에 사용되는 LZMA (Lempel-Ziv-Markov 체인 알고리즘)와 같은 고급 압축 방법이 개발되었습니다. 더 높은 압축률을 제공합니다.
- 2000년대: LZ 기반 압축 기술, 특히 LZW가 다양한 파일 형식과 프로토콜에 내장되었지만 GIF와 같은 일부 압축 기술은 사용법에 영향을 미치는 특허 관련 문제에 직면했습니다.
- 2010년대: LZ 기반 알고리즘, 특히 LZMA 및 그 변형은 최신 압축 소프트웨어의 기반으로 남아 높은 압축 효율성과 합리적인 성능의 균형을 유지합니다. 그들은 소프트웨어 배포, 보관 및 데이터 저장에 계속해서 널리 사용되고 있습니다.
- 2020년대: LZ 형식은 특히 속도와 단순성이 우선시되는 환경에서 압축을 위한 안정적이고 효율적인 선택입니다.
LZ 아카이브의 특징
LZ 아카이브 형식은 광범위한 기능보다 속도를 우선시하는 간단한 구조를 고수합니다. 여기서 LZ 아카이브의 기본 구조는 오래된 압축 파일로 작업하고 압축 기술의 발전을 평가하는 데 중요합니다.
- 단일 파일 압축: 일반적으로 단일 파일을 .lz 아카이브로 압축합니다.
- LZW 알고리즘: Lempel-Ziv-Welch 압축 방식을 사용합니다.
- 메타데이터 부족: 원본 파일에 대한 메타데이터가 제한적이거나 전혀 저장되지 않습니다.
- 단순성: 형식의 간단한 구조는 빠른 압축 및 압축 해제 속도에 기여합니다.
LZ 아카이브 압축 방법
LZ 아카이브 형식은 단순성과 속도로 유명한 Lempel-Ziv(LZ) 알고리즘을 활용하므로 빠른 압축 및 압축 해제가 중요한 시나리오에서 선호됩니다. 다음은 LZ와 관련된 압축 방법의 개요입니다.
- Lempel-Ziv 알고리즘: LZ 아카이브 형식의 핵심은 반복되는 시퀀스를 더 짧은 코드로 대체하여 데이터의 중복성을 식별하고 제거하는 무손실 압축 방법인 LZ 알고리즘을 기반으로 합니다. LZ 알고리즘은 데이터를 처리하면서 시퀀스 사전을 구축하여 작동하므로 크고 반복적인 데이터 세트를 효율적으로 압축할 수 있습니다. 이 방법은 데이터 패턴이 일관되고 예측 가능한 시나리오에서 특히 효과적입니다.
- 슬라이딩 윈도우 기술: LZ 알고리즘은 일반적으로 고정 크기 윈도우가 입력 데이터 스트림 위로 이동하여 반복되는 시퀀스를 찾는 슬라이딩 윈도우 메커니즘을 사용합니다. 이 접근 방식을 사용하면 알고리즘이 관리 가능한 사전 크기를 유지하면서 여전히 상당한 압축을 달성할 수 있습니다. 슬라이딩 창은 압축 효율성과 메모리 사용량의 균형을 맞추는 데 중요한 역할을 하므로 LZ 방법은 리소스가 제한된 시스템에 적합합니다.
- 체크섬 및 오류 감지: LZ 형식은 압축에 중점을 두지만 CRC32와 같은 기본 체크섬 메커니즘을 통합하여 압축된 데이터의 무결성을 보장할 수도 있습니다. 이러한 체크섬은 저장 또는 전송 중에 발생할 수 있는 오류를 감지하여 압축이 풀린 데이터가 정확하고 손상되지 않도록 보장합니다.
- 선택적 향상: 일부 구현에서 LZ 압축 방법은 RLE(실행 길이 인코딩) 또는 델타 인코딩과 같은 추가 기술을 통해 향상될 수 있으며, 이는 압축된 데이터의 크기를 더욱 줄일 수 있습니다. 이러한 선택적 향상 기능은 아카이브 내의 특정 데이터 유형에 적용되어 이미지나 실행 코드와 같은 특정 콘텐츠 유형을 보다 효율적으로 압축할 수 있습니다.
.lz 지원되는 작업
Aspose.Zip은 .lz 아카이브 작업에 대한 포괄적인 지원을 제공하므로 압축 파일을 보다 쉽게 관리할 수 있습니다. 할 수 있는 작업은 다음과 같습니다.
- 전체 추출: 원본 콘텐츠의 무결성과 구조를 유지하면서 .lz 아카이브에서 모든 파일을 쉽게 추출합니다.
- 선택적 추출: .lz 아카이브 내의 특정 파일을 대상으로 하여 파일 이름이나 기타 기준에 따라 정확한 데이터 복구 또는 선택적 압축 해제가 가능합니다.
- 데이터 압축: 효율적인 LZMA2 압축 방법을 활용하여 파일 및 디렉터리에서 .lz 아카이브를 생성하여 파일 크기를 크게 줄입니다.
- 사용자 정의 압축 설정: 압축 수준과 기타 매개변수를 조정하여 압축 속도와 파일 크기 사이의 균형을 맞추고 특정 요구 사항에 맞게 프로세스를 조정합니다.
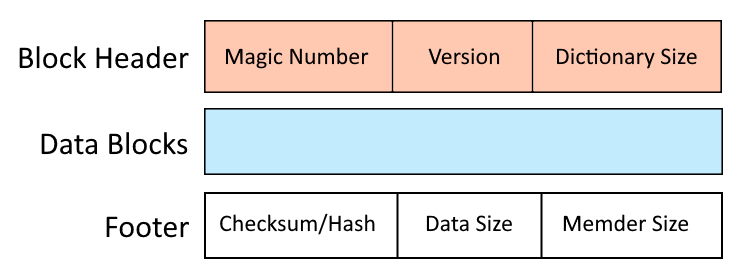
.LZ 파일의 구조
Lzip 아카이브 형식은 빠른 압축 및 압축 해제를 용이하게 하는 계층 구조를 활용하여 효율성과 속도에 중점을 두고 설계되었습니다. Lzip 아카이브는 아카이브에 하나씩 저장된 하나 이상의 구성원으로 구성됩니다. Lzip 구성원의 구조에는 다음 구성 요소가 포함됩니다.
블록 헤더:
- 매직 넘버: Lzip 아카이브의 시작을 알리는 고유 식별자로, 파일이 유효한 Lzip 형식으로 인식되도록 합니다.
- 버전 정보: 사용된 Lzip 버전을 표시하며, 이는 다양한 압축 해제 도구와의 추가 호환성을 보장하는 데 도움이 됩니다. 이제 값은 “1"입니다.
- 사전 크기: 이 필드는 향후 데이터 블록에 사용되는 LZMA 압축의 세부 정보에 대한 정보를 제공합니다.
압축된 데이터 블록:
- 압축된 페이로드: LZ 아카이브의 핵심으로, 이 섹션에는 압축된 데이터 스트림이 포함되어 있습니다. Lempel-Ziv-Markov 체인 알고리즘은 원본 데이터를 반복되는 시퀀스를 나타내는 일련의 코드로 처리하여 파일 크기를 크게 줄입니다. xz 및 7z 형식에서 동일한 압축 알고리즘이 지원됩니다.
블록 바닥글:
- 체크섬/해시: 압축된 데이터의 무결성을 확인하기 위해 체크섬(예: CRC32) 또는 암호화 해시(예: SHA-256)가 포함됩니다. 이는 전송 또는 저장 중에 아카이브가 변조되거나 손상되지 않았음을 보장합니다.
- 데이터 크기: 해당 블록에 압축된 원본 파일 조각의 크기입니다.
- Memder Size: 크기와 오프셋이 압축된 분산 인덱스의 일부로, 블록을 독립적으로 추출할 수 있습니다.
Lzip 형식은 여러 파일을 압축하지 않고 해당 메타데이터를 저장하지 않기 때문에 tar 유틸리티 조합과 함께 사용되는 경우가 많습니다.
LZ 형식의 인기
Lempel-Ziv 압축 알고리즘을 기반으로 하는 LZ 아카이브 형식은 데이터 압축 세계의 기본 기술이었습니다. 널리 채택된 이유는 단순성, 효율성, 특히 반복 패턴이 있는 데이터의 경우 상당한 압축 비율을 달성할 수 있는 능력 때문입니다. LZ 기반 압축 방법은 다양한 파일 형식 및 압축 도구에 통합되어 LZ 형식을 데이터 저장, 전송 및 보관 프로세스에서 다양하고 필수적인 구성 요소로 만듭니다. LZMA 및 Brotli와 같은 최신 압축 알고리즘이 등장했지만 압축 속도와 효율성의 균형으로 인해 LZ 형식은 여전히 관련성이 있습니다.
UNIX 및 Linux 환경에서 LZ 압축은 tar, 소프트웨어 배포 및 데이터 백업을 위한 압축 아카이브를 생성합니다. 수많은 압축 유틸리티에 통합되어 Windows 및 macOS를 포함한 다양한 플랫폼에서 지속적인 사용이 보장되었습니다. LZ 형식은 ZIP 또는 GZIP과 같은 다른 압축 형식만큼 널리 인식되지는 않지만 데이터 압축 기술에 대한 영향은 부인할 수 없으며 빠르고 안정적인 압축이 필요한 다양한 시나리오에서 계속 사용됩니다.
LZ 아카이브 사용 예
이 섹션에서는 C#, Java 및 Python.NET을 사용하여 LZ 아카이브를 압축하고 여는 방법을 보여주는 코드 예제를 제공합니다. 이러한 예제에서는 LZ 파일 관리를 위해 LzipArchive와 같은 라이브러리 및 클래스를 활용하며 최신 프로그래밍 환경에서 LZ 압축의 실제 사용을 보여줍니다.
Compresses a file into .LZ archive using the LzipArchive class in C#.
using (LzipArchive archive = new LzipArchive())
{
archive.SetSource("data.bin");
archive.Save("data.bin.lz");
}
Extract LZip Archive using C#
using (FileStream sourceLzipFile = File.Open("data.bin.lz", FileMode.Open))
{
using (FileStream extractedFile = File.Open("data.bin", FileMode.Create))
{
using (LzipArchive archive = new LzipArchive(sourceLzipFile))
{
archive.Extract(extractedFile);
}
}
}
Compresses a file into .LZ archive using the LzipArchive class in Java.
try (LzipArchive archive = new LzipArchive()) {
archive.setSource("data.bin");
archive.save("data.bin.lz");
}
Extract LZip Archive using Java
try (FileInputStream sourceLzipFile = new FileInputStream("data.bin.lz")) {
try (FileOutputStream extractedFile = new FileOutputStream("data.bin")) {
try (LzipArchive archive = new LzipArchive(sourceLzipFile)) {
archive.extract(extractedFile);
}
}
} catch (IOException ex) {
}
Compresses a file into .LZ archive using the LzipArchive class using Python.Net
with aspose.zip.lzip.LzipArchive() as archive:
archive.set_source("data.bin")
archive.save("data.bin.lz")
Extract Lzip Archive using Python.Net
with io.FileIO("data.bin.lz", "rb") as source_lzip_file:
with io.FileIO("data.bin", "x") as extracted_file:
with aspose.zip.lzip.LzipArchive(source_lzip_file) as archive:
archive.extract(extracted_file)
추가 정보
사람들이 물어봤어
1. LZ 아카이브 형식은 모든 운영 체제에서 지원됩니까?
LZ 아카이브 형식은 UNIX, Linux, Windows 및 macOS를 포함한 여러 플랫폼에서 지원됩니다. UNIX와 유사한 환경과 가장 일반적으로 연관되어 있지만 LZ 아카이브를 처리하는 도구 및 라이브러리는 모든 주요 운영 체제에서 사용할 수 있습니다.
2. LZ 아카이브를 사용하면 어떤 이점이 있나요?
LZ 아카이브는 반복되는 패턴으로 데이터를 압축하는 효율성으로 잘 알려져 있으며 압축 속도와 파일 크기 감소 간의 적절한 균형을 제공합니다. 구현이 쉬우므로 특히 소프트웨어 배포, 데이터 백업 및 네트워크 전송에서 빠른 데이터 압축 요구 사항에 대한 안정적인 선택이 됩니다.
3. 여러 파일을 단일 LZ 아카이브로 압축할 수 있나요?
LZ 형식은 일반적으로 단일 파일을 압축하는 데 사용됩니다. 여러 파일을 압축하려면 먼저 파일을 아카이브(예: tar를 사용하는 tarball)로 결합한 다음 결과 아카이브 파일을 LZ 압축으로 압축해야 합니다. 이 프로세스는 UNIX 및 Linux 환경에서 일반적입니다.