LZMA 파일 형식
LZMA 파일에 액세스, 수정, 생성, 압축 해제 및 변환하는 방법
LZMA 아카이브 파일 형식
LZMA(Lempel-Ziv-Markov 체인 알고리즘)는 높은 효율성과 탁월한 압축 비율로 유명한 최신 데이터 압축 알고리즘입니다.
7z
와 같은 아카이브 형식에 널리 사용되는 LZMA는 압축 해제 속도를 크게 희생하지 않고도 파일 크기를 효과적으로 줄입니다. LZMA 아카이브는 데이터 품질과 무결성의 보존을 보장하여 대규모 데이터 세트를 효율적으로 저장하고 관리하기 위한 완벽한 솔루션을 제공합니다.
LZMA의 가장 큰 장점은 손실을 최소화하면서 대용량 파일과 복잡한 데이터 구조를 처리할 수 있다는 것입니다. LZMA를 사용하면 디스크 공간을 최적화할 수 있으며 아카이브 크기가 작아 인터넷을 통한 파일 전송이 용이해집니다. 이로 인해 LZMA는 효율적인 데이터 관리를 위해 개발자와 시스템 관리자 사이에서 인기 있는 선택이 되었습니다.
LZMA 아카이브 정보 정보
LZMA 아카이브는 병렬화를 지원하므로 더 빠른 파일 압축 및 압축 해제를 위해 멀티 코어 프로세서를 효율적으로 사용할 수 있습니다. 또한 LZMA는 손상에 대한 저항성이 높은 것으로 알려져 있어 중요한 데이터를 장기간 보관할 때 신뢰할 수 있는 선택입니다. 또한 알고리즘에는 오픈 소스 코드가 있어 다양한 소프트웨어 솔루션에서 폭넓게 구현하고 적용할 수 있습니다. 이러한 장점으로 인해 LZMA는 가장 효율적인 압축 형식 중 하나로 남아 있으며 전 세계 사용자에게 최적의 데이터 관리를 제공합니다.
LZMA의 진화
1998년 Igor Pavlov가 7-Zip 프로젝트의 일부로 개발한 LZMA 알고리즘은 매우 효율적인 데이터 압축 방법을 만드는 것을 목표로 했습니다. 처음에는 압축 효율성을 크게 높이는 기술을 통합하여 클래식 LZ77 알고리즘을 기반으로 구축되었습니다. 점차적으로 LZMA는 최소한의 리소스 소비로 대규모 데이터 세트를 처리하는 능력을 인정받았습니다. 2001년에 LZMA는 7z 형식의 핵심 압축 알고리즘이 되었으며 뛰어난 성능으로 인해 빠르게 인기를 얻었습니다. 또한 이 알고리즘은 수많은 아카이버 및 데이터 저장 시스템, 특히 오픈 소스 소프트웨어 제품에 통합되었습니다. 오늘날 LZMA는 지속적인 업데이트와 최적화를 통해 관련성을 유지하면서 계속 발전하고 있으며 디지털 세계에서 없어서는 안 될 도구로서의 입지를 확고히 하고 있습니다.
LZMA 알고리즘의 원리
LZMA 알고리즘은 높은 수준의 압축을 달성하기 위해 데이터의 순차적 반복 사용을 기반으로 합니다. 알고리즘의 주요 아이디어는 이전에 발견된 하위 문자열을 포함하는 사전을 구축하고 저장한 다음 이 사전의 참조로 대체하는 것입니다. 이를 통해 저장하거나 전송할 데이터의 양을 크게 줄일 수 있습니다. LZMA의 주요 기능 중 하나는 허프만 코딩 대신 범위 인코딩을 사용한다는 것입니다. 범위 인코딩은 데이터의 엔트로피에 더 가까운 더 나은 압축을 제공하고 이진 형식을 활용하여 느린 정수 나누기 작업을 방지합니다.
LZMA는 LZ77 알고리즘을 사용하여 검색 버퍼와 예측 버퍼에서 가장 긴 일치 항목을 찾아 이를 삼중항(거리, 길이, 다음 문자) 형식으로 압축 파일에 씁니다. 일치하는 항목이 없으면 [0,255] 범위의 바이트가 파일에 추가됩니다. 일치하는 항목이 발견되면 범위 인코딩 방법으로 인코딩된 값 쌍(거리 및 길이)이 기록됩니다.
대규모 검색 버퍼의 효율성을 높이기 위해 알고리즘은 가장 일반적인 4개의 거리를 전용 거리 기록 배열에 저장합니다. 이러한 거리 중 하나라도 다시 나타나면 거리 기록 배열을 참조하는 2비트 코드로 대체되어 일치 항목을 저장하는 데 필요한 정보가 줄어듭니다.
LZMA는 2바이트 해시(현재 바이트와 다음 바이트)를 사용하여 검색 버퍼에서 일치하는 항목을 찾습니다. 해시 배열의 크기는 사전 크기와 직접적으로 연결됩니다. 예를 들어 1GB 사전은 512MB 해시 배열을 사용하여 해싱 함수의 충돌을 최소화합니다.
이 다단계 접근 방식은 상당한 리소스 소비 없이 효율적인 데이터 압축 및 저장을 제공하므로 LZMA는 가장 효율적인 데이터 압축 알고리즘 중 하나입니다.
.lzma 파일 형식의 이점
다음은 LZMA의 주요 장점으로, 많은 데이터 압축 애플리케이션에 매력적인 선택이 됩니다.
- 높은 압축률: LZMA는 기존 알고리즘 중 가장 높은 압축률을 제공하므로 파일 크기를 크게 줄일 수 있습니다. 평균 압축률은 다른 아카이브 형식에 비해 70%를 초과합니다.
- 빠른 압축 풀기: 이 알고리즘은 빠른 데이터 압축 풀기에 최적화되어 있어 LZMA는 빠른 데이터 검색이 필수적인 소프트웨어 애플리케이션 및 스토리지 시스템에 사용하기에 적합합니다.
- 효율적인 대용량 파일 관리: LZMA는 검색 버퍼의 크기가 크기 때문에 높은 압축률을 유지하면서 대용량 데이터를 효율적으로 처리할 수 있습니다.
- 신뢰성 및 손상 허용성: LZMA는 데이터 손상에 대한 높은 저항성을 제공합니다. 저장 또는 전송 중에 오류가 발생하더라도 일부 오류 수정이 가능하도록 설계되어 데이터 손실을 최소화하고 장기 저장 중에 정보의 무결성을 보장합니다.
- 오픈 소스 코드: LZMA 알고리즘의 오픈 소스 특성은 다양한 소프트웨어 솔루션에 대한 광범위한 구현, 적응 및 통합을 촉진하여 채택과 지속적인 개발을 촉진합니다.
LZMA 아카이브 지원 작업
Aspose.ZIP 을 사용하면 사용자가 개별 파일과 전체 아카이브를 모두 추출할 수 있습니다. .NET의 경우 LzmaArchiveClass 를 사용하여 .lzma 파일을 연 다음 해당 레코드를 단계별로 실행하고 원하는 위치에 추출할 수 있습니다. 유사한 접근 방식이 Java에서 사용됩니다. 여기서 LzmaArchive를 사용하여 .lzma 파일을 열고 레코드를 추출합니다. Aspose.ZIP 덕분에 이러한 작업은 모든 수준의 사용자에게 간단하고 편리해졌습니다.
LZMA 구조
LZMA가 LZ77(Lempel-Ziv 1977) 및 LZ78(Lempel-Ziv 1978)의 영향을 많이 받았다고 말하는 것이 정확하지만, LZMA를 상당한 개선 사항을 통합하여 이러한 알고리즘의 진화로 설명하는 것이 더 정확합니다.
- 범위 인코딩: LZMA는 허프만 코딩을 보다 효율적인 데이터 표현 방법인 범위 인코딩으로 대체합니다.
- 거리 기록: LZMA는 자주 사용되는 거리 기록을 유지하여 일치 검색을 가속화합니다.
- 해시 테이블: LZMA는 해시 테이블을 사용하여 일치하는 시퀀스를 신속하게 검색합니다.
- 예측 모델링: LZMA는 예측 모델링 기술을 통합하여 향후 데이터 패턴을 예측하고 압축을 더욱 향상시킵니다.
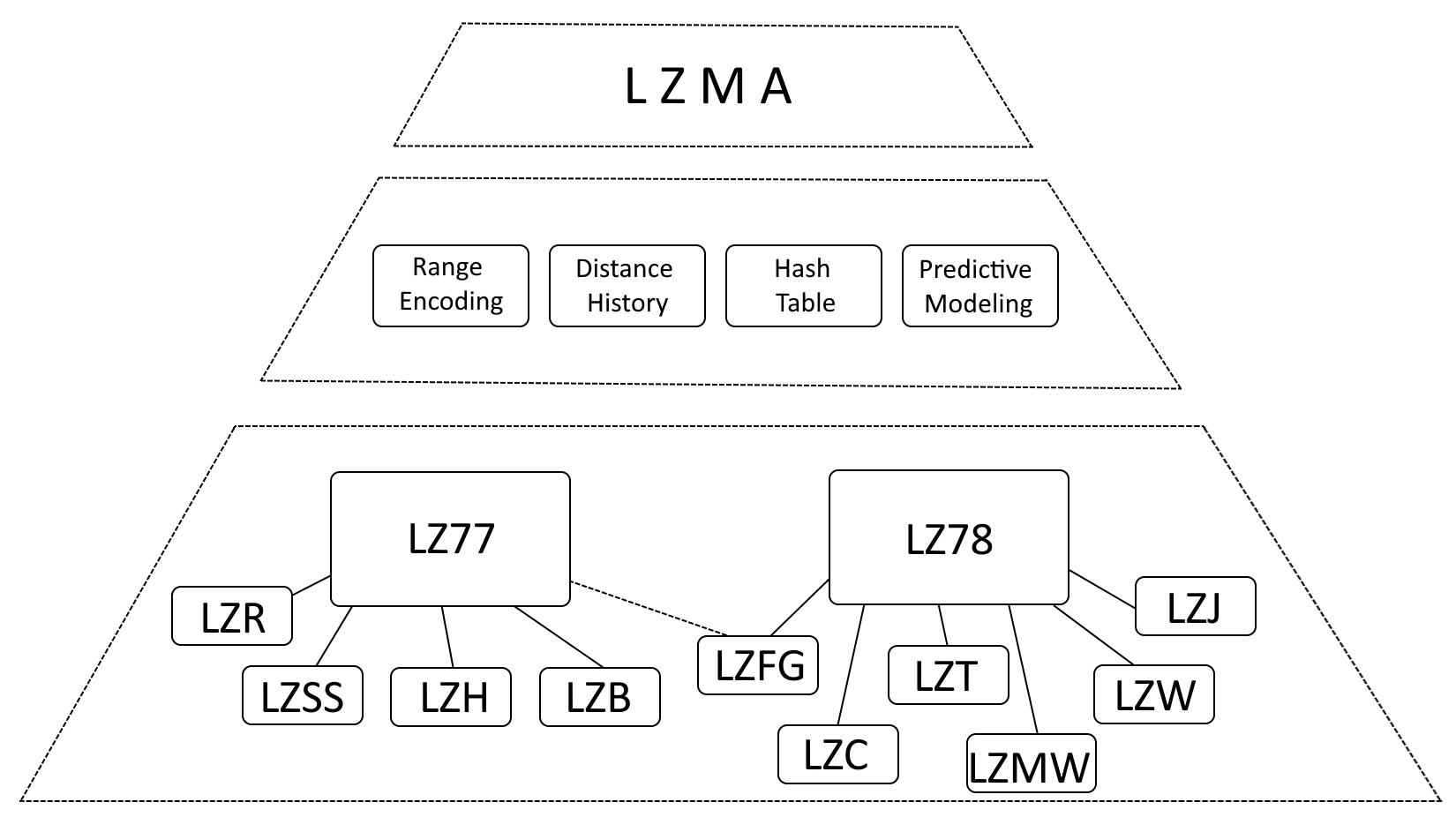
내부 LZMA 아카이브 구조
- 파일 메타데이터 - tar 아카이브와 유사하게 각 파일은 수정 시간 및 권한과 같은 기본 정보를 저장합니다. 그러나 이 섹션은 유연하며 필요에 따라 ACL(액세스 제어 목록) 또는 EA(확장 속성)와 같은 추가 세부 정보를 생략하거나 포함할 수 있습니다. 데이터 무결성을 보장하려면 일반 파일에 대해 강력한 해시 기능(예: SHA1)을 포함하는 것이 좋습니다.
- 다중 콘텐츠 스트림 - 기존 아카이브와 달리 파일은 내부 데이터 파일 내에 둘 이상의 데이터 스트림을 가질 수 있습니다. 이는 파일과 관련된 확장된 속성이나 리소스 포크를 저장하는 데 유용합니다.
- 헤더 - 내부 인덱스 파일에는 파일 헤더가 포함되어 있으며 내부 데이터 파일 전체에 흩어져 있는 헤더를 미러링합니다. 그러나 별도로 저장되는 경우 인덱스 헤더는 데이터 파일 내 해당 데이터의 시작 위치를 참조해야 합니다. 또한 인덱스의 디렉터리 항목에는 포함된 파일과 내부 파일 인덱스 내의 해당 오프셋이 나열됩니다.
- 중복 메타데이터의 이론적 근거 - 이 설계 선택은 효율적인 데이터 스트리밍/디코딩과 임의 파일 액세스를 모두 보장합니다. 또한 메타데이터가 잘 압축되므로 스토리지 오버헤드가 최소화됩니다. 테스트에 따르면 메타데이터는 일반적으로 저장 공간의 0.3% 미만을 차지하므로 절충할 가치가 있습니다.
- 블록 헤더 - 블록 헤더는 외부 파일과 유사하며 블록 크기 정보와 고유 식별자 시퀀스를 포함합니다.
LZMA Python 사용 예
Python을 통한 Aspose.ZIP API를 사용하면 다른 외부 소프트웨어가 필요 없이 애플리케이션에서 LZMA 아카이브를 쉽게 관리할 수 있습니다. API에는 LZMA 아카이브 작업을 단순화하는 LzmaArchive 클래스 와 LzmaCompressionSettings 클래스 가 포함되어 있습니다. , 최적의 성능과 파일 크기 감소를 위해 압축 설정을 사용자 정의할 수 있습니다.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
LZMA 아카이브에 대한 추가 정보
사람들이 물어봤어
1. LZMA 압축을 사용하는 파일 형식은 무엇입니까?
LZMA는 파일 형식 자체가 아니라 다양한 아카이브 형식 내에서 사용되는 압축 알고리즘입니다. 몇 가지 일반적인 예로는 7z, XZ 및 경우에 따라 ZIP이 있습니다. 이러한 확장자를 가진 파일이 발견되면 LZM을 사용하여 압축될 수 있습니다.
2. LZMA는 오픈 소스인가요?
예, LZMA는 오픈 소스 알고리즘이므로 다양한 소프트웨어 솔루션에 자유롭게 사용하고 통합할 수 있습니다. 이러한 오픈 소스 특성은 광범위한 채택과 지속적인 개발에 기여했습니다.
3. LZMA의 대안은 무엇입니까?
여러 압축 알고리즘은 서로 다른 장단점을 제공합니다. ZIP은 압축과 속도의 균형이 잘 맞고, BZIP2는 LZMA에 비해 속도는 떨어지지만 높은 압축을 제공하는 반면, LZMA를 기반으로 하는 XZ는 강력한 압축을 제공하여 Linux 환경에서 흔히 사용됩니다.