GZIP File Format Family
How to access, modify, generate, and transform GZIP files
GZIP Archive Format
GZIP is a popular file format and software application used for file compression and decompression. It was developed as a free and open-source compression algorithm by Jean-Loup Gailly and Mark Adler in the early 1990s. The name "GZIP" stands for GNU ZIP, indicating its association with the GNU Project.
GZIP compression works by reducing the size of files, making them easier to transfer over networks or store on disk. It achieves compression by replacing repeated strings of data with references, thereby reducing redundancy and overall file size. GZIP is particularly efficient for compressing text-based files like HTML, CSS, JavaScript, XML, and JSON, but it can also be used for compressing other types of files.
About GZIP Archive Information
GZIP archive information refers to the metadata and data contained within a file compressed using the GZIP compression algorithm. GZIP archives typically include information such as file attributes, timestamps, compression method, and other relevant data necessary for decompression and file restoration. This metadata is crucial for properly identifying and processing the compressed files.
Additionally, GZIP archive information may also include details about the compression process itself, such as compression level, checksums, and any additional flags or options used during compression. This information is essential for ensuring the integrity and correctness of the compressed data when decompressing it. Overall, understanding GZIP archive information is vital for effectively managing and working with compressed files, whether for data storage, transmission over networks, or archival purposes.
Evolution of the GZIP Archive Format
The GZIP archive format has its roots in the late 1980s when Jean-loup Gailly and Mark Adler developed the GZIP compression algorithm as part of the GNU project. GZIP stands for GNU ZIP, reflecting its origins within the GNU project. The goal was to create a compression tool that could efficiently reduce the size of files while maintaining compatibility across different computer systems.
Jean-loup Gailly and Mark Adler developed the program as a free alternative to the compress utility found in early Unix systems. It was designed to be part of the GNU project, hence the “g” in gzip. The initial release, version 0.1, became available to the public on October 31, 1992, followed by version 1.0 in February 1993.
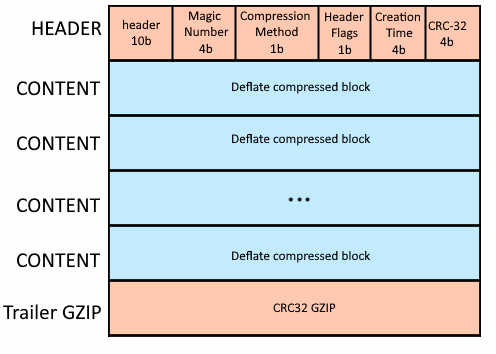
GZIP Structure
GZIP utilizes the DEFLATE algorithm, which merges LZ77 and Huffman coding techniques. DEFLATE was developed to supersede LZW and other compression algorithms encumbered by patents, which constrained the effectiveness of compress and similar archiving utilities prevalent at that time. The GZIP file format follows a well-defined structure consisting of three main parts:
- Header (10 bytes): This section provides essential information about the archive and its contents. Here’s a breakdown of the header data
- Magic Number (4 bytes): This identifies the file as a GZIP archive. It has a specific hexadecimal value (1f 8b) that decompression tools recognize.
- Compression Method (1 byte): This byte typically holds the value 8, indicating the DEFLATE compression algorithm used by GZIP.
- Header Flags (1 byte): These flags control specific aspects of decompression, such as file name encoding or the presence of a comment.
- Creation Time (4 bytes): This section stores a Unix timestamp indicating the time the archive was created.
- CRC-32 (4 bytes): This Cyclic Redundancy Check value is used for error detection during decompression. It’s calculated based on the uncompressed data and allows the decompressing software to verify the integrity of the extracted files.
Benefits of this format
- Lossless Compression: GZIP compresses data without any loss of information. Unlike some compression techniques, the original files can be perfectly reconstructed after decompression. This is crucial for important documents, images, or code where maintaining data integrity is essential.
- Wide Compatibility: One of GZIP biggest strengths is its widespread adoption. It’s supported by most operating systems, archive utilities (WinRAR, 7-Zip), and web servers. This ensures you can easily open GZIP files on various platforms without needing specific software. Also GZIP is widely supported across various operating systems, including Unix-based systems, Linux, Windows, and macOS. This cross-platform compatibility ensures that GZIP-compressed files can be created and decompressed seamlessly across different environments.
- Streamable Compression: GZIP supports stream compression, allowing files to be compressed or decompressed on-the-fly without needing to wait for the entire file to be processed. This makes it suitable for scenarios where data is generated or transmitted continuously, such as network communication and data backup operations.
- Open Standard: GZIP is an open and widely adopted standard for file compression, with specifications publicly available. This openness encourages interoperability and compatibility among different software applications and systems, fostering a vibrant ecosystem of tools and libraries for working with GZIP-compressed files. Utilizing GZIP is generally straightforward. Many tools and software automatically compress or decompress files in this format. Additionally, the decompression process is efficient and requires minimal resources.
GZIP Archive Supported Operations
Aspose.ZIP allows user extract either particular entry or whole archive. For Aspose.ZIP for .NET You can use the GzipArchiveClass to open the .gz file and then iterate through its entries, extracting them to a desired location. For Aspose.ZIP for Java Similar approach using the GzipArchive to open the .gz file and extract entries.
GZIP-file - Internal Structure
The GZIP archive is like a neatly wrapped package. It starts with a 10-byte header introducing the format and compression method. The heart lies in the compressed data section, shrunk using clever algorithms. Finally, an 8-byte footer verifies data integrity with checksums, ensuring your files arrive safely after decompression.
Inner Archive Structure
- File Metadata - Similar to a tar archive, each file stores basic information like modification time and permissions. However, this section is flexible and allows omitting or including additional details like access control lists (ACLs) or extended attributes (EAs) based on your needs. It’s recommended to include a strong hash function (like SHA1) for regular files to ensure data integrity.
- Multiple Content Streams - Unlike traditional archives, files can have more than one data stream within the inner data file. This is useful for storing extended attributes or resource forks associated with the file.
- Headers - The inner index file holds file headers, mirroring those scattered throughout the inner data file. But, when stored separately, the index headers must reference the starting position of their corresponding data within the data file. Additionally, directory entries in the index list their contained files and their corresponding offsets within the inner file index.
- Rationale for Duplicate Metadata - This design choice ensures both efficient data streaming/decoding and random file access. Additionally, metadata compresses well, resulting in minimal storage overhead. Tests show metadata typically occupies less than 0.3% of storage space, making the trade-off worthwhile.
- Block Headers - Block headers, similar to the outer file, contain block size information and a unique identifier sequence.
Examples of Using GZIP
Aspose.ZIP API lets extract archives in your applications without the need of any other 3rd party applications. Aspose.ZIP API provides GzipArchive class to work with GZIP archives.
GZIP with compress only single source via C#
Such archives like GZIP, LZ, BZIP2, XZ, Z do not support entries and can compress only single source. See samples with such a compression.
using (FileStream source = File.Open("alice29.txt", FileMode.Open, FileAccess.Read))
{
using (GzipArchive archive = new GzipArchive())
{
archive.SetSource(source);
archive.Save(«archive.gz”);
}
}
Additional information about GZIP-archives
People have been asking
1. What is GZIP?
GZIP (GNU zipped archive) is a popular file format that shrinks the size of files for easier storage and transmission.
2. How does GZIP compression compare to other formats like ZIP?
GZIP typically offers higher compression ratios compared to ZIP, especially when compressing text-based files. However, ZIP archives often include support for multiple files and directories, making them more versatile for packaging multiple files together.
3. Can GZIP compress multiple files into a single archive?
GZIP is designed to compress a single file, not multiple files or directories. However, it is common to use tools like tar in combination with GZIP to create a tarball tar archive and then compress it using GZIP to create a single compressed file.