LZ File Format
Key Features of LZ Archives - How to Open, Compress, Extract, and Manage LZ Archives
LZ Archive Format
LZ is an archive format designed for efficient data compression, primarily utilized in environments where reducing storage space and optimizing data transfer are critical. Leveraging the Lempel-Ziv (LZ) compression algorithm, this format is known for its ability to compress large volumes of data with a focus on speed and resource efficiency. LZ archives are particularly popular in scenarios that require fast compression and decompression cycles, making them suitable for both software distribution and real-time data processing.
General LZ Archive Information
LZ archives are compressed file formats that utilize the Lempel-Ziv algorithm as their primary compression method. Known for their speed and simplicity, LZ archives prioritize efficient compression over maximum compression ratios. This makes them suitable for applications demanding rapid compression and decompression, such as real-time data processing or embedded systems. .lz extension is the most common extension for LZ compressed files. hile LZ archives offer swift compression, their limitations in terms of compression ratio and metadata make them less suitable for archiving large datasets or preserving file attributes. Modern compression formats like ZIP, gzip, and XZ have superseded LZ in many applications due to their enhanced features and performance.
LZ Archives History
- 1977: The foundation for LZ compression was laid by Israeli computer scientists Abraham Lempel and Jacob Ziv, who introduced the LZ77 algorithm. This was the first widely adopted algorithm for lossless data compression, using a sliding window to compress repeated data patterns.
- 1978: Lempel and Ziv introduced the LZ78 algorithm, an improvement over LZ77, which utilized a dictionary-based approach. This algorithm further enhanced compression efficiency and inspired many subsequent compression techniques.
- 1984: Terry Welch built upon the LZ78 algorithm to develop LZW (Lempel-Ziv-Welch), which became popularized through its use in the Unix compress command and GIF image format. LZW was one of the first widely used compression algorithms in commercial applications.
- 1990s: Variants of the LZ algorithm continued to evolve, leading to the development of more advanced compression methods like LZMA (Lempel-Ziv-Markov chain algorithm) used in formats like 7z and XZ , which offer higher compression ratios.
- 2000s: LZ-based compression techniques, particularly LZW, became embedded in many file formats and protocols, though some, like GIF, encountered patent-related issues that influenced their usage.
- 2010s: LZ-based algorithms, particularly LZMA and its variants, remain foundational in modern compression software, balancing high compression efficiency with reasonable performance. They continue to be widely used in software distribution, archiving, and data storage.
- 2020s: The LZ format continues to be a reliable and efficient choice for compression, especially in environments where speed and simplicity are prioritized.
Characteristics of LZ archive
The LZ archive format adheres to a straightforward structure, prioritizing speed over extensive features. Here, the basic structure of the LZ archive is important for working with old compressed files and evaluating the evolution of compression technologies.
- Single-file Compression: Typically compresses a single file into a .lz archive.
- LZW Algorithm: Employs the Lempel-Ziv-Welch compression method.
- Lack of Metadata: Limited or no metadata about the original file is stored within the archive.
- Simplicity: The format’s straightforward structure contributes to its fast compression and decompression speeds.
LZ Archives Compression Methods
The LZ archive format utilizes the Lempel-Ziv (LZ) algorithm, which is renowned for its simplicity and speed, making it a preferred choice in scenarios where quick compression and decompression are critical. Below is an overview of the compression methods associated with LZ:
- Lempel-Ziv Algorithm: The core of the LZ archive format is based on the LZ algorithm, a lossless compression method that identifies and eliminates redundancy in data by replacing repeated sequences with shorter codes. The LZ algorithm works by building a dictionary of sequences as it processes the data, allowing for efficient compression of large and repetitive datasets. This method is particularly effective in scenarios where data patterns are consistent and predictable.
- Sliding Window Technique: The LZ algorithm typically employs a sliding window mechanism, where a fixed-size window moves over the input data stream to find repeated sequences. This approach allows the algorithm to maintain a manageable dictionary size while still achieving significant compression. The sliding window is instrumental in balancing compression efficiency with memory usage, making the LZ method suitable for systems with limited resources.
- Checksum and Error Detection: While the LZ format focuses on compression, it may also incorporate basic checksum mechanisms such as CRC32 to ensure the integrity of the compressed data. These checksums help detect errors that might occur during storage or transmission, ensuring that the decompressed data remains accurate and uncorrupted.
- Optional Enhancements: In some implementations, the LZ compression method can be enhanced with additional techniques like run-length encoding (RLE) or delta encoding, which can further reduce the size of the compressed data. These optional enhancements are applied to specific types of data within the archive, allowing for more efficient compression of certain content types, such as images or executable code.
.lz Supported Operations
Aspose.Zip offers comprehensive support for working with .lz archives, making it easier to manage compressed files. Here’s what you can do:
- Full Extraction: Easily extract all files from an .lz archive, preserving the integrity and structure of the original content.
- Selective Extraction: Target specific files within an .lz archive, allowing for precise data recovery or selective decompression based on file names or other criteria.
- Data Compression: Create .lz archives from files and directories, utilizing the efficient LZMA2 compression method to reduce file sizes significantly.
- Custom Compression Settings: Adjust compression levels and other parameters to balance between compression speed and file size, tailoring the process to your specific needs.
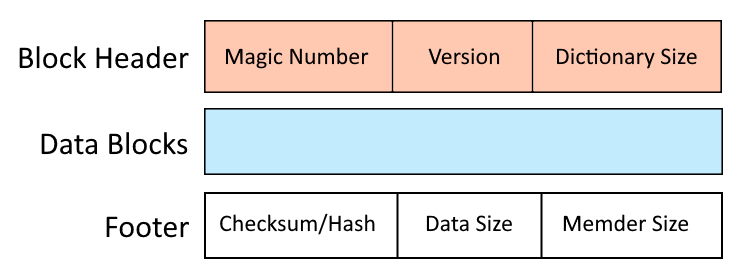
Structure of .LZ File
The Lzip archive format is designed with a focus on efficiency and speed, utilizing a layered structure that facilitates quick compression and decompression. Lzip archive consists of one or several members stored in the archive one by one. The structure of a Lzip member includes the following components:
Block Header:
- Magic Number: A unique identifier that signals the beginning of the Lzip archive, ensuring that the file is recognized as a valid Lzip format.
- Version Information: Indicates the version of the Lzip used, which helps in ensuring futher compatibility with different decompression tools. Now it has value “1”.
- Dictionary Size: This field provides information about the details of LZMA compression used for upcoming data block.
Compressed Data Block:
- Compressed Payload: The core of the LZ archive, this section contains the compressed data stream. The Lempel-Ziv-Markov chain algorithm processes the original data into a series of codes that represent repeated sequences, significantly reducing the file size. Same compression algorithm is supported in xz and 7z formats.
Block Footer:
- Checksum/Hash: A checksum (such as CRC32) or cryptographic hash (like SHA-256) is included to verify the integrity of the compressed data. This ensures that the archive has not been tampered with or corrupted during transmission or storage.
- Data Size: A size of a piece of the original file compressed in this block.
- Memder Size: a part of distributed index with compressed size and offset, which allows to extract blocks independently.
Since Lzip format does not compress multiple files and does not store its metadata, it oftetn used with combination tar utility.
Popularity of the LZ Format
The LZ archive format, based on the Lempel-Ziv compression algorithm, has been a foundational technology in the world of data compression. Its widespread adoption is attributed to its simplicity, efficiency, and ability to achieve significant compression ratios, particularly for data with repeating patterns. LZ-based compression methods have been incorporated into various file formats and compression tools, making the LZ format a versatile and essential component in data storage, transmission, and archival processes. Although newer compression algorithms like LZMA and Brotli have emerged, the LZ format remains relevant due to its balance of compression speed and effectiveness.
In UNIX and Linux environments, LZ compression is often used in conjunction with other tools, such as tar, to create compressed archives for software distribution and data backup. Its integration into numerous compression utilities has ensured its ongoing use across diverse platforms, including Windows and macOS. While the LZ format may not be as widely recognized as other compression formats like ZIP or GZIP, its influence on data compression technology is undeniable, and it continues to be employed in various scenarios where fast, reliable compression is necessary.
Examples of Using LZ Archives
This section provides code examples demonstrating how to compress and open LZ archives using C#, Java and Python.NET. These examples utilize libraries and classes such as LzipArchive for managing LZ files, illustrating the practical use of LZ compression in modern programming environments.
Compresses a file into .LZ archive using the LzipArchive class in C#.
using (LzipArchive archive = new LzipArchive())
{
archive.SetSource("data.bin");
archive.Save("data.bin.lz");
}
Extract LZip Archive using C#
using (FileStream sourceLzipFile = File.Open("data.bin.lz", FileMode.Open))
{
using (FileStream extractedFile = File.Open("data.bin", FileMode.Create))
{
using (LzipArchive archive = new LzipArchive(sourceLzipFile))
{
archive.Extract(extractedFile);
}
}
}
Compresses a file into .LZ archive using the LzipArchive class in Java.
try (LzipArchive archive = new LzipArchive()) {
archive.setSource("data.bin");
archive.save("data.bin.lz");
}
Extract LZip Archive using Java
try (FileInputStream sourceLzipFile = new FileInputStream("data.bin.lz")) {
try (FileOutputStream extractedFile = new FileOutputStream("data.bin")) {
try (LzipArchive archive = new LzipArchive(sourceLzipFile)) {
archive.extract(extractedFile);
}
}
} catch (IOException ex) {
}
Compresses a file into .LZ archive using the LzipArchive class using Python.Net
with aspose.zip.lzip.LzipArchive() as archive:
archive.set_source("data.bin")
archive.save("data.bin.lz")
Extract Lzip Archive using Python.Net
with io.FileIO("data.bin.lz", "rb") as source_lzip_file:
with io.FileIO("data.bin", "x") as extracted_file:
with aspose.zip.lzip.LzipArchive(source_lzip_file) as archive:
archive.extract(extracted_file)
Additional information
People have been asking
1. Is the LZ archive format supported on all operating systems?
The LZ archive format is supported across multiple platforms, including UNIX, Linux, Windows, and macOS. While it is most commonly associated with UNIX-like environments, tools and libraries that handle LZ archives are available for all major operating systems.
2. What are the advantages of using LZ archives?
LZ archives are known for their efficiency in compressing data with repeated patterns, offering a good balance between compression speed and file size reduction. They are easy to implement, making them a reliable choice for fast data compression needs, particularly in software distribution, data backup, and network transmission.
3. Can I compress multiple files into a single LZ archive?
The LZ format is typically used for compressing single files. To compress multiple files, you would first need to combine them into an archive (such as a tarball using tar), and then compress the resulting archive file with LZ compression. This process is common in UNIX and Linux environments.