Z File Format
Key Features of Z File - How to Open, Compress, Extract, and Manage Z Archives
Z Archive Format
The Z file format is a legacy compression format that was widely used on UNIX systems during the 1980s and 1990s. It uses the Lempel-Ziv-Welch (LZW) algorithm to compress files, significantly reducing their size while maintaining data integrity. Although largely supplanted by more modern formats like gzip and bzip2, Z files are still encountered in legacy systems and archives.
General Z Archive Information
Z archives are a legacy file compression format primarily used on UNIX and early Linux systems. They employ the Lempel-Ziv-Welch (LZW) algorithm, which was a groundbreaking method of data compression when it was introduced. The Z format is designed to reduce the size of files by encoding repetitive data patterns efficiently, making it useful for conserving disk space and bandwidth in the era of limited storage capacity. Z archives typically compress individual files rather than entire directories, though they can be combined with tools like tar to archive and compress multiple files at once. While the Z format has largely been replaced by more modern compression methods, it remains an important part of computing history and is still encountered in some older software archives and UNIX-based systems.
Z Archive History Info
- 1980s: The Z format was developed during the early days of UNIX as a means to efficiently compress files and save on storage space, which was a precious resource at the time.
- 1983: The compress utility, which creates Z archives, was introduced as part of the UNIX operating system. It quickly became a standard tool for file compression in UNIX environments.
- Late 1980s: As UNIX systems became more widespread, the Z format saw extensive use in software distribution, particularly for sending and storing large files across networks.
- 1990s: The introduction of more advanced compression formats like gzip and bzip2 began to supplant the Z format due to their higher compression ratios and additional features.
- 2000s: While the Z format fell out of favor for most modern applications, it continued to be supported in UNIX and Linux systems for backward compatibility with older software.
- Present: Although largely obsolete, the Z format is still encountered in legacy systems and some specific use cases where compatibility with older UNIX tools is required.
Structure of Z archive
The Z archive format is relatively simple compared to more modern compression formats. It was designed for single-file compression and lacks some of the advanced features found in newer formats. Here’s an overview of the structure of a Z archive:
- Header: The header of a Z archive contains basic metadata, including a magic number (0x1f9d) that identifies the file as a Z archive. It may also include some control flags that dictate the compression parameters, though these are minimal compared to modern formats.
- Compressed Data Stream: The main component of the Z archive is the compressed data stream, where the file data is stored after being processed by the LZW (Lempel-Ziv-Welch) compression algorithm. The data is compressed in a single continuous stream, which means the entire file needs to be decompressed to access any part of the data.
- End of File (EOF) Marker: The Z format does not have a formal footer like some other formats. Instead, the end of the compressed data stream marks the conclusion of the archive. There are no built-in checksums or integrity verification features in the basic Z format.
Z Compression Methods
The Z format relies solely on the LZW (Lempel-Ziv-Welch) algorithm for compression. This method was innovative for its time and is notable for its balance of simplicity and efficiency. Here’s a closer look at the compression method used in Z archives:
- LZW Compression: The LZW algorithm is a dictionary-based compression technique that replaces repetitive sequences of data with shorter codes, reducing the overall file size. It is a lossless compression method, meaning that the original data can be perfectly reconstructed from the compressed file. LZW became popular in the early days of file compression due to its relatively fast compression and decompression speeds.
- No Additional Filters or Methods: Unlike modern compression formats that may support various filters and additional compression methods, the Z format uses only LZW with no optional filters or enhancements. This simplicity is both a strength and a limitation, as it makes the format easy to implement but less flexible and efficient compared to newer formats.
- No Integrity Checks: The Z format does not include built-in checksum mechanisms like CRC32 or SHA-256 for verifying data integrity. As a result, detecting corruption within a Z archive is more challenging, relying instead on external methods or the behavior of the decompression process.
.Z Extension Supported Operations
Aspose.ZIP offers comprehensive support for working with Z archives, commonly used in Unix-like operating systems. This functionality simplifies management and manipulation of compressed files within your applications. Here’s how Aspose.ZIP empowers you:
- Extraction Z archives: Extract all contents from a .z archive with ease. Aspose.ZIP ensures the integrity and original structure of your data are maintained during the extraction process.
- Precise Selective Extraction: Target specific files within a .z archive for extraction. This allows you to recover data selectively based on file names or other criteria, optimizing your workflow and saving time.
- Streamlined Compression: Create Z archives from files and directories directly within your applications. Aspose.ZIP utilizes the efficient LZMA2 compression method to significantly reduce file sizes, saving valuable storage space. Leverage this functionality for archiving data, backups, or efficient file transmission.
- Customization Options: Fine-tune your compression process by adjusting compression levels and other parameters. Aspose.ZIP allows you to strike a balance between compression speed and resulting file size. You can tailor the process to optimize for faster compression or achieve maximum compression for specific needs.
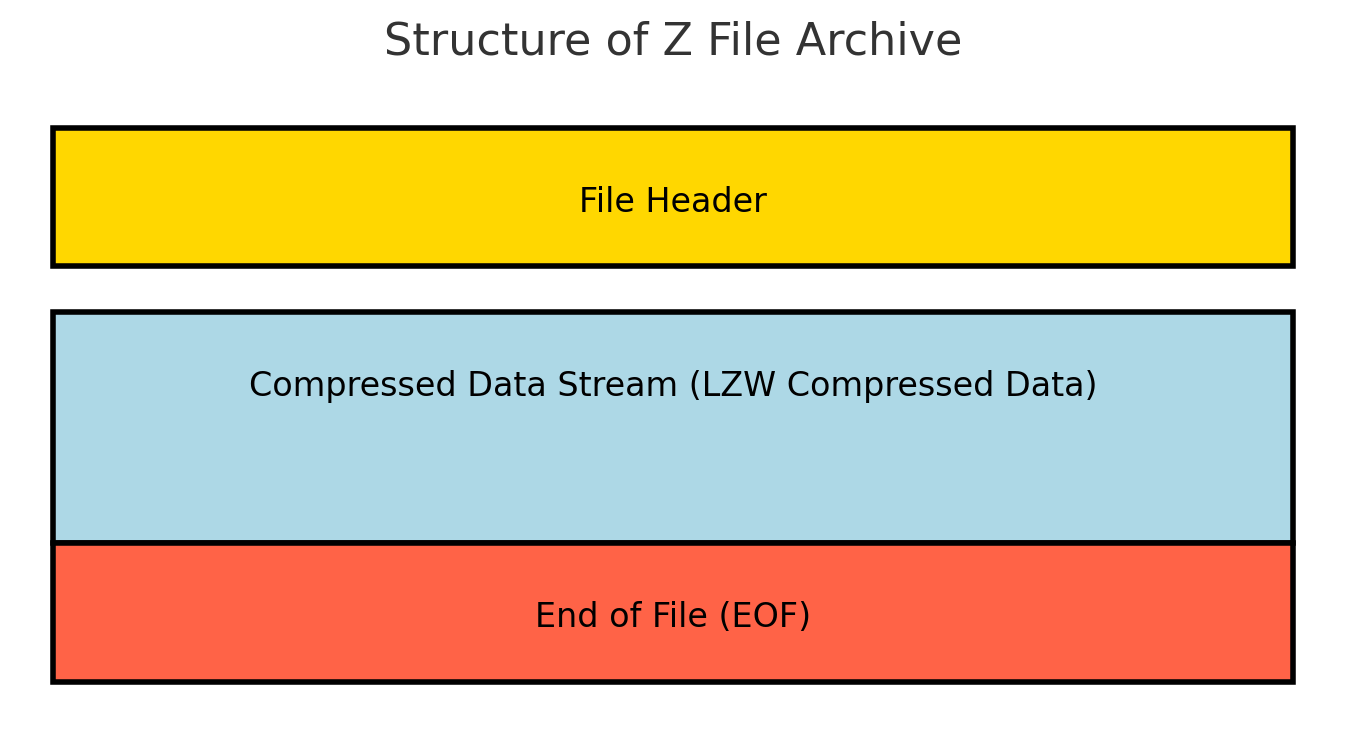
Structure of Z File Archive
The .Z file format, a legacy compression method, is structured to provide basic, efficient compression using the LZW algorithm. While simpler than modern like formats .xz , the Z file structure is still crucial for understanding how data was handled in early UNIX systems. Here’s an overview of the structure of a .Z archive:
File Header:
- Magic Bytes: The file begins with a magic number (0x1f9d), which identifies it as a .Z compressed file. This is crucial for recognizing the file type when decompressing.
- Flags: The header may include basic flags that determine how the compression was performed. These flags might indicate whether certain optional features, like the use of variable-length codes, are used.
Compressed Data Stream:
- LZW Compressed Data: The main body of the .Z file contains the actual file data compressed using the LZW (Lempel-Ziv-Welch) algorithm. The data is stored as a single continuous stream of compressed information, which reduces redundancy by encoding repetitive data patterns with shorter codes.
- No Blocks or Segmentation: Unlike more complex formats that divide data into blocks or segments for independent compression and easier error recovery, the Z format compresses the entire file in one go. This simplicity was advantageous for the limited computing resources of the time but can be a drawback if the file is corrupted.
End of File (EOF) Marker:
- Implicit Termination: The Z format does not have an explicit end-of-file marker or footer. The compressed data stream simply runs until the end of the file is reached. The decompression process continues until all data is extracted or until an error is encountered.
- No Built-in Integrity Checks: Unlike modern compression formats, .Z archives do not include checksums or other data integrity verification mechanisms within the file structure. This lack of built-in error detection means that corruption may only be noticed during decompression if the output data is incomplete or incorrect.
Optional Metadata:
- Minimal Metadata: The Z file format is very basic and does not support additional metadata such as file names, timestamps, or extended attributes within the compressed file. Any such information would need to be handled externally, typically by the filesystem or accompanying files.
Popularity of the Z Archive Format
The .Z file format was highly popular during the early days of UNIX and early Linux systems, primarily in the 1980s and 1990s. It became a standard for compressing files on these platforms due to its relatively efficient use of storage space and its fast decompression times. The format was commonly used for distributing software, system updates, and large data files, especially in environments where storage capacity was limited. Although the Z format has largely been replaced by more modern compression formats like gzip and bzip2 , it remains supported for legacy compatibility on many UNIX and Linux systems. Despite its decline in general usage, the Z format is still encountered in certain archival contexts and older software repositories, maintaining a niche but important role in computing history.
Examples of Using Z Archives
This section provides code examples demonstrating how to compress and decompress Z archives using C# and Java. Below are examples that utilize the ZArchive class to work with Z files, illustrating how they can be managed programmatically in both C# and Java environments.
Сompress the Z file into .Z extension via C# using ZArchive instance.
using (FileStream source = File.Open("alice29.txt", FileMode.Open, FileAccess.Read))
{
using (ZArchive archive = new ZArchive())
{
archive.SetSource(source);
archive.Save("alice29.txt.Z");
}
}
Open Z Archive via C#
FileInfo fi = new FileInfo("data.bin.Z");
using (ZArchive archive = new ZArchive(fi.OpenRead()))
{
archive.Extract("data.bin");
}
Сompress the Z file into .Z extension via Java using ZArchive instance.
try (FileInputStream source = new FileInputStream("alice29.txt")) {
try (ZArchive archive = new ZArchive()) {
archive.setSource(source);
archive.save("alice29.txt.Z");
}
} catch (IOException ex) {
}
Open Z Archive via Java
try (ZArchive archive = new ZArchive("data.bin.Z")) {
archive.extract("data.bin");
}
Additional information
People have been asking
1. What is a Z file, and how is it different from other compressed file formats like ZIP or GZIP?
A Z file is a compressed archive created using the Lempel-Ziv-Welch (LZW) algorithm, commonly used on UNIX systems. Unlike ZIP or GZIP, which are more modern and offer better compression ratios and additional features, the Z format is simpler and was popular in the early days of computing. Z files are typically encountered in older software distributions or legacy systems.
2. Are Z files still commonly used today?
Z files are not commonly used today, as they have largely been replaced by more efficient compression formats like GZIP, BZIP2, and XZ. However, Z files are still supported on many UNIX and Linux systems for legacy compatibility, and they may still be encountered in older software archives.
3. Can I convert a Z file to another format like ZIP or GZIP?
Yes, it’s possible to convert a Z file to another format on the fly. You can extract a specific entry from a Z archive directly into memory without creating an intermediate file. This allows for seamless integration with other compression formats like gzip or zip.