LZMA-bestandsindeling
Hoe u LZMA-bestanden kunt openen, wijzigen, genereren, decomprimeren en transformeren
LZMA-archiefbestandsindeling
LZMA (Lempel-Ziv-Markov-ketenalgoritme) is een modern datacompressie-algoritme dat bekend staat om zijn hoge efficiëntie en uitzonderlijke compressieverhouding. LZMA wordt veel gebruikt in archiefformaten zoals
7z
en verkleint effectief de bestandsgrootte zonder een significante opoffering van de decompressiesnelheid. LZMA-archieven garanderen het behoud van datakwaliteit en integriteit, waardoor ze een perfecte oplossing zijn voor het efficiënt opslaan en beheren van grote datasets.
Het belangrijkste voordeel van LZMA is de mogelijkheid om grote bestanden en complexe datastructuren te verwerken met minimaal verlies. Door LZMA te gebruiken, kunt u de schijfruimte optimaliseren en wordt de bestandsoverdracht via internet vergemakkelijkt vanwege de kleinere archiefgrootte. Dit maakt LZMA een populaire keuze onder ontwikkelaars en systeembeheerders voor efficiënt gegevensbeheer.
Over LZMA-archiefinformatie
LZMA-archieven ondersteunen parallellisatie, wat een efficiënt gebruik van multi-coreprocessors mogelijk maakt voor snellere bestandscompressie en decompressie. Bovendien staat LZMA bekend om zijn hoge weerstand tegen schade, waardoor het een betrouwbare keuze is voor langdurige opslag van belangrijke gegevens. Het algoritme beschikt ook over open source-code, wat de brede implementatie en aanpassing ervan in verschillende softwareoplossingen mogelijk maakt. Vanwege de voordelen blijft LZMA een van de meest efficiënte compressieformaten, die optimaal gegevensbeheer biedt voor gebruikers over de hele wereld.
Evolutie van de LZMA
Het LZMA-algoritme, ontwikkeld door Igor Pavlov in 1998 als onderdeel van het 7-Zip-project, had tot doel een zeer efficiënte datacompressiemethode te creëren. Aanvankelijk bouwde het voort op de klassieke LZ77-algoritmen, waarbij technieken werden gebruikt die de compressie-efficiëntie aanzienlijk verhoogden. Geleidelijk aan kreeg LZMA erkenning vanwege zijn vermogen om grote datasets te verwerken met een minimaal verbruik van hulpbronnen. In 2001 werd LZMA het belangrijkste compressie-algoritme voor het 7z-formaat, dat snel aan populariteit won vanwege de uitstekende prestaties. Bovendien is het algoritme geïntegreerd in tal van archiverings- en gegevensopslagsystemen, met name in open source softwareproducten. Tegenwoordig blijft LZMA evolueren en behoudt het zijn relevantie door voortdurende updates en optimalisaties, waardoor zijn positie als onmisbaar hulpmiddel in de digitale wereld wordt verstevigd.
Principes van het LZMA-algoritme
Het LZMA-algoritme is gebaseerd op het gebruik van opeenvolgende herhalingen in de gegevens om een hoge mate van compressie te bereiken. Het hoofdidee van het algoritme is om een woordenboek op te bouwen en op te slaan met eerder aangetroffen substrings, die vervolgens worden vervangen door verwijzingen in dit woordenboek. Hierdoor kunt u de hoeveelheid gegevens die moet worden opgeslagen of verzonden aanzienlijk verminderen. Een van de belangrijkste kenmerken van LZMA is het gebruik van bereikcodering in plaats van Huffman-codering. Bereikcodering biedt een betere compressie die dichter bij de entropie van de gegevens ligt en maakt gebruik van een binair formaat, waardoor trage bewerkingen van gehele getallen worden vermeden.
LZMA gebruikt het LZ77-algoritme om de langste overeenkomsten in de zoekbuffer en de voorspellingsbuffer te vinden, en schrijft deze naar een gecomprimeerd bestand in de vorm van een triplet (afstand, lengte, volgend teken). Als er geen overeenkomst wordt gevonden, wordt een byte in het bereik [0,255] aan het bestand toegevoegd. Als er een match wordt gevonden, wordt een paar waarden (afstand en lengte) geregistreerd die zijn gecodeerd door de bereikcoderingsmethode.
Om de efficiëntie met een grote zoekbuffer te verbeteren, slaat het algoritme de vier meest voorkomende afstanden op in een speciale afstandsgeschiedenisarray. Als een van deze afstanden opnieuw verschijnt, worden ze vervangen door een 2-bits code die verwijst naar de afstandsgeschiedenisarray, waardoor er minder informatie nodig is om de wedstrijd op te slaan.
LZMA gebruikt een hash van 2 bytes (de huidige byte en de volgende byte) om overeenkomsten in de zoekbuffer te vinden. De grootte van de hash-array is rechtstreeks gekoppeld aan de woordenboekgrootte. Een woordenboek van 1 GB gebruikt bijvoorbeeld een hash-array van 512 MB, waardoor botsingen in de hash-functie tot een minimum worden beperkt.
Deze benadering op meerdere niveaus biedt efficiënte datacompressie en -opslag zonder een aanzienlijk verbruik van hulpbronnen, waardoor LZMA een van de meest efficiënte algoritmen voor datacompressie is.
Voordelen van het .lzma-bestandsformaat
Dit zijn de belangrijkste voordelen van LZMA, waardoor het een aantrekkelijke keuze is voor veel datacompressietoepassingen.
- Hoge compressieverhouding: LZMA biedt een van de hoogste compressieverhoudingen onder de bestaande algoritmen, waardoor u de bestandsgrootte aanzienlijk kunt verkleinen. De gemiddelde compressieverhoudingen bedragen meer dan 70% in vergelijking met andere archiefformaten.
- Snelle decompressie: Het algoritme is geoptimaliseerd voor snelle gegevensdecompressie, waardoor LZMA zeer geschikt is voor gebruik in softwaretoepassingen en opslagsystemen waar het snel ophalen van gegevens essentieel is.
- Efficiënt beheer van grote bestanden: Vanwege de grote omvang van de zoekbuffer kan LZMA grote hoeveelheden gegevens efficiënt verwerken met behoud van een hoge compressiesnelheid.
- Betrouwbaarheid en schadetolerantie: LZMA biedt hoge weerstand tegen gegevensschade. Zelfs als er fouten optreden tijdens de opslag of verzending, maakt het ontwerp enige foutcorrectie mogelijk, waardoor gegevensverlies wordt geminimaliseerd en de integriteit van uw informatie tijdens langdurige opslag wordt gegarandeerd.
- Open source-code: Het open-source karakter van het LZMA-algoritme vergemakkelijkt de wijdverspreide implementatie, aanpassing en integratie ervan in verschillende softwareoplossingen, waardoor de adoptie en voortdurende ontwikkeling ervan wordt bevorderd.
LZMA-archief ondersteunde bewerkingen
Met Aspose.ZIP kunnen gebruikers zowel individuele bestanden als het volledige archief uitpakken. Voor .NET kunt u de LzmaArchiveClass gebruiken om een .lzma-bestand te openen, vervolgens kunt u door de records bladeren en deze uitpakken naar de gewenste locatie. Een soortgelijke aanpak wordt gebruikt in Java, waar u LzmaArchive gebruikt om het .lzma-bestand te openen en de records uit te pakken. Dankzij Aspose.ZIP worden deze handelingen eenvoudig en handig voor gebruikers van elk niveau.
LZMA-structuur
Hoewel het juist is om te zeggen dat LZMA sterk wordt beïnvloed door LZ77 (Lempel-Ziv 1977) en LZ78 (Lempel-Ziv 1978), is het nauwkeuriger om LZMA te beschrijven als een evolutie van deze algoritmen, met aanzienlijke verbeteringen.
- Bereikcodering: LZMA vervangt Huffman-codering door bereikcodering, een efficiëntere methode voor gegevensrepresentatie.
- Afstandsgeschiedenis: LZMA houdt een geschiedenis bij van veelgebruikte afstanden, waardoor de wedstrijddetectie wordt versneld.
- Hashtabel: LZMA gebruikt een hashtabel om het zoeken naar overeenkomende reeksen te versnellen.
- Voorspellende modellen: LZMA bevat voorspellende modelleringstechnieken om te anticiperen op komende gegevenspatronen, waardoor de compressie verder wordt verbeterd.
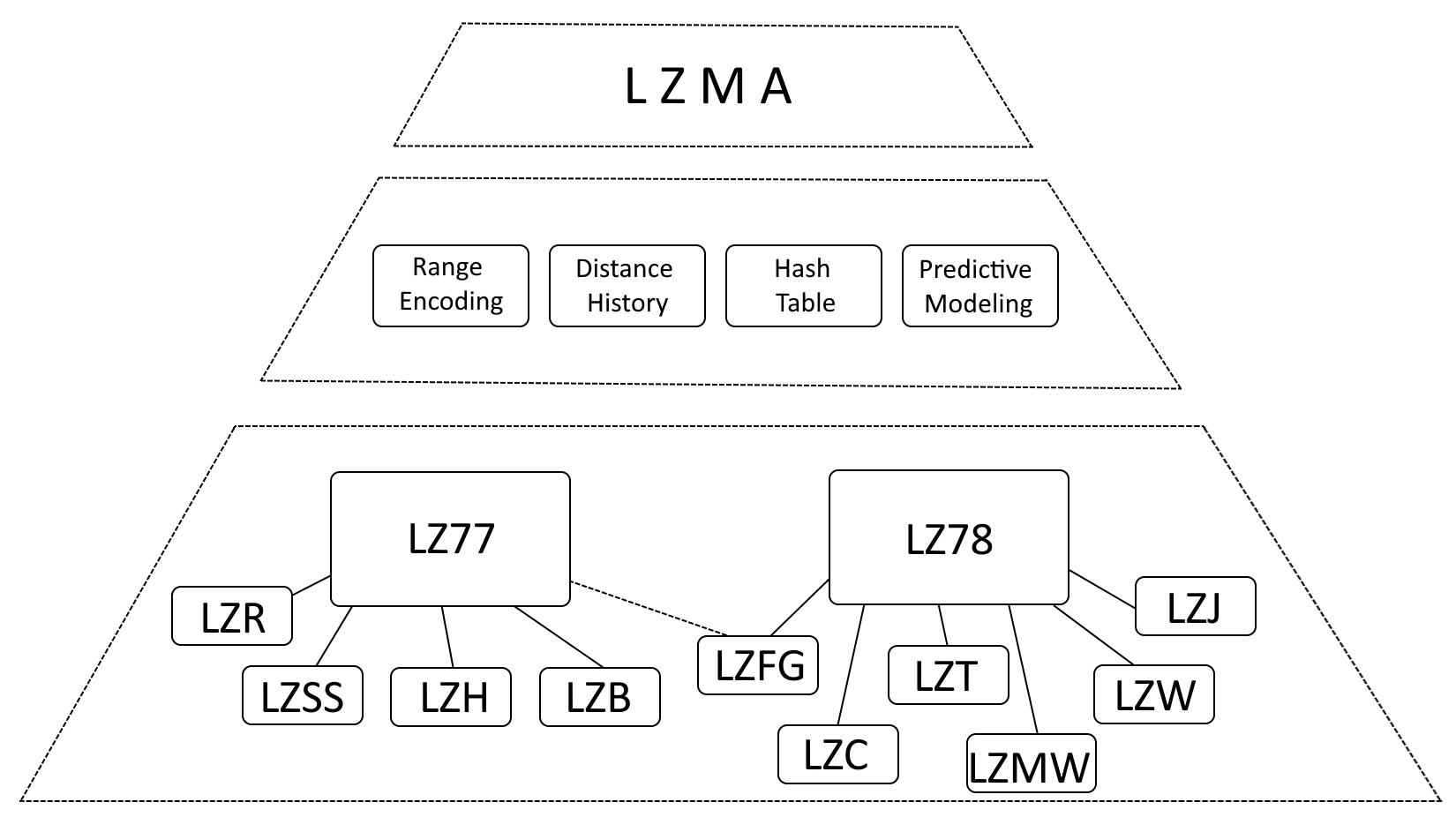
Binnenste LZMA-archiefstructuur
- Bestandsmetagegevens - Net als bij een tar-archief slaat elk bestand basisinformatie op, zoals wijzigingstijd en machtigingen. Deze sectie is echter flexibel en maakt het mogelijk om aanvullende details zoals toegangscontrolelijsten (ACL’s) of uitgebreide attributen (EA’s) weg te laten of op te nemen, afhankelijk van uw behoeften. Het wordt aanbevolen om een sterke hash-functie (zoals SHA1) op te nemen voor gewone bestanden om de gegevensintegriteit te garanderen.
- Meerdere inhoudsstromen - In tegenstelling tot traditionele archieven kunnen bestanden meer dan één gegevensstroom binnen het interne gegevensbestand bevatten. Dit is handig voor het opslaan van uitgebreide attributen of bronvorken die aan het bestand zijn gekoppeld.
- Kopteksten - Het binnenste indexbestand bevat bestandskopteksten, die overeenkomen met de kopteksten die verspreid zijn over het binnenste gegevensbestand. Maar wanneer ze afzonderlijk worden opgeslagen, moeten de indexkoppen verwijzen naar de startpositie van hun overeenkomstige gegevens in het gegevensbestand. Bovendien vermelden directory-items in de index de daarin opgenomen bestanden en hun corresponderende offsets binnen de interne bestandsindex.
- Rationale voor dubbele metadata - Deze ontwerpkeuze garandeert zowel efficiënte gegevensstreaming/decodering als willekeurige toegang tot bestanden. Bovendien worden metadata goed gecomprimeerd, wat resulteert in minimale opslagoverhead. Uit tests blijkt dat metadata doorgaans minder dan 0,3% van de opslagruimte in beslag nemen, wat de afweging de moeite waard maakt.
- Blokheaders - Blokheaders bevatten, vergelijkbaar met het buitenste bestand, informatie over de blokgrootte en een unieke identificatiereeks.
Voorbeelden van het gebruik van LZMA Python
Met de Aspose.ZIP via Python API kunt u eenvoudig LZMA-archieven in uw applicaties beheren, waardoor de noodzaak voor andere externe software wordt geëlimineerd. De API omvat de LzmaArchive-klasse , die het werken met LZMA-archieven vereenvoudigt, en de LzmaCompressionSettings-klasse , waarmee u de compressie-instellingen kunt aanpassen voor optimale prestaties en verkleining van de bestandsgrootte.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Aanvullende informatie over LZMA-archieven
Mensen hebben ernaar gevraagd
1. Welke bestandsformaten gebruiken LZMA-compressie?
LZMA is zelf geen bestandsformaat, maar een compressie-algoritme dat in verschillende archiefformaten wordt gebruikt. Enkele veelvoorkomende voorbeelden zijn 7z, XZ en soms ZIP. Wanneer u een bestand met deze extensies tegenkomt, is het mogelijk gecomprimeerd met LZM
2. Is LZMA open source?
Ja, LZMA is een open-source algoritme, waardoor het gratis beschikbaar is voor gebruik en integratie in verschillende softwareoplossingen. Dit open-source karakter heeft bijgedragen aan de wijdverbreide acceptatie en voortdurende ontwikkeling ervan.
3. Wat zijn enkele alternatieven voor LZMA?
Verschillende compressie-algoritmen bieden verschillende afwegingen. ZIP brengt compressie en snelheid goed in evenwicht, BZIP2 biedt hoge compressie ten koste van de snelheid in vergelijking met LZMA, terwijl XZ, gebaseerd op LZMA, sterke compressie biedt en vaak wordt gebruikt in Linux-omgevingen.