Format pliku LZ
Kluczowe funkcje archiwów LZ — jak otwierać, kompresować, wyodrębniać i zarządzać archiwami LZ
Format archiwum LZ
LZ to format archiwum zaprojektowany z myślą o wydajnej kompresji danych, wykorzystywany głównie w środowiskach, w których kluczowe znaczenie ma ograniczenie przestrzeni dyskowej i optymalizacja transferu danych. Wykorzystując algorytm kompresji Lempel-Ziv (LZ), format ten jest znany ze swojej zdolności do kompresji dużych ilości danych z naciskiem na szybkość i efektywne wykorzystanie zasobów. Archiwa LZ są szczególnie popularne w scenariuszach wymagających szybkich cykli kompresji i dekompresji, dzięki czemu nadają się zarówno do dystrybucji oprogramowania, jak i przetwarzania danych w czasie rzeczywistym.
Ogólne informacje o archiwum LZ
Archiwa LZ to skompresowane formaty plików, w których podstawową metodą kompresji jest algorytm Lempel-Ziv. Znane ze swojej szybkości i prostoty archiwa LZ przedkładają efektywną kompresję nad maksymalne współczynniki kompresji. Dzięki temu nadają się do zastosowań wymagających szybkiej kompresji i dekompresji, takich jak przetwarzanie danych w czasie rzeczywistym lub systemy wbudowane. Rozszerzenie .lz jest najpopularniejszym rozszerzeniem plików skompresowanych LZ. choć archiwa LZ oferują szybką kompresję, ich ograniczenia w zakresie współczynnika kompresji i metadanych sprawiają, że są mniej przydatne do archiwizacji dużych zbiorów danych lub zachowywania atrybutów plików. Nowoczesne formaty kompresji, takie jak ZIP, gzip i XZ, zastąpiły LZ w wielu aplikacjach ze względu na ich ulepszone funkcje i wydajność.
Historia archiwów LZ
- 1977: Izraelscy informatycy Abraham Lempel i Jacob Ziv położyli podwaliny pod kompresję LZ, którzy wprowadzili algorytm LZ77. Był to pierwszy powszechnie przyjęty algorytm bezstratnej kompresji danych, wykorzystujący przesuwane okno do kompresji powtarzających się wzorców danych.
- 1978: Lempel i Ziv wprowadzili algorytm LZ78, będący ulepszeniem w stosunku do LZ77, który wykorzystywał podejście oparte na słowniku. Algorytm ten jeszcze bardziej zwiększył wydajność kompresji i zainspirował wiele późniejszych technik kompresji.
- 1984: Terry Welch zbudował algorytm LZ78 w celu opracowania LZW (Lempel-Ziv-Welch), który stał się spopularyzowany dzięki jego zastosowaniu w uniksowym poleceniu kompresji i formacie obrazu GIF. LZW był jednym z pierwszych powszechnie używanych algorytmów kompresji w zastosowaniach komercyjnych.
- Lata 90-te: Warianty algorytmu LZ nadal ewoluowały, co doprowadziło do opracowania bardziej zaawansowanych metod kompresji takich jak LZMA (algorytm łańcuchowy Lempela-Ziv-Markowa) używanych w formatach takich jak 7z i XZ , które zapewniają wyższy stopień kompresji.
- Lata 2000: Techniki kompresji oparte na LZ, zwłaszcza LZW, zostały osadzone w wielu formatach plików i protokołach, chociaż niektóre, jak GIF, napotkały problemy związane z patentami, które wpłynęły na ich użycie.
- 2010 rok: Algorytmy oparte na LZ, w szczególności LZMA i jego warianty, pozostają podstawą nowoczesnego oprogramowania do kompresji, równoważąc wysoką wydajność kompresji z rozsądną wydajnością. Nadal są szeroko stosowane w dystrybucji oprogramowania, archiwizacji i przechowywaniu danych.
- Lata 20. XX w.: Format LZ w dalszym ciągu jest niezawodnym i wydajnym wyborem w zakresie kompresji, szczególnie w środowiskach, w których priorytetem jest szybkość i prostota.
Charakterystyka archiwum LZ
Format archiwum LZ ma prostą strukturę, w której priorytetem jest szybkość, a nie rozbudowane funkcje. W tym przypadku podstawowa struktura archiwum LZ jest ważna dla pracy ze starymi skompresowanymi plikami i oceny ewolucji technologii kompresji.
- Kompresja pojedynczego pliku: Zwykle kompresuje pojedynczy plik do archiwum .lz.
- Algorytm LZW: wykorzystuje metodę kompresji Lempela-Ziv-Welcha.
- Brak metadanych: W archiwum przechowywane są ograniczone metadane dotyczące oryginalnego pliku lub nie są one przechowywane wcale.
- Prostota: Prosta struktura formatu zapewnia dużą prędkość kompresji i dekompresji.
Metody kompresji archiwów LZ
Format archiwum LZ wykorzystuje algorytm Lempel-Ziv (LZ), który jest znany ze swojej prostoty i szybkości, co czyni go preferowanym wyborem w scenariuszach, w których krytyczna jest szybka kompresja i dekompresja. Poniżej znajduje się przegląd metod kompresji związanych z LZ:
- Algorytm Lempela-Ziva: Rdzeń formatu archiwum LZ opiera się na algorytmie LZ, metodzie bezstratnej kompresji, która identyfikuje i eliminuje nadmiarowość danych poprzez zastąpienie powtarzających się sekwencji krótszymi kodami. Algorytm LZ działa poprzez budowanie słownika sekwencji podczas przetwarzania danych, co pozwala na efektywną kompresję dużych i powtarzalnych zbiorów danych. Ta metoda jest szczególnie skuteczna w scenariuszach, w których wzorce danych są spójne i przewidywalne.
- Technika przesuwanego okna: Algorytm LZ zazwyczaj wykorzystuje mechanizm przesuwanego okna, w którym okno o stałym rozmiarze przesuwa się nad wejściowym strumieniem danych w celu znalezienia powtarzających się sekwencji. Takie podejście pozwala algorytmowi zachować możliwy do zarządzania rozmiar słownika, jednocześnie zapewniając znaczną kompresję. Przesuwane okno odgrywa kluczową rolę w równoważeniu wydajności kompresji z wykorzystaniem pamięci, dzięki czemu metoda LZ jest odpowiednia dla systemów o ograniczonych zasobach.
- Suma kontrolna i wykrywanie błędów: Chociaż format LZ koncentruje się na kompresji, może również zawierać podstawowe mechanizmy sum kontrolnych, takie jak CRC32, aby zapewnić integralność skompresowanych danych. Te sumy kontrolne pomagają wykryć błędy, które mogą wystąpić podczas przechowywania lub transmisji, zapewniając, że zdekompresowane dane pozostaną dokładne i nieuszkodzone.
- Opcjonalne udoskonalenia: W niektórych implementacjach metodę kompresji LZ można ulepszyć za pomocą dodatkowych technik, takich jak kodowanie ciągłe (RLE) lub kodowanie delta, co może dodatkowo zmniejszyć rozmiar skompresowanych danych. Te opcjonalne ulepszenia są stosowane do określonych typów danych w archiwum, umożliwiając bardziej efektywną kompresję niektórych typów zawartości, takich jak obrazy lub kod wykonywalny.
Obsługiwane operacje .lz
Aspose.Zip oferuje kompleksową obsługę pracy z archiwami .lz, ułatwiając zarządzanie skompresowanymi plikami. Oto, co możesz zrobić:
- Pełna ekstrakcja: Z łatwością wyodrębnij wszystkie pliki z archiwum .lz, zachowując integralność i strukturę oryginalnej zawartości.
- Wyodrębnianie selektywne: Celuje w określone pliki w archiwum .lz, umożliwiając precyzyjne odzyskiwanie danych lub selektywną dekompresję na podstawie nazw plików lub innych kryteriów.
- Kompresja danych: Twórz archiwa .lz z plików i katalogów, wykorzystując wydajną metodę kompresji LZMA2, aby znacznie zmniejszyć rozmiar plików.
- Niestandardowe ustawienia kompresji: Dostosuj poziomy kompresji i inne parametry, aby zrównoważyć prędkość kompresji i rozmiar pliku, dostosowując proces do konkretnych potrzeb.
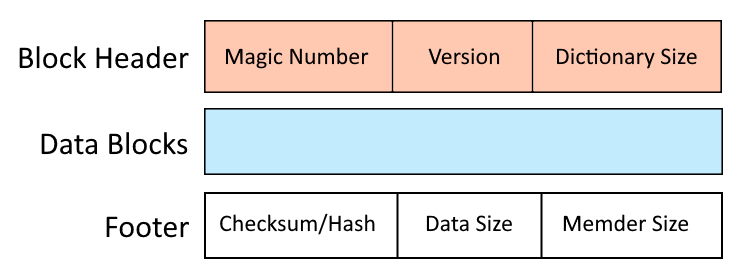
Struktura pliku .LZ
Format archiwum Lzip został zaprojektowany z naciskiem na wydajność i szybkość, wykorzystując strukturę warstwową, która ułatwia szybką kompresję i dekompresję. Archiwum Lzip składa się z jednego lub kilku elementów przechowywanych w archiwum jeden po drugim. Struktura członka Lzip obejmuje następujące elementy:
Nagłówek bloku:
- Magic Number: Unikalny identyfikator sygnalizujący początek archiwum Lzip, zapewniający rozpoznanie pliku jako prawidłowego formatu Lzip.
- Informacje o wersji: wskazuje używaną wersję pliku Lzip, co pomaga w zapewnieniu dalszej kompatybilności z różnymi narzędziami do dekompresji. Teraz ma wartość „1”.
- Rozmiar słownika: To pole zawiera informacje o szczegółach kompresji LZMA użytej dla nadchodzącego bloku danych.
Skompresowany blok danych:
- Skompresowany ładunek: rdzeń archiwum LZ, ta sekcja zawiera skompresowany strumień danych. Algorytm łańcuchowy Lempela-Ziv-Markowa przetwarza oryginalne dane na serię kodów reprezentujących powtarzające się sekwencje, znacznie zmniejszając rozmiar pliku. Ten sam algorytm kompresji jest obsługiwany w formatach xz i 7z.
Stopka blokowa:
- Suma kontrolna/hasz: suma kontrolna (np. CRC32) lub skrót kryptograficzny (np. SHA-256) są dołączane w celu sprawdzenia integralności skompresowanych danych. Dzięki temu archiwum nie zostało naruszone ani uszkodzone podczas przesyłania lub przechowywania.
- Rozmiar danych: Rozmiar fragmentu oryginalnego pliku skompresowanego w tym bloku.
- Memder Size: część rozproszonego indeksu ze skompresowanym rozmiarem i przesunięciem, która pozwala na niezależne wyodrębnianie bloków.
Ponieważ format Lzip nie kompresuje wielu plików i nie przechowuje metadanych, często używa się go w połączeniu z narzędziem tar.
Popularność formatu LZ
Format archiwum LZ, oparty na algorytmie kompresji Lempela-Ziva, jest podstawową technologią w świecie kompresji danych. Jego powszechne zastosowanie przypisuje się prostocie, wydajności i możliwości osiągnięcia znacznych współczynników kompresji, szczególnie w przypadku danych o powtarzających się wzorach. Metody kompresji oparte na LZ zostały włączone do różnych formatów plików i narzędzi do kompresji, dzięki czemu format LZ jest wszechstronnym i niezbędnym elementem procesów przechowywania, transmisji i archiwizacji danych. Chociaż pojawiły się nowsze algorytmy kompresji, takie jak LZMA i Brotli, format LZ pozostaje aktualny ze względu na równowagę szybkości i skuteczności kompresji.
W środowiskach UNIX i Linux kompresja LZ jest często używana w połączeniu z innymi narzędziami, takimi jak tar, do tworzenia skompresowanych archiwów do dystrybucji oprogramowania i tworzenia kopii zapasowych danych. Integracja z wieloma narzędziami do kompresji zapewniła jego ciągłe wykorzystanie na różnych platformach, w tym Windows i macOS. Chociaż format LZ może nie być tak powszechnie rozpoznawany jak inne formaty kompresji, takie jak ZIP czy GZIP, jego wpływ na technologię kompresji danych jest niezaprzeczalny i nadal jest stosowany w różnych scenariuszach, gdzie konieczna jest szybka i niezawodna kompresja.
Przykłady wykorzystania archiwów LZ
W tej sekcji przedstawiono przykłady kodu demonstrujące sposób kompresowania i otwierania archiwów LZ przy użyciu języków C#, Java i Python.NET. W tych przykładach wykorzystano biblioteki i klasy, takie jak LzipArchive, do zarządzania plikami LZ, ilustrując praktyczne zastosowanie kompresji LZ w nowoczesnych środowiskach programistycznych.
Compresses a file into .LZ archive using the LzipArchive class in C#.
using (LzipArchive archive = new LzipArchive())
{
archive.SetSource("data.bin");
archive.Save("data.bin.lz");
}
Extract LZip Archive using C#
using (FileStream sourceLzipFile = File.Open("data.bin.lz", FileMode.Open))
{
using (FileStream extractedFile = File.Open("data.bin", FileMode.Create))
{
using (LzipArchive archive = new LzipArchive(sourceLzipFile))
{
archive.Extract(extractedFile);
}
}
}
Compresses a file into .LZ archive using the LzipArchive class in Java.
try (LzipArchive archive = new LzipArchive()) {
archive.setSource("data.bin");
archive.save("data.bin.lz");
}
Extract LZip Archive using Java
try (FileInputStream sourceLzipFile = new FileInputStream("data.bin.lz")) {
try (FileOutputStream extractedFile = new FileOutputStream("data.bin")) {
try (LzipArchive archive = new LzipArchive(sourceLzipFile)) {
archive.extract(extractedFile);
}
}
} catch (IOException ex) {
}
Compresses a file into .LZ archive using the LzipArchive class using Python.Net
with aspose.zip.lzip.LzipArchive() as archive:
archive.set_source("data.bin")
archive.save("data.bin.lz")
Extract Lzip Archive using Python.Net
with io.FileIO("data.bin.lz", "rb") as source_lzip_file:
with io.FileIO("data.bin", "x") as extracted_file:
with aspose.zip.lzip.LzipArchive(source_lzip_file) as archive:
archive.extract(extracted_file)
Dodatkowe informacje
Ludzie pytali
1. Czy format archiwum LZ jest obsługiwany we wszystkich systemach operacyjnych?
Format archiwum LZ jest obsługiwany na wielu platformach, w tym UNIX, Linux, Windows i macOS. Chociaż jest to najczęściej kojarzone ze środowiskami typu UNIX, narzędzia i biblioteki obsługujące archiwa LZ są dostępne dla wszystkich głównych systemów operacyjnych.
2. Jakie są zalety korzystania z archiwów LZ?
Archiwa LZ są znane ze swojej wydajności w kompresowaniu danych według powtarzających się wzorców, oferując dobrą równowagę pomiędzy szybkością kompresji a redukcją rozmiaru pliku. Są łatwe we wdrożeniu, co czyni je niezawodnym wyborem w przypadku potrzeb szybkiej kompresji danych, szczególnie w przypadku dystrybucji oprogramowania, tworzenia kopii zapasowych danych i transmisji sieciowej.
3. Czy mogę skompresować wiele plików w jedno archiwum LZ?
Format LZ jest zwykle używany do kompresji pojedynczych plików. Aby skompresować wiele plików, należy najpierw połączyć je w archiwum (np. w archiwum tar przy użyciu tar), a następnie skompresować wynikowy plik archiwum za pomocą kompresji LZ. Ten proces jest powszechny w środowiskach UNIX i Linux.