Format pliku LZMA
Jak uzyskać dostęp, modyfikować, generować, dekompresować i przekształcać pliki LZMA
Format pliku archiwum LZMA
LZMA (algorytm łańcuchowy Lempel-Ziv-Markov) to nowoczesny algorytm kompresji danych, znany ze swojej wysokiej wydajności i wyjątkowego współczynnika kompresji. Szeroko stosowany w formatach archiwów, takich jak
7z
, LZMA skutecznie zmniejsza rozmiar pliku bez znaczącego poświęcania szybkości dekompresji. Archiwa LZMA gwarantują zachowanie jakości i integralności danych, dzięki czemu są idealnym rozwiązaniem do efektywnego przechowywania i zarządzania dużymi zbiorami danych.
Główną zaletą LZMA jest jego zdolność do obsługi dużych plików i złożonych struktur danych przy minimalnych stratach. Korzystanie z LZMA pozwala zoptymalizować przestrzeń dyskową i ułatwia przesyłanie plików przez Internet ze względu na mniejszy rozmiar archiwum. To sprawia, że LZMA jest popularnym wyborem wśród programistów i administratorów systemów w zakresie wydajnego zarządzania danymi.
Informacje o archiwum LZMA
Archiwa LZMA obsługują równoległość, która umożliwia efektywne wykorzystanie procesorów wielordzeniowych w celu szybszej kompresji i dekompresji plików. Ponadto LZMA charakteryzuje się dużą odpornością na uszkodzenia, co czyni go niezawodnym wyborem do długotrwałego przechowywania ważnych danych. Algorytm posiada także otwarty kod źródłowy, co ułatwia jego szerokie wdrożenie i adaptację w różnych rozwiązaniach programowych. Ze względu na swoje zalety LZMA pozostaje jednym z najskuteczniejszych formatów kompresji, zapewniającym optymalne zarządzanie danymi użytkownikom na całym świecie.
Ewolucja LZMA
Algorytm LZMA, opracowany przez Igora Pawłowa w 1998 roku w ramach projektu 7-Zip, miał na celu stworzenie wysoce wydajnej metody kompresji danych. Początkowo opierał się na klasycznych algorytmach LZ77, wykorzystując techniki, które znacznie zwiększyły wydajność kompresji. Stopniowo LZMA zyskała uznanie dzięki swojej zdolności do przetwarzania dużych zbiorów danych przy minimalnym zużyciu zasobów. W 2001 roku LZMA stał się głównym algorytmem kompresji dla formatu 7z, który szybko zyskał popularność dzięki swojej wyjątkowej wydajności. Ponadto algorytm został zintegrowany z wieloma archiwizatorami i systemami przechowywania danych, zwłaszcza z oprogramowaniem typu open source. Dziś LZMA nadal ewoluuje, utrzymując swoją aktualność poprzez ciągłe aktualizacje i optymalizacje, umacniając swoją pozycję jako niezbędnego narzędzia w cyfrowym świecie.
Zasady algorytmu LZMA
Algorytm LZMA opiera się na zastosowaniu sekwencyjnych powtórzeń w danych w celu uzyskania wysokiego stopnia kompresji. Główną ideą algorytmu jest zbudowanie i przechowywanie słownika zawierającego napotkane wcześniej podciągi, które następnie są zastępowane odniesieniami w tym słowniku. Pozwala to znacznie zmniejszyć ilość danych, które mają być przechowywane lub przesyłane. Jedną z kluczowych cech LZMA jest zastosowanie kodowania zakresu zamiast kodowania Huffmana. Kodowanie zakresu zapewnia lepszą kompresję bliższą entropii danych i wykorzystuje format binarny, co pozwala uniknąć powolnych operacji dzielenia liczb całkowitych.
LZMA wykorzystuje algorytm LZ77 do wyszukiwania najdłuższych dopasowań w buforze wyszukiwania i buforze przewidywania, zapisując je do skompresowanego pliku w postaci trójki (odległość, długość, następny znak). Jeśli nie zostanie znalezione żadne dopasowanie, do pliku dołączany jest bajt z zakresu [0,255]. W przypadku znalezienia dopasowania rejestrowana jest para wartości (odległość i długość) zakodowana metodą kodowania zakresu.
Aby poprawić efektywność dzięki dużemu buforowi wyszukiwania, algorytm przechowuje 4 najczęstsze odległości w dedykowanej tablicy historii odległości. Jeśli którakolwiek z tych odległości pojawi się ponownie, zostanie zastąpiona 2-bitowym kodem odwołującym się do tablicy historii odległości, co zmniejsza ilość informacji potrzebnych do przechowywania dopasowania.
LZMA używa 2-bajtowego skrótu (bieżący bajt i następny bajt), aby znaleźć dopasowania w buforze wyszukiwania. Rozmiar tablicy mieszającej jest bezpośrednio powiązany z rozmiarem słownika. Na przykład słownik o pojemności 1 GB wykorzystuje tablicę mieszającą o wielkości 512 MB, co minimalizuje kolizje w funkcji mieszającej.
To wielopoziomowe podejście zapewnia wydajną kompresję i przechowywanie danych bez znacznego zużycia zasobów, co czyni LZMA jednym z najbardziej wydajnych algorytmów kompresji danych.
Zalety formatu pliku .lzma
Oto główne zalety LZMA, czyniące go atrakcyjnym wyborem dla wielu zastosowań kompresji danych.
- Wysoki współczynnik kompresji: LZMA zapewnia jeden z najwyższych współczynników kompresji spośród istniejących algorytmów, co pozwala znacznie zmniejszyć rozmiary plików. Średnie współczynniki kompresji przekraczają 70% w porównaniu do innych formatów archiwów.
- Szybka dekompresja: Algorytm jest zoptymalizowany pod kątem szybkiej dekompresji danych, dzięki czemu LZMA doskonale nadaje się do stosowania w aplikacjach i systemach przechowywania danych, gdzie istotne jest szybkie odzyskanie danych.
- Efektywne zarządzanie dużymi plikami: Ze względu na duży rozmiar bufora wyszukiwania, LZMA może efektywnie przetwarzać duże ilości danych przy zachowaniu wysokiego stopnia kompresji.
- Niezawodność i tolerancja na uszkodzenia: LZMA zapewnia wysoką odporność na uszkodzenia danych. Nawet jeśli podczas przechowywania lub przesyłania wystąpią błędy, jego konstrukcja pozwala na pewną korektę błędów, minimalizując utratę danych i zapewniając integralność informacji podczas długotrwałego przechowywania.
- Kod open source: Otwarty charakter algorytmu LZMA ułatwia jego powszechne wdrażanie, adaptację i integrację z różnymi rozwiązaniami programowymi, promując jego przyjęcie i ciągły rozwój.
Obsługiwane operacje w archiwum LZMA
Aspose.ZIP pozwala użytkownikom wyodrębnić zarówno pojedyncze pliki, jak i całe archiwum. W przypadku platformy .NET można użyć metody LzmaArchiveClass , aby otworzyć plik .lzma, a następnie przejrzeć jego rekordy i wyodrębnić je do żądanej lokalizacji. Podobne podejście jest stosowane w Javie, gdzie do otwarcia pliku .lzma i wyodrębnienia rekordów służy LzmaArchive. Dzięki Aspose.ZIP operacje te stają się proste i wygodne dla użytkowników na każdym poziomie.
Struktura LZMA
Chociaż trafne jest stwierdzenie, że na LZMA duży wpływ mają LZ77 (Lempel-Ziv 1977) i LZ78 (Lempel-Ziv 1978), bardziej precyzyjne jest opisanie LZMA jako ewolucji tych algorytmów, obejmującej znaczące ulepszenia.
- Kodowanie zakresu: LZMA zastępuje kodowanie Huffmana kodowaniem zakresu, co jest bardziej wydajną metodą reprezentacji danych.
- Historia odległości: LZMA przechowuje historię często używanych odległości, przyspieszając wykrywanie dopasowań.
- Tabela mieszająca: LZMA wykorzystuje tablicę mieszającą, aby przyspieszyć wyszukiwanie pasujących sekwencji.
- Modelowanie predykcyjne: LZMA wykorzystuje techniki modelowania predykcyjnego w celu przewidywania nadchodzących wzorców danych, co dodatkowo zwiększa kompresję.
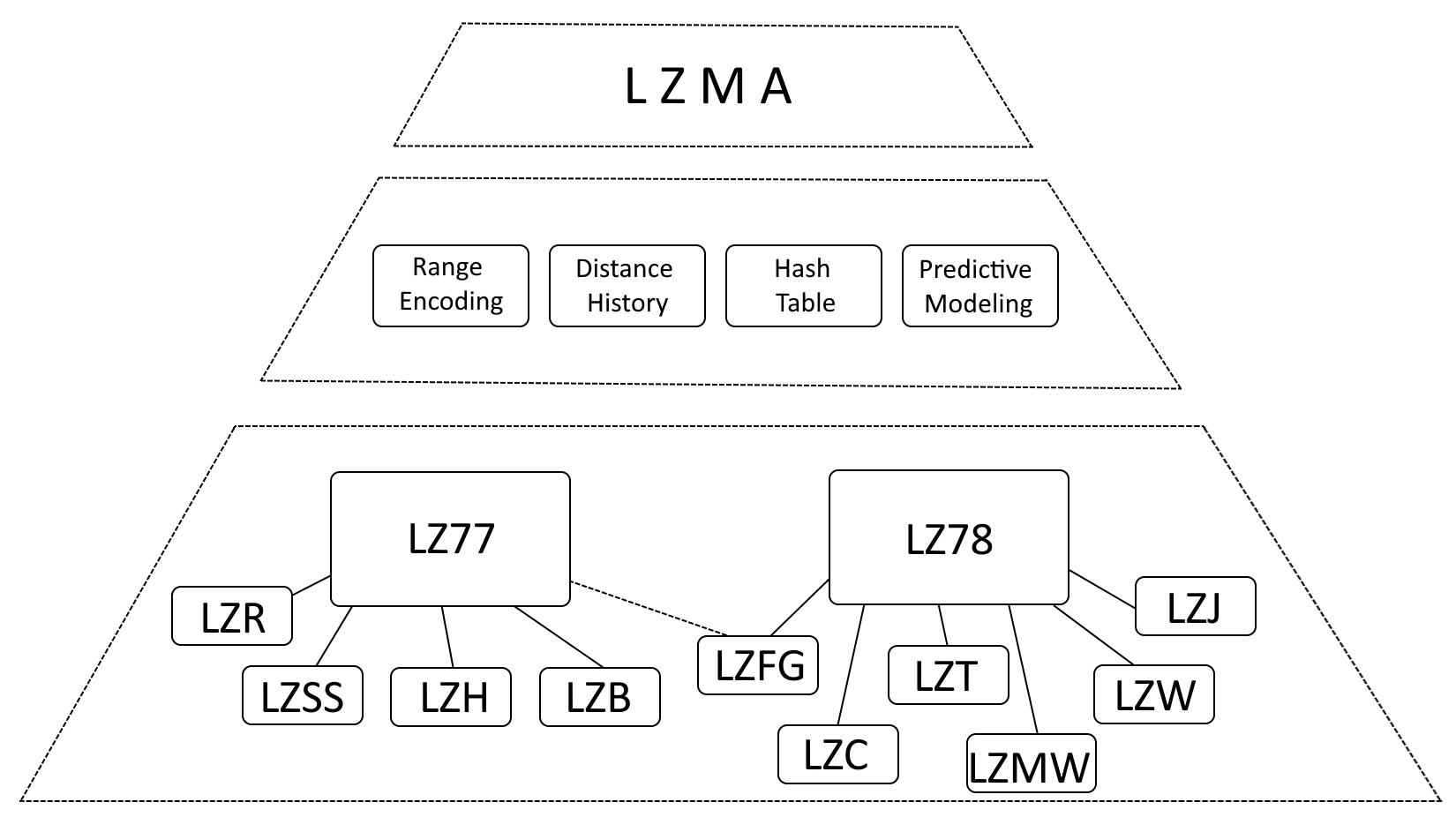
Wewnętrzna struktura archiwum LZMA
- Metadane pliku – Podobnie jak w przypadku archiwum tar, każdy plik przechowuje podstawowe informacje, takie jak czas modyfikacji i uprawnienia. Jednakże ta sekcja jest elastyczna i umożliwia pominięcie lub dołączenie dodatkowych szczegółów, takich jak listy kontroli dostępu (ACL) lub rozszerzone atrybuty (EA), w zależności od potrzeb. Zaleca się dołączenie silnej funkcji skrótu (takiej jak SHA1) do zwykłych plików, aby zapewnić integralność danych.
- Wiele strumieni treści – W przeciwieństwie do tradycyjnych archiwów, pliki mogą zawierać więcej niż jeden strumień danych w wewnętrznym pliku danych. Jest to przydatne do przechowywania rozszerzonych atrybutów lub rozwidleń zasobów powiązanych z plikiem.
- Nagłówki – Wewnętrzny plik indeksu zawiera nagłówki plików, odzwierciedlając te rozproszone w wewnętrznym pliku danych. Jednak w przypadku przechowywania oddzielnie nagłówki indeksów muszą odwoływać się do pozycji początkowej odpowiadających im danych w pliku danych. Dodatkowo wpisy katalogów w indeksie zawierają listę zawartych w nich plików i odpowiadających im przesunięć w wewnętrznym indeksie plików.
- Uzasadnienie duplikacji metadanych - Ten wybór projektu zapewnia zarówno wydajne przesyłanie strumieniowe/dekodowanie danych, jak i losowy dostęp do plików. Ponadto metadane są dobrze kompresowane, co skutkuje minimalnym obciążeniem pamięci. Testy pokazują, że metadane zajmują zazwyczaj mniej niż 0,3% przestrzeni dyskowej, dlatego warto podjąć taki kompromis.
- Nagłówki bloków – Nagłówki bloków, podobnie jak plik zewnętrzny, zawierają informacje o rozmiarze bloku i unikalną sekwencję identyfikatorów.
Przykłady użycia Pythona LZMA
Dzięki API Aspose.ZIP via Python możesz łatwo zarządzać archiwami LZMA w swoich aplikacjach, eliminując potrzebę korzystania z innego zewnętrznego oprogramowania. API obejmuje klasę LzmaArchive , która upraszcza pracę z archiwami LZMA, oraz klasę LzmaCompressionSettings , który umożliwia dostosowanie ustawień kompresji w celu uzyskania optymalnej wydajności i zmniejszenia rozmiaru pliku.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Dodatkowe informacje o archiwum LZMA
Ludzie pytali
1. W jakich formatach plików stosowana jest kompresja LZMA?
LZMA nie jest samym formatem pliku, ale algorytmem kompresji używanym w różnych formatach archiwów. Niektóre typowe przykłady to 7z, XZ i czasami ZIP. Gdy napotkasz plik z tymi rozszerzeniami, może on zostać skompresowany przy użyciu LZM
2. Czy LZMA jest oprogramowaniem typu open source?
Tak, LZMA jest algorytmem typu open source, dzięki czemu jest swobodnie dostępny do użytku i integracji z różnymi rozwiązaniami programowymi. Otwarty charakter oprogramowania przyczynił się do jego powszechnego przyjęcia i ciągłego rozwoju.
3. Jakie są alternatywy dla LZMA?
Kilka algorytmów kompresji oferuje różne kompromisy. ZIP dobrze równoważy kompresję i prędkość, BZIP2 zapewnia wysoką kompresję kosztem szybkości w porównaniu do LZMA, podczas gdy XZ, oparty na LZMA, oferuje silną kompresję i jest powszechnie używany w środowiskach Linux.