Formato de arquivo LZMA
Como acessar, modificar, gerar, descompactar e transformar arquivos LZMA
Formato de arquivo de arquivo LZMA
LZMA (algoritmo de cadeia Lempel-Ziv-Markov) é um algoritmo moderno de compressão de dados conhecido por sua alta eficiência e taxa de compressão excepcional. Amplamente utilizado em formatos de arquivo como
7z
, o LZMA reduz efetivamente o tamanho do arquivo sem sacrificar significativamente a velocidade de descompactação. Os arquivos LZMA garantem a preservação da qualidade e integridade dos dados, tornando-os uma solução perfeita para armazenar e gerenciar grandes conjuntos de dados de forma eficiente.
A principal vantagem do LZMA é sua capacidade de lidar com arquivos grandes e estruturas de dados complexas com perdas mínimas. O uso do LZMA permite otimizar o espaço em disco e facilita a transferência de arquivos pela Internet devido ao tamanho menor do arquivo. Isso torna o LZMA uma escolha popular entre desenvolvedores e administradores de sistema para gerenciamento eficiente de dados.
Sobre as informações do arquivo LZMA
Os arquivos LZMA suportam paralelização, o que permite o uso eficiente de processadores multi-core para compactação e descompactação de arquivos mais rápidas. Além disso, o LZMA é conhecido por sua alta resistência a danos, tornando-o uma escolha confiável para armazenamento de dados importantes a longo prazo. O algoritmo também possui código-fonte aberto, o que facilita sua ampla implementação e adaptação em diversas soluções de software. Devido às suas vantagens, o LZMA continua sendo um dos formatos de compressão mais eficientes, proporcionando gerenciamento ideal de dados para usuários em todo o mundo.
Evolução do LZMA
O algoritmo LZMA, desenvolvido por Igor Pavlov em 1998 como parte do projeto 7-Zip, teve como objetivo criar um método de compressão de dados altamente eficiente. Inicialmente, ele se baseou nos algoritmos clássicos LZ77, incorporando técnicas que aumentaram significativamente a eficiência da compressão. Gradualmente, o LZMA ganhou reconhecimento pela sua capacidade de processar grandes conjuntos de dados com consumo mínimo de recursos. Em 2001, o LZMA tornou-se o principal algoritmo de compressão para o formato 7z, que rapidamente ganhou popularidade devido ao seu excelente desempenho. Além disso, o algoritmo foi integrado em vários arquivadores e sistemas de armazenamento de dados, especialmente em produtos de software de código aberto. Hoje, o LZMA continua a evoluir, mantendo a sua relevância através de atualizações e otimizações contínuas, solidificando a sua posição como uma ferramenta indispensável no mundo digital.
Princípios do algoritmo LZMA
O algoritmo LZMA é baseado no uso de repetições sequenciais nos dados para atingir um alto grau de compressão. A ideia principal do algoritmo é construir e armazenar um dicionário contendo substrings encontradas anteriormente, que são então substituídas por referências neste dicionário. Isso permite reduzir significativamente a quantidade de dados a serem armazenados ou transmitidos. Uma das principais características do LZMA é o uso da codificação de intervalo em vez da codificação de Huffman. A codificação de intervalo oferece melhor compactação mais próxima da entropia dos dados e utiliza um formato binário, evitando operações lentas de divisão de inteiros.
LZMA usa o algoritmo LZ77 para encontrar as correspondências mais longas no buffer de pesquisa e no buffer de previsão, gravando-as em um arquivo compactado na forma de um trio (distância, comprimento, próximo caractere). Se nenhuma correspondência for encontrada, um byte no intervalo [0,255] será anexado ao arquivo. Se uma correspondência for encontrada, um par de valores (distância e comprimento) codificados pelo método de codificação de intervalo será registrado.
Para melhorar a eficiência com um grande buffer de pesquisa, o algoritmo armazena as 4 distâncias mais comuns em uma matriz de histórico de distância dedicada. Se alguma dessas distâncias reaparecer, elas serão substituídas por um código de 2 bits referenciando a matriz do histórico de distâncias, reduzindo as informações necessárias para armazenar a correspondência.
LZMA usa um hash de 2 bytes (o byte atual e o próximo byte) para encontrar correspondências no buffer de pesquisa. O tamanho da matriz hash está diretamente ligado ao tamanho do dicionário. Por exemplo, um dicionário de 1 GB usa uma matriz hash de 512 MB, o que minimiza colisões na função hash.
Essa abordagem multinível fornece compactação e armazenamento de dados eficientes sem consumo significativo de recursos, tornando o LZMA um dos algoritmos de compactação de dados mais eficientes.
Benefícios do formato de arquivo .lzma
Aqui estão as principais vantagens do LZMA, tornando-o uma escolha atraente para muitas aplicações de compactação de dados.
- Alta taxa de compactação: LZMA fornece uma das taxas de compactação mais altas entre os algoritmos existentes, o que permite reduzir significativamente o tamanho dos arquivos. As taxas médias de compactação excedem 70% em comparação com outros formatos de arquivo.
- Descompressão rápida: O algoritmo é otimizado para descompressão rápida de dados, tornando o LZMA adequado para uso em aplicativos de software e sistemas de armazenamento onde a recuperação rápida de dados é essencial.
- Gerenciamento eficiente de arquivos grandes: Devido ao grande tamanho do buffer de pesquisa, o LZMA pode processar com eficiência grandes quantidades de dados, mantendo uma alta taxa de compactação.
- Confiabilidade e tolerância a danos: LZMA oferece alta resistência a danos aos dados. Mesmo que ocorram erros durante o armazenamento ou transmissão, seu design permite alguma correção de erros, minimizando a perda de dados e garantindo a integridade de suas informações durante o armazenamento a longo prazo.
- Código-fonte aberto: A natureza de código-fonte aberto do algoritmo LZMA facilita sua ampla implementação, adaptação e integração em diversas soluções de software, promovendo sua adoção e desenvolvimento contínuo.
Operações suportadas pelo arquivo LZMA
Aspose.ZIP permite aos usuários extrair arquivos individuais e o arquivo inteiro. Para .NET, você pode usar LzmaArchiveClass para abrir um arquivo .lzma, então você pode percorrer seus registros e extraí-los para o local desejado. Uma abordagem semelhante é usada em Java, onde você usa LzmaArchive para abrir o arquivo .lzma e extrair os registros. Graças ao Aspose.ZIP, essas operações tornam-se simples e convenientes para usuários de qualquer nível.
Estrutura LZMA
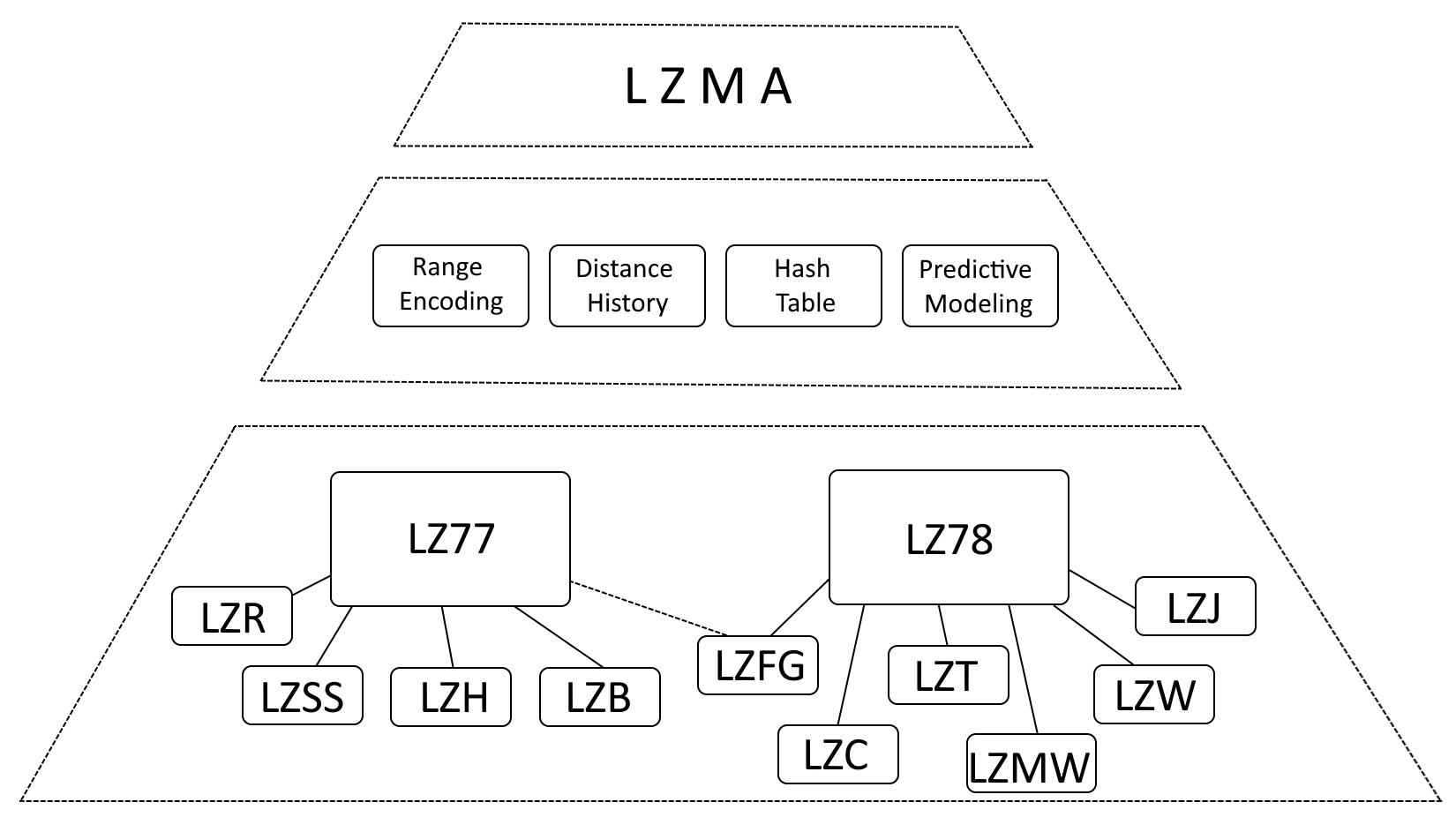
Embora seja correto dizer que o LZMA é fortemente influenciado pelo LZ77 (Lempel-Ziv 1977) e LZ78 (Lempel-Ziv 1978), é mais preciso descrever o LZMA como uma evolução desses algoritmos, incorporando melhorias significativas.
- Codificação de intervalo: LZMA substitui a codificação Huffman pela codificação de intervalo, um método de representação de dados mais eficiente.
- Histórico de distância: LZMA mantém um histórico de distâncias usadas com frequência, acelerando a detecção de correspondência.
- Tabela hash: LZMA emprega uma tabela hash para agilizar a busca por sequências correspondentes.
- Modelagem Preditiva: LZMA incorpora técnicas de modelagem preditiva para antecipar padrões de dados futuros, melhorando ainda mais a compactação.
Estrutura interna do arquivo LZMA
- Metadados do arquivo - Semelhante a um arquivo tar, cada arquivo armazena informações básicas como horário de modificação e permissões. No entanto, esta seção é flexível e permite omitir ou incluir detalhes adicionais como listas de controle de acesso (ACLs) ou atributos estendidos (EAs) com base em suas necessidades. É recomendado incluir uma função hash forte (como SHA1) para arquivos regulares para garantir a integridade dos dados.
- Vários fluxos de conteúdo - Ao contrário dos arquivos tradicionais, os arquivos podem ter mais de um fluxo de dados dentro do arquivo de dados interno. Isso é útil para armazenar atributos estendidos ou bifurcações de recursos associadas ao arquivo.
- Cabeçalhos - O arquivo de índice interno contém cabeçalhos de arquivo, espelhando aqueles espalhados pelo arquivo de dados interno. Mas, quando armazenados separadamente, os cabeçalhos do índice devem fazer referência à posição inicial dos dados correspondentes no arquivo de dados. Além disso, as entradas de diretório no índice listam os arquivos contidos e seus deslocamentos correspondentes no índice de arquivo interno.
- Justificativa para metadados duplicados - Esta escolha de design garante fluxo/decodificação eficiente de dados e acesso aleatório a arquivos. Além disso, os metadados são bem compactados, resultando em sobrecarga mínima de armazenamento. Os testes mostram que os metadados normalmente ocupam menos de 0,3% do espaço de armazenamento, fazendo com que a compensação valha a pena.
- Cabeçalhos de bloco - Os cabeçalhos de bloco, semelhantes ao arquivo externo, contêm informações de tamanho de bloco e uma sequência de identificador exclusiva.
Exemplos de uso do LZMA Python
Com a API Aspose.ZIP via Python , você pode gerenciar facilmente arquivos LZMA em seus aplicativos, eliminando a necessidade de outro software externo. A API inclui a classe LzmaArchive , que simplifica o trabalho com arquivos LZMA, e a classe LzmaCompressionSettings , que permite personalizar as configurações de compactação para desempenho ideal e redução do tamanho do arquivo.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Informações adicionais sobre arquivos LZMA
As pessoas têm perguntado
1. Quais formatos de arquivo usam compactação LZMA?
LZMA não é um formato de arquivo em si, mas um algoritmo de compactação usado em vários formatos de arquivo. Alguns exemplos comuns incluem 7z, XZ e, ocasionalmente, ZIP. Quando você encontrar um arquivo com essas extensões, ele pode estar compactado usando LZM
2. O LZMA é de código aberto?
Sim, LZMA é um algoritmo de código aberto, disponibilizando-o gratuitamente para uso e integração em diversas soluções de software. Esta natureza de código aberto contribuiu para a sua adoção generalizada e desenvolvimento contínuo.
3. Quais são algumas alternativas ao LZMA?
Vários algoritmos de compressão oferecem diferentes compensações. ZIP equilibra bem compactação e velocidade, BZIP2 oferece alta compactação ao custo de velocidade em comparação com LZMA, enquanto XZ, baseado em LZMA, oferece compactação forte e é comumente usado em ambientes Linux.