Формат файла LZMA
Как получить доступ, изменить, сгенерировать, распаковать и преобразовать файлы LZMA
Формат файла архива LZMA
LZMA (цепной алгоритм Лемпеля-Зива-Маркова) — это современный алгоритм сжатия данных, известный своей высокой эффективностью и исключительной степенью сжатия. LZMA, широко используемый в архивных форматах, таких как
7z
, эффективно уменьшает размер файла без существенного ущерба для скорости распаковки. Архивы LZMA гарантируют сохранение качества и целостности данных, что делает их идеальным решением для эффективного хранения и управления большими наборами данных.
Основным преимуществом LZMA является его способность обрабатывать большие файлы и сложные структуры данных с минимальными потерями. Использование LZMA позволяет оптимизировать дисковое пространство и облегчает передачу файлов через Интернет за счет меньшего размера архива. Это делает LZMA популярным выбором среди разработчиков и системных администраторов для эффективного управления данными.
Об архивной информации LZMA
Архивы LZMA поддерживают распараллеливание, что позволяет эффективно использовать многоядерные процессоры для более быстрого сжатия и распаковки файлов. Кроме того, LZMA отличается высокой устойчивостью к повреждениям, что делает его надежным выбором для долговременного хранения важных данных. Алгоритм также имеет открытый исходный код, что способствует его широкому внедрению и адаптации в различных программных решениях. Благодаря своим преимуществам LZMA остается одним из наиболее эффективных форматов сжатия, обеспечивающим оптимальное управление данными для пользователей по всему миру.
Эволюция LZMA
Алгоритм LZMA, разработанный Игорем Павловым в 1998 году в рамках проекта 7-Zip, был направлен на создание высокоэффективного метода сжатия данных. Первоначально он был основан на классических алгоритмах LZ77, включающих методы, которые значительно повысили эффективность сжатия. Постепенно LZMA получила признание за свою способность обрабатывать большие наборы данных с минимальным потреблением ресурсов. В 2001 году LZMA стал основным алгоритмом сжатия формата 7z, который быстро завоевал популярность благодаря своей выдающейся производительности. Кроме того, алгоритм был интегрирован во многие архиваторы и системы хранения данных, в частности в программные продукты с открытым исходным кодом. Сегодня LZMA продолжает развиваться, сохраняя свою актуальность благодаря постоянным обновлениям и оптимизации, укрепляя свои позиции незаменимого инструмента в цифровом мире.
Принципы алгоритма LZMA
Алгоритм LZMA основан на использовании последовательных повторений данных для достижения высокой степени сжатия. Основная идея алгоритма — построить и сохранить словарь, содержащий ранее встречавшиеся подстроки, которые затем заменяются ссылками в этом словаре. Это позволяет значительно сократить объем данных, подлежащих хранению или передаче. Одной из ключевых особенностей LZMA является использование кодирования диапазона вместо кодирования Хаффмана. Кодирование диапазона обеспечивает лучшее сжатие, близкое к энтропии данных, и использует двоичный формат, избегая медленных операций целочисленного деления.
LZMA использует алгоритм LZ77 для поиска самых длинных совпадений в буфере поиска и буфере предсказания, записывая их в сжатый файл в виде тройки (расстояние, длина, следующий символ). Если совпадение не найдено, к файлу добавляется байт в диапазоне [0,255]. Если совпадение найдено, записывается пара значений (расстояние и длина), закодированных методом кодирования диапазона.
Чтобы повысить эффективность за счет большого буфера поиска, алгоритм сохраняет 4 наиболее распространенных расстояния в специальном массиве истории расстояний. Если какое-либо из этих расстояний появляется снова, оно заменяется 2-битным кодом, ссылающимся на массив истории расстояний, что сокращает объем информации, необходимой для хранения совпадения.
LZMA использует 2-байтовый хэш (текущий и следующий байт) для поиска совпадений в буфере поиска. Размер хэш-массива напрямую связан с размером словаря. Например, словарь размером 1 ГБ использует хеш-массив размером 512 МБ, что сводит к минимуму коллизии в функции хеширования.
Такой многоуровневый подход обеспечивает эффективное сжатие и хранение данных без значительного потребления ресурсов, что делает LZMA одним из наиболее эффективных алгоритмов сжатия данных.
Преимущества формата файла .lzma
Вот основные преимущества LZMA, делающие его привлекательным выбором для многих приложений сжатия данных.
- Высокая степень сжатия: LZMA обеспечивает один из самых высоких коэффициентов сжатия среди существующих алгоритмов, что позволяет значительно уменьшить размеры файлов. Средняя степень сжатия превышает 70% по сравнению с другими форматами архивов.
- Быстрая распаковка. Алгоритм оптимизирован для быстрой распаковки данных, что делает LZMA хорошо подходящим для использования в программных приложениях и системах хранения данных, где важно быстрое извлечение данных.
- Эффективное управление большими файлами. Благодаря большому размеру буфера поиска LZMA может эффективно обрабатывать большие объемы данных, сохраняя при этом высокую степень сжатия.
- Надежность и устойчивость к повреждениям: LZMA обеспечивает высокую устойчивость к повреждению данных. Даже если при хранении или передаче возникают ошибки, его конструкция позволяет в некоторой степени исправить ошибки, минимизируя потерю данных и обеспечивая целостность вашей информации при длительном хранении.
- Открытый исходный код: Открытый исходный код алгоритма LZMA облегчает его широкое внедрение, адаптацию и интеграцию в различные программные решения, способствуя его внедрению и постоянному развитию.
Операции, поддерживаемые архивом LZMA
Aspose.ZIP позволяет пользователям извлекать как отдельные файлы, так и весь архив. В .NET вы можете использовать LzmaArchiveClass , чтобы открыть файл .lzma, затем просмотреть его записи и извлечь их в нужное место. Похожий подход используется в Java, где вы используете LzmaArchive для открытия файла .lzma и извлечения записей. Благодаря Aspose.ZIP эти операции становятся простыми и удобными для пользователей любого уровня.
Структура ЛЗМА
Хотя можно с уверенностью сказать, что LZMA находится под сильным влиянием LZ77 (Lempel-Ziv 1977) и LZ78 (Lempel-Ziv 1978), правильнее было бы описать LZMA как эволюцию этих алгоритмов, включающую значительные улучшения.
- Кодирование диапазона: LZMA заменяет кодирование Хаффмана кодированием диапазона, более эффективным методом представления данных.
- История расстояний. LZMA хранит историю часто используемых расстояний, ускоряя обнаружение совпадений.
- Хеш-таблица: LZMA использует хеш-таблицу для ускорения поиска совпадающих последовательностей.
- Прогнозное моделирование. LZMA включает в себя методы прогнозного моделирования для прогнозирования будущих шаблонов данных, что еще больше улучшает сжатие.
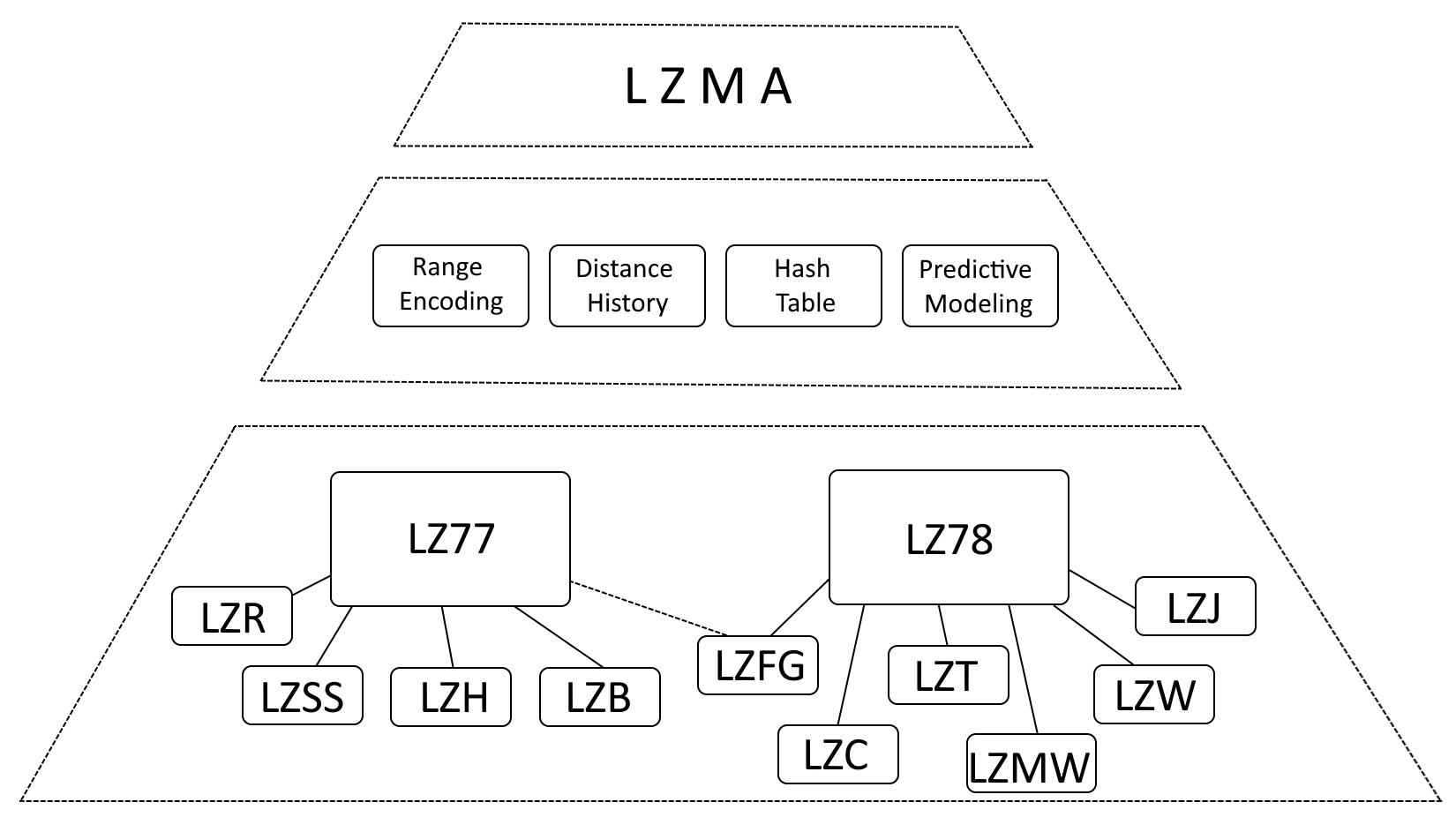
Внутренняя структура архива LZMA
- Метаданные файла. Подобно tar-архиву, каждый файл хранит основную информацию, такую как время изменения и разрешения. Однако этот раздел является гибким и позволяет опускать или включать дополнительные детали, такие как списки управления доступом (ACL) или расширенные атрибуты (EA), в зависимости от ваших потребностей. Рекомендуется включать надежную хеш-функцию (например, SHA1) для обычных файлов, чтобы обеспечить целостность данных.
- Несколько потоков контента. В отличие от традиционных архивов, файлы могут иметь более одного потока данных во внутреннем файле данных. Это полезно для хранения расширенных атрибутов или ветвей ресурсов, связанных с файлом.
- Заголовки. Внутренний индексный файл содержит заголовки файлов, зеркально отображающие заголовки, разбросанные по всему внутреннему файлу данных. Но при раздельном хранении заголовки индексов должны ссылаться на начальную позицию соответствующих им данных в файле данных. Кроме того, записи каталога в индексе перечисляют содержащиеся в них файлы и соответствующие им смещения во внутреннем файловом индексе.
- Обоснование дублирования метаданных. Такой выбор конструкции обеспечивает как эффективную потоковую передачу/декодирование данных, так и произвольный доступ к файлам. Кроме того, метаданные хорошо сжимаются, что приводит к минимальным затратам на хранение. Тесты показывают, что метаданные обычно занимают менее 0,3% дискового пространства, поэтому компромисс оправдан.
- Заголовки блоков. Заголовки блоков, как и внешний файл, содержат информацию о размере блока и последовательность уникальных идентификаторов.
Примеры использования LZMA Python
С помощью API Aspose.ZIP через Python вы можете легко управлять архивами LZMA в своих приложениях, устраняя необходимость в другом внешнем программном обеспечении. API включает в себя класс LzmaArchive , который упрощает работу с архивами LZMA, и класс LzmaCompressionSettings , который позволяет настраивать параметры сжатия для оптимальной производительности и уменьшения размера файла.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Дополнительная информация о LZMA-архивах
Часто Задаваемые Вопросы
1. Какие форматы файлов используют сжатие LZMA?
LZMA — это не сам формат файла, а алгоритм сжатия, используемый в различных форматах архивов. Некоторые распространенные примеры включают 7z, XZ и иногда ZIP. Когда вы встретите файл с этими расширениями, он может быть сжат с помощью LZM.
2. Является ли LZMA открытым исходным кодом?
Да, LZMA — это алгоритм с открытым исходным кодом, что делает его бесплатным для использования и интеграции в различные программные решения. Открытый исходный код способствовал его широкому распространению и постоянному развитию.
3. Какие есть альтернативы LZMA?
Некоторые алгоритмы сжатия предлагают разные компромиссы. ZIP хорошо сочетает сжатие и скорость, BZIP2 обеспечивает высокое сжатие за счет скорости по сравнению с LZMA, а XZ, основанный на LZMA, обеспечивает сильное сжатие и обычно используется в средах Linux.