LZMA filformat
Hur man kommer åt, modifierar, genererar, dekomprimerar och transformerar LZMA-filer
LZMA arkivfilformat
LZMA (Lempel-Ziv-Markov chain algorithm) är en modern datakomprimeringsalgoritm känd för sin höga effektivitet och exceptionella kompressionsförhållande. LZMA används i stor utsträckning i arkivformat som
7z
, och minskar effektivt filstorleken utan en betydande uppoffring av dekompressionshastigheten. LZMA-arkiv garanterar bevarandet av datakvalitet och integritet, vilket gör dem till en perfekt lösning för att lagra och hantera stora datamängder effektivt.
Den största fördelen med LZMA är dess förmåga att hantera stora filer och komplexa datastrukturer med minimal förlust. Genom att använda LZMA kan du optimera diskutrymme och underlättar filöverföring över Internet på grund av en mindre arkivstorlek. Detta gör LZMA till ett populärt val bland utvecklare och systemadministratörer för effektiv datahantering.
Om LZMA Arkivinformation
LZMA-arkiv stöder parallellisering, vilket möjliggör effektiv användning av flerkärniga processorer för snabbare filkomprimering och dekomprimering. Dessutom är LZMA känt för sin höga motståndskraft mot skador, vilket gör det till ett pålitligt val för långtidslagring av viktig data. Algoritmen har även öppen källkod, vilket underlättar dess breda implementering och anpassning i olika mjukvarulösningar. På grund av sina fördelar förblir LZMA ett av de mest effektiva komprimeringsformaten, vilket ger optimal datahantering för användare över hela världen.
Utvecklingen av LZMA
LZMA-algoritmen, utvecklad av Igor Pavlov 1998 som en del av 7-Zip-projektet, syftade till att skapa en mycket effektiv datakomprimeringsmetod. Till en början byggde den på de klassiska LZ77-algoritmerna, med tekniker som avsevärt ökade kompressionseffektiviteten. Gradvis fick LZMA erkännande för sin förmåga att bearbeta stora datamängder med minimal resursförbrukning. 2001 blev LZMA kärnkomprimeringsalgoritmen för 7z-formatet, som snabbt vann popularitet på grund av dess enastående prestanda. Dessutom har algoritmen integrerats i många arkiverings- och datalagringssystem, särskilt mjukvaruprodukter med öppen källkod. Idag fortsätter LZMA att utvecklas och bibehåller sin relevans genom kontinuerliga uppdateringar och optimeringar, vilket befäster sin position som ett oumbärligt verktyg i den digitala världen.
Principer för LZMA-algoritmen
LZMA-algoritmen är baserad på användningen av sekventiella upprepningar i data för att uppnå en hög grad av komprimering. Huvudidén med algoritmen är att bygga och lagra en ordbok som innehåller tidigare påträffade delsträngar, som sedan ersätts av referenser i denna ordbok. Detta gör att du kan avsevärt minska mängden data som ska lagras eller överföras. En av nyckelfunktionerna hos LZMA är dess användning av intervallkodning istället för Huffman-kodning. Områdeskodning erbjuder bättre komprimering närmare dataens entropi och använder ett binärt format, vilket undviker långsamma heltalsdelningsoperationer.
LZMA använder LZ77-algoritmen för att hitta de längsta matchningarna i sökbufferten och prediktionsbufferten, och skriver dem till en komprimerad fil i form av en triplett (avstånd, längd, nästa tecken). Om ingen matchning hittas läggs en byte i intervallet [0,255] till filen. Om en matchning hittas, registreras ett par värden (avstånd och längd) kodade med intervallkodningsmetoden.
För att förbättra effektiviteten med en stor sökbuffert, lagrar algoritmen de 4 vanligaste avstånden i en dedikerad avståndshistorik. Om något av dessa avstånd dyker upp igen ersätts de med en 2-bitars kod som refererar till avståndshistoriken, vilket minskar den information som behövs för att lagra matchen.
LZMA använder en 2-byte hash (den nuvarande byten och nästa byte) för att hitta matchningar i sökbufferten. Storleken på hash-arrayen är direkt kopplad till ordbokens storlek. Till exempel använder en ordbok på 1 GB en hash-array på 512 MB, vilket minimerar kollisioner i hashfunktionen.
Denna multi-level approach ger effektiv datakomprimering och lagring utan betydande resursförbrukning, vilket gör LZMA till en av de mest effektiva datakomprimeringsalgoritmerna.
Fördelar med filformatet .lzma
Här är de viktigaste fördelarna med LZMA, vilket gör det till ett attraktivt val för många datakomprimeringsapplikationer.
- Högt komprimeringsförhållande: LZMA ger en av de högsta kompressionsförhållandena bland befintliga algoritmer, vilket gör att du kan minska filstorlekarna avsevärt. Den genomsnittliga komprimeringsgraden överstiger 70 % jämfört med andra arkivformat.
- Snabb dekomprimering: Algoritmen är optimerad för snabb datadekomprimering, vilket gör LZMA väl lämpad för användning i mjukvaruapplikationer och lagringssystem där snabb datahämtning är avgörande.
- Effektiv hantering av stora filer: På grund av sökbuffertens stora storlek kan LZMA effektivt bearbeta stora mängder data samtidigt som en hög komprimeringshastighet bibehålls.
- Tillförlitlighet och skadetolerans: LZMA ger hög motståndskraft mot dataskador. Även om fel uppstår under lagring eller överföring, tillåter dess design viss felkorrigering, vilket minimerar dataförlust och säkerställer integriteten hos din information under långtidslagring.
- Öppen källkod: LZMA-algoritmens öppen källkod underlättar dess omfattande implementering, anpassning och integrering i olika mjukvarulösningar, vilket främjar användningen och den pågående utvecklingen.
LZMA Archive Supported Operations
Aspose.ZIP tillåter användare att extrahera både enskilda filer och hela arkivet. För .NET kan du använda LzmaArchiveClass för att öppna en .lzma-fil, sedan kan du gå igenom dess poster och extrahera dem till önskad plats. Ett liknande tillvägagångssätt används i Java, där du använder LzmaArchive för att öppna .lzma-filen och extrahera posterna. Tack vare Aspose.ZIP blir dessa operationer enkla och bekväma för användare på alla nivåer.
LZMA struktur
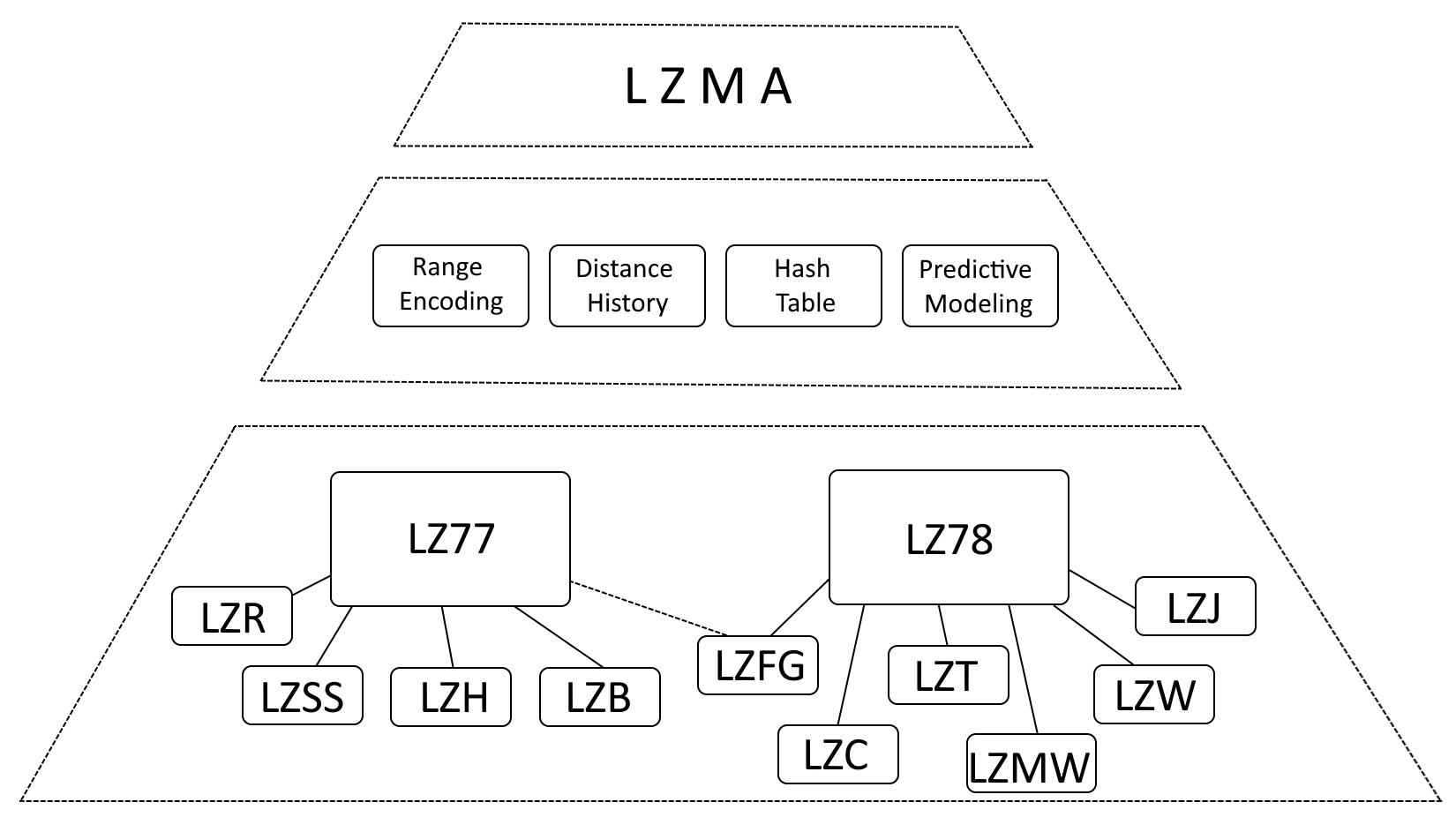
Även om det är korrekt att säga att LZMA är starkt påverkad av LZ77 (Lempel-Ziv 1977) och LZ78 (Lempel-Ziv 1978), är det mer exakt att beskriva LZMA som en utveckling av dessa algoritmer, med betydande förbättringar.
- Räckviddskodning: LZMA ersätter Huffman-kodning med intervallkodning, en mer effektiv datarepresentationsmetod.
- Avståndshistorik: LZMA har en historik över ofta använda avstånd, vilket accelererar matchdetektering.
- Hashtabell: LZMA använder en hashtabell för att påskynda sökningen efter matchande sekvenser.
- Predictive Modeling: LZMA innehåller tekniker för prediktiv modellering för att förutse kommande datamönster, vilket ytterligare förbättrar komprimeringen.
Inre LZMA-arkivstruktur
- Filmetadata - I likhet med ett tar-arkiv lagrar varje fil grundläggande information som ändringstid och behörigheter. Det här avsnittet är dock flexibelt och tillåter att utelämna eller inkludera ytterligare detaljer som åtkomstkontrollistor (ACL) eller utökade attribut (EA) baserat på dina behov. Det rekommenderas att inkludera en stark hash-funktion (som SHA1) för vanliga filer för att säkerställa dataintegritet.
- Flera innehållsströmmar - Till skillnad från traditionella arkiv kan filer ha mer än en dataström i den inre datafilen. Detta är användbart för att lagra utökade attribut eller resursgaffel som är associerade med filen.
- Rubriker - Den inre indexfilen innehåller filrubriker som speglar de som är utspridda i hela den inre datafilen. Men när de lagras separat måste indexrubrikerna referera till startpositionen för deras motsvarande data i datafilen. Dessutom listar katalogposter i indexet deras innehållna filer och deras motsvarande förskjutningar inom det inre filindexet.
- Rational för dubbletter av metadata - Detta designval säkerställer både effektiv dataströmning/avkodning och slumpmässig filåtkomst. Dessutom komprimeras metadata bra, vilket resulterar i minimal lagringskostnad. Tester visar att metadata vanligtvis upptar mindre än 0,3 % av lagringsutrymmet, vilket gör avvägningen värd besväret.
- Blockhuvuden - Blockhuvuden, liknande den yttre filen, innehåller information om blockstorlek och en unik identifierarsekvens.
Exempel på användning av LZMA Python
Med Aspose.ZIP via Python API kan du enkelt hantera LZMA-arkiv i dina applikationer, vilket eliminerar behovet av annan extern programvara. API:et inkluderar LzmaArchive-klassen , som förenklar arbetet med LZMA-arkiv, och klassen LzmaCompressionSettings , som låter dig anpassa komprimeringsinställningarna för optimal prestanda och filstorleksminskning.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Ytterligare information om LZMA-arkiv
Folk har frågat
1. Vilka filformat använder LZMA-komprimering?
LZMA är inte ett filformat i sig utan en komprimeringsalgoritm som används inom olika arkivformat. Några vanliga exempel inkluderar 7z, XZ och ibland ZIP. När du stöter på en fil med dessa tillägg kan den komprimeras med LZM
2. Är LZMA öppen källkod?
Ja, LZMA är en öppen källkodsalgoritm som gör den fritt tillgänglig för användning och integration i olika mjukvarulösningar. Denna natur med öppen källkod har bidragit till dess utbredda antagande och pågående utveckling.
3. Vad finns det för alternativ till LZMA?
Flera komprimeringsalgoritmer erbjuder olika avvägningar. ZIP balanserar komprimering och hastighet väl, BZIP2 ger hög komprimering till priset av hastighet jämfört med LZMA, medan XZ, baserat på LZMA, erbjuder stark komprimering och används ofta i Linux-miljöer.