Định dạng tệp LZMA
Cách truy cập, sửa đổi, tạo, giải nén và chuyển đổi tệp LZMA
Định dạng tệp lưu trữ LZMA
LZMA (thuật toán chuỗi Lempel-Ziv-Markov) là thuật toán nén dữ liệu hiện đại nổi tiếng với hiệu suất cao và tỷ lệ nén đặc biệt. Được sử dụng rộng rãi trong các định dạng lưu trữ như
7z
, LZMA giảm kích thước tệp một cách hiệu quả mà không ảnh hưởng đáng kể đến tốc độ giải nén. Kho lưu trữ LZMA đảm bảo duy trì chất lượng và tính toàn vẹn của dữ liệu, khiến chúng trở thành giải pháp hoàn hảo để lưu trữ và quản lý các tập dữ liệu lớn một cách hiệu quả.
Ưu điểm chính của LZMA là khả năng xử lý các tệp lớn và cấu trúc dữ liệu phức tạp với tổn thất tối thiểu. Sử dụng LZMA cho phép bạn tối ưu hóa dung lượng ổ đĩa và tạo điều kiện truyền tệp qua Internet do kích thước lưu trữ nhỏ hơn. Điều này làm cho LZMA trở thành lựa chọn phổ biến của các nhà phát triển và quản trị viên hệ thống để quản lý dữ liệu hiệu quả.
Giới thiệu về thông tin lưu trữ LZMA
Các kho lưu trữ LZMA hỗ trợ song song hóa, cho phép sử dụng hiệu quả bộ xử lý đa lõi để nén và giải nén tệp nhanh hơn. Ngoài ra, LZMA còn được chú ý nhờ khả năng chống chịu hư hại cao, khiến nó trở thành lựa chọn đáng tin cậy để lưu trữ lâu dài các dữ liệu quan trọng. Thuật toán cũng có mã nguồn mở, tạo điều kiện thuận lợi cho việc triển khai và thích ứng rộng rãi trong các giải pháp phần mềm khác nhau. Do những ưu điểm của nó, LZMA vẫn là một trong những định dạng nén hiệu quả nhất, cung cấp khả năng quản lý dữ liệu tối ưu cho người dùng trên toàn thế giới.
Sự phát triển của LZMA
Thuật toán LZMA, được phát triển bởi Igor Pavlov vào năm 1998 như một phần của dự án 7-Zip, nhằm tạo ra một phương pháp nén dữ liệu hiệu quả cao. Ban đầu, nó được xây dựng dựa trên thuật toán LZ77 cổ điển, kết hợp các kỹ thuật giúp tăng hiệu quả nén đáng kể. Dần dần, LZMA được công nhận về khả năng xử lý các tập dữ liệu lớn với mức tiêu thụ tài nguyên tối thiểu. Năm 2001, LZMA trở thành thuật toán nén cốt lõi cho định dạng 7z, thuật toán này nhanh chóng trở nên phổ biến nhờ hiệu suất vượt trội của nó. Hơn nữa, thuật toán này đã được tích hợp vào nhiều hệ thống lưu trữ và lưu trữ dữ liệu, đặc biệt là các sản phẩm phần mềm nguồn mở. Ngày nay, LZMA tiếp tục phát triển, duy trì sự liên quan của mình thông qua các bản cập nhật và tối ưu hóa liên tục, củng cố vị trí của mình như một công cụ không thể thiếu trong thế giới kỹ thuật số.
Nguyên tắc của thuật toán LZMA
Thuật toán LZMA dựa trên việc sử dụng các lần lặp lại tuần tự trong dữ liệu để đạt được mức độ nén cao. Ý tưởng chính của thuật toán là xây dựng và lưu trữ một từ điển chứa các chuỗi con đã gặp trước đó, sau đó được thay thế bằng các tham chiếu trong từ điển này. Điều này cho phép bạn giảm đáng kể lượng dữ liệu được lưu trữ hoặc truyền đi. Một trong những tính năng chính của LZMA là việc sử dụng mã hóa phạm vi thay vì mã hóa Huffman. Mã hóa phạm vi cung cấp khả năng nén tốt hơn gần với entropy của dữ liệu và sử dụng định dạng nhị phân, tránh các thao tác chia số nguyên chậm.
LZMA sử dụng thuật toán LZ77 để tìm các kết quả khớp dài nhất trong bộ đệm tìm kiếm và bộ đệm dự đoán, ghi chúng vào tệp nén dưới dạng bộ ba (khoảng cách, độ dài, ký tự tiếp theo). Nếu không tìm thấy kết quả khớp, một byte trong phạm vi [0,255] sẽ được thêm vào tệp. Nếu tìm thấy kết quả khớp, một cặp giá trị (khoảng cách và độ dài) được mã hóa bằng phương pháp mã hóa phạm vi sẽ được ghi lại.
Để nâng cao hiệu quả với bộ đệm tìm kiếm lớn, thuật toán lưu trữ 4 khoảng cách phổ biến nhất trong một mảng lịch sử khoảng cách chuyên dụng. Nếu bất kỳ khoảng cách nào trong số này xuất hiện trở lại, chúng sẽ được thay thế bằng mã 2 bit tham chiếu mảng lịch sử khoảng cách, giảm thông tin cần thiết để lưu trữ kết quả khớp.
LZMA sử dụng hàm băm 2 byte (byte hiện tại và byte tiếp theo) để tìm kết quả khớp trong bộ đệm tìm kiếm. Kích thước của mảng băm được gắn trực tiếp với kích thước từ điển. Ví dụ: từ điển 1 GB sử dụng mảng băm 512 MB, giúp giảm thiểu xung đột trong hàm băm.
Cách tiếp cận đa cấp này cung cấp khả năng nén và lưu trữ dữ liệu hiệu quả mà không tiêu tốn nhiều tài nguyên, khiến LZMA trở thành một trong những thuật toán nén dữ liệu hiệu quả nhất.
Lợi ích của định dạng tệp .lzma
Dưới đây là những ưu điểm chính của LZMA, khiến nó trở thành lựa chọn hấp dẫn cho nhiều ứng dụng nén dữ liệu.
- Tỷ lệ nén cao: LZMA cung cấp một trong những tỷ lệ nén cao nhất trong số các thuật toán hiện có, cho phép bạn giảm đáng kể kích thước tệp. Tỷ lệ nén trung bình vượt quá 70% so với các định dạng lưu trữ khác.
- Giải nén nhanh: Thuật toán được tối ưu hóa để giải nén dữ liệu nhanh, giúp LZMA rất phù hợp để sử dụng trong các ứng dụng phần mềm và hệ thống lưu trữ nơi cần truy xuất dữ liệu nhanh chóng.
- Quản lý hiệu quả các tệp lớn: Do kích thước lớn của bộ đệm tìm kiếm, LZMA có thể xử lý lượng lớn dữ liệu một cách hiệu quả trong khi vẫn duy trì tốc độ nén cao.
- Độ tin cậy và khả năng chịu hư hỏng: LZMA cung cấp khả năng chống hư hỏng dữ liệu cao. Ngay cả khi xảy ra lỗi trong quá trình lưu trữ hoặc truyền tải, thiết kế của nó vẫn cho phép sửa một số lỗi, giảm thiểu mất dữ liệu và đảm bảo tính toàn vẹn của thông tin của bạn trong quá trình lưu trữ lâu dài.
- Mã nguồn mở: Bản chất nguồn mở của thuật toán LZMA tạo điều kiện thuận lợi cho việc triển khai, điều chỉnh và tích hợp rộng rãi vào các giải pháp phần mềm khác nhau, thúc đẩy việc áp dụng và phát triển liên tục.
Lưu trữ LZMA Hoạt động được hỗ trợ
Aspose.ZIP cho phép người dùng trích xuất cả tệp riêng lẻ và toàn bộ kho lưu trữ. Đối với .NET, bạn có thể sử dụng LzmaArchiveClass để mở tệp .lzma, sau đó bạn có thể duyệt qua các bản ghi của nó và trích xuất chúng đến vị trí mong muốn. Một cách tiếp cận tương tự được sử dụng trong Java, trong đó bạn sử dụng LzmaArchive để mở tệp .lzma và trích xuất các bản ghi. Nhờ Aspose.ZIP, các thao tác này trở nên đơn giản và thuận tiện cho người dùng ở mọi cấp độ.
Cấu trúc LZMA
Mặc dù chính xác khi nói rằng LZMA bị ảnh hưởng nặng nề bởi LZ77 (Lempel-Ziv 1977) và LZ78 (Lempel-Ziv 1978), nhưng sẽ chính xác hơn khi mô tả LZMA như một sự phát triển của các thuật toán này, kết hợp những cải tiến đáng kể.
- Mã hóa phạm vi: LZMA thay thế mã hóa Huffman bằng mã hóa phạm vi, một phương pháp biểu diễn dữ liệu hiệu quả hơn.
- Lịch sử khoảng cách: LZMA duy trì lịch sử các khoảng cách được sử dụng thường xuyên, tăng tốc độ phát hiện khớp.
- Bảng băm: LZMA sử dụng bảng băm để đẩy nhanh việc tìm kiếm các chuỗi phù hợp.
- Mô hình dự đoán: LZMA kết hợp các kỹ thuật lập mô hình dự đoán để dự đoán các mẫu dữ liệu sắp tới, tăng cường khả năng nén hơn nữa.
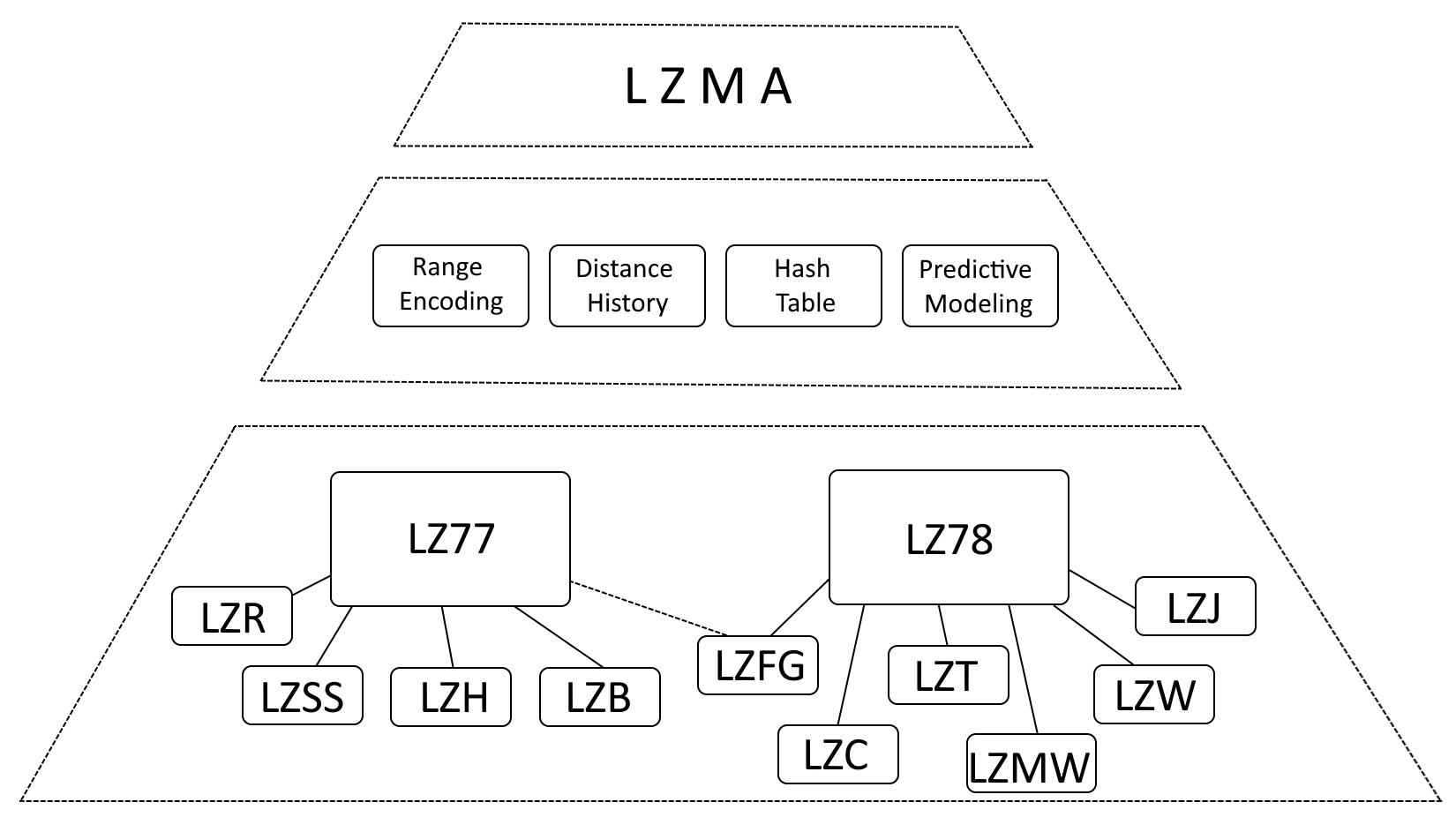
Cấu trúc lưu trữ LZMA bên trong
- Siêu dữ liệu tệp - Tương tự như kho lưu trữ tar, mỗi tệp lưu trữ thông tin cơ bản như thời gian sửa đổi và quyền. Tuy nhiên, phần này linh hoạt và cho phép bỏ qua hoặc bao gồm các chi tiết bổ sung như danh sách kiểm soát truy cập (ACL) hoặc thuộc tính mở rộng (EA) dựa trên nhu cầu của bạn. Bạn nên thêm hàm băm mạnh (như SHA1) cho các tệp thông thường để đảm bảo tính toàn vẹn của dữ liệu.
- Nhiều luồng nội dung - Không giống như các kho lưu trữ truyền thống, các tệp có thể có nhiều luồng dữ liệu trong tệp dữ liệu bên trong. Điều này rất hữu ích để lưu trữ các thuộc tính mở rộng hoặc các nhánh tài nguyên được liên kết với tệp.
- Tiêu đề - Tệp chỉ mục bên trong chứa các tiêu đề tệp, phản ánh những tiêu đề nằm rải rác trong tệp dữ liệu bên trong. Tuy nhiên, khi được lưu trữ riêng biệt, các tiêu đề chỉ mục phải tham chiếu đến vị trí bắt đầu của dữ liệu tương ứng trong tệp dữ liệu. Ngoài ra, các mục nhập thư mục trong chỉ mục liệt kê các tệp chứa của chúng và các phần bù tương ứng của chúng trong chỉ mục tệp bên trong.
- Cơ sở lý luận cho siêu dữ liệu trùng lặp - Lựa chọn thiết kế này đảm bảo cả việc truyền/giải mã dữ liệu hiệu quả và truy cập tệp ngẫu nhiên. Ngoài ra, siêu dữ liệu nén tốt, dẫn đến chi phí lưu trữ ở mức tối thiểu. Các thử nghiệm cho thấy siêu dữ liệu thường chiếm ít hơn 0,3% dung lượng lưu trữ, khiến việc đánh đổi trở nên đáng giá.
- Tiêu đề khối - Tiêu đề khối, tương tự như tệp bên ngoài, chứa thông tin kích thước khối và chuỗi nhận dạng duy nhất.
Ví dụ về việc sử dụng LZMA Python
Với API Aspose.ZIP via Python , bạn có thể dễ dàng quản lý các kho lưu trữ LZMA trong ứng dụng của mình, loại bỏ nhu cầu sử dụng phần mềm bên ngoài khác. API bao gồm LzmaArchive class , giúp đơn giản hóa thao tác với các kho lưu trữ LZMA và LzmaCompressionSettings class , cho phép bạn tùy chỉnh cài đặt nén để có hiệu suất tối ưu và giảm kích thước tệp.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Thông tin bổ sung về kho lưu trữ LZMA
Mọi người đã hỏi
1. Những định dạng tập tin nào sử dụng nén LZMA?
LZMA bản thân nó không phải là một định dạng tệp mà là một thuật toán nén được sử dụng trong các định dạng lưu trữ khác nhau. Một số ví dụ phổ biến bao gồm 7z, Hz và đôi khi là ZIP. Khi bạn gặp một tệp có các phần mở rộng này, nó có thể được nén bằng LZM
2. LZMA có phải là nguồn mở không?
Có, LZMA là một thuật toán nguồn mở, giúp thuật toán này có sẵn miễn phí để sử dụng và tích hợp vào các giải pháp phần mềm khác nhau. Bản chất nguồn mở này đã góp phần vào việc áp dụng rộng rãi và phát triển liên tục.
3. Một số lựa chọn thay thế cho LZMA là gì?
Một số thuật toán nén đưa ra những sự cân bằng khác nhau. ZIP cân bằng tốt giữa khả năng nén và tốc độ, BZIP2 cung cấp khả năng nén cao với chi phí tốc độ so với LZMA, trong khi XX, dựa trên LZMA, cung cấp khả năng nén mạnh và thường được sử dụng trong môi trường Linux.