LZMA 文件格式
如何存取、修改、產生、解壓縮和轉換 LZMA 文件
LZMA 存檔檔案格式
LZMA(Lempel-Ziv-Markov 鏈演算法)是一種現代資料壓縮演算法,以其高效率和出色的壓縮比而聞名。 LZMA 廣泛用於
7z
等存檔格式,可有效縮小檔案大小,而不會顯著犧牲解壓縮速度。 LZMA 檔案保證了資料品質和完整性的保存,使其成為高效儲存和管理大型資料集的完美解決方案。
LZMA 的主要優點是能夠以最小的損失處理大檔案和複雜的資料結構。使用 LZMA 可以最佳化磁碟空間,並且由於存檔大小較小,因此可以方便透過 Internet 傳輸檔案。這使得 LZMA 成為開發人員和系統管理員進行高效資料管理的熱門選擇。
關於 LZMA 檔案資訊
LZMA 存檔支援並行化,從而可以有效利用多核心處理器來實現更快的檔案壓縮和解壓縮。此外,LZMA 以其高抗損壞性而聞名,使其成為長期儲存重要資料的可靠選擇。該演算法還具有開源程式碼,有利於其在各種軟體解決方案中的廣泛實施和適配。由於其優勢,LZMA 仍然是最有效的壓縮格式之一,為全球用戶提供最佳的資料管理。
LZMA 的演變
LZMA 演算法由 Igor Pavlov 於 1998 年作為 7-Zip 專案的一部分開發,旨在創建一種高效的資料壓縮方法。最初,它建立在經典的 LZ77 演算法的基礎上,結合了顯著提高壓縮效率的技術。逐漸地,LZMA 因其以最少的資源消耗處理大型資料集的能力而獲得認可。 2001年,LZMA成為7z格式的核心壓縮演算法,因其出色的性能而迅速流行起來。 此外,該演算法已整合到眾多歸檔器和資料儲存系統中,特別是開源軟體產品中。如今,LZMA 不斷發展,透過不斷更新和優化來保持其相關性,鞏固其作為數位世界不可或缺工具的地位。
LZMA演算法原理
LZMA 演算法是基於在資料中使用順序重複來實現高度壓縮。該演算法的主要思想是建立並儲存一個包含先前遇到的子字串的字典,然後用該字典中的引用替換這些子字串。這使您可以顯著減少要儲存或傳輸的資料量。 LZMA 的關鍵特徵之一是它使用範圍編碼而不是霍夫曼編碼。範圍編碼提供更接近資料熵的更好壓縮,並利用二進位格式,避免緩慢的整數除法操作。
LZMA 使用 LZ77 演算法在搜尋緩衝區和預測緩衝區中尋找最長匹配,並將它們以三元組(距離、長度、下一個字元)的形式寫入壓縮檔案。如果未找到符合項,則會將 [0,255] 範圍內的位元組附加到檔案中。如果找到匹配,則記錄透過範圍編碼方法編碼的一對值(距離和長度)。
為了提高大型搜尋緩衝區的效率,演算法將 4 個最常見的距離儲存在專用距離歷史數組中。如果任何這些距離再次出現,它們將被替換為引用距離歷史數組的 2 位元代碼,從而減少儲存匹配所需的資訊。
LZMA 使用 2 位元組散列(當前位元組和下一個位元組)在搜尋緩衝區中尋找匹配項。哈希數組的大小直接與字典的大小相關。例如,1 GB 字典使用 512 MB 雜湊數組,這可以最大限度地減少雜湊函數中的衝突。
這種多層次方法提供了高效的資料壓縮和存儲,而不消耗大量資源,使 LZMA 成為最高效的資料壓縮演算法之一。
.lzma 檔案格式的優點
以下是 LZMA 的主要優點,使其成為許多資料壓縮應用程式的有吸引力的選擇。
- 高壓縮比: LZMA 提供現有演算法中最高的壓縮比之一,可讓您大幅縮小檔案大小。與其他存檔格式相比,平均壓縮率超過 70%。
- 快速解壓縮: 此演算法針對快速資料解壓縮進行了最佳化,使得 LZMA 非常適合在需要快速資料檢索的軟體應用程式和儲存系統中使用。
- 大檔案的高效管理: 由於搜尋緩衝區尺寸較大,LZMA 可以高效處理大量數據,同時保持高壓縮率。
- 可靠性和損壞容限: LZMA 提供對資料損壞的高抵抗力。即使在儲存或傳輸過程中出現錯誤,其設計也可以進行一些錯誤修正,最大限度地減少資料遺失並確保長期儲存期間資訊的完整性。
- 開源程式碼: LZMA 演算法的開源性質有利於其廣泛實施、適應和整合到各種軟體解決方案中,從而促進其採用和持續開發。
LZMA 存檔支援的操作
Aspose.ZIP 允許使用者提取單一檔案和整個存檔。對於 .NET,您可以使用 LzmaArchiveClass 開啟 .lzma 文件,然後您可以逐步瀏覽其記錄並將它們提取到所需位置。 Java 中使用了類似的方法,您可以使用 LzmaArchive 開啟 .lzma 檔案並提取記錄。借助 Aspose.ZIP,這些操作對於任何級別的用戶來說都變得簡單方便。
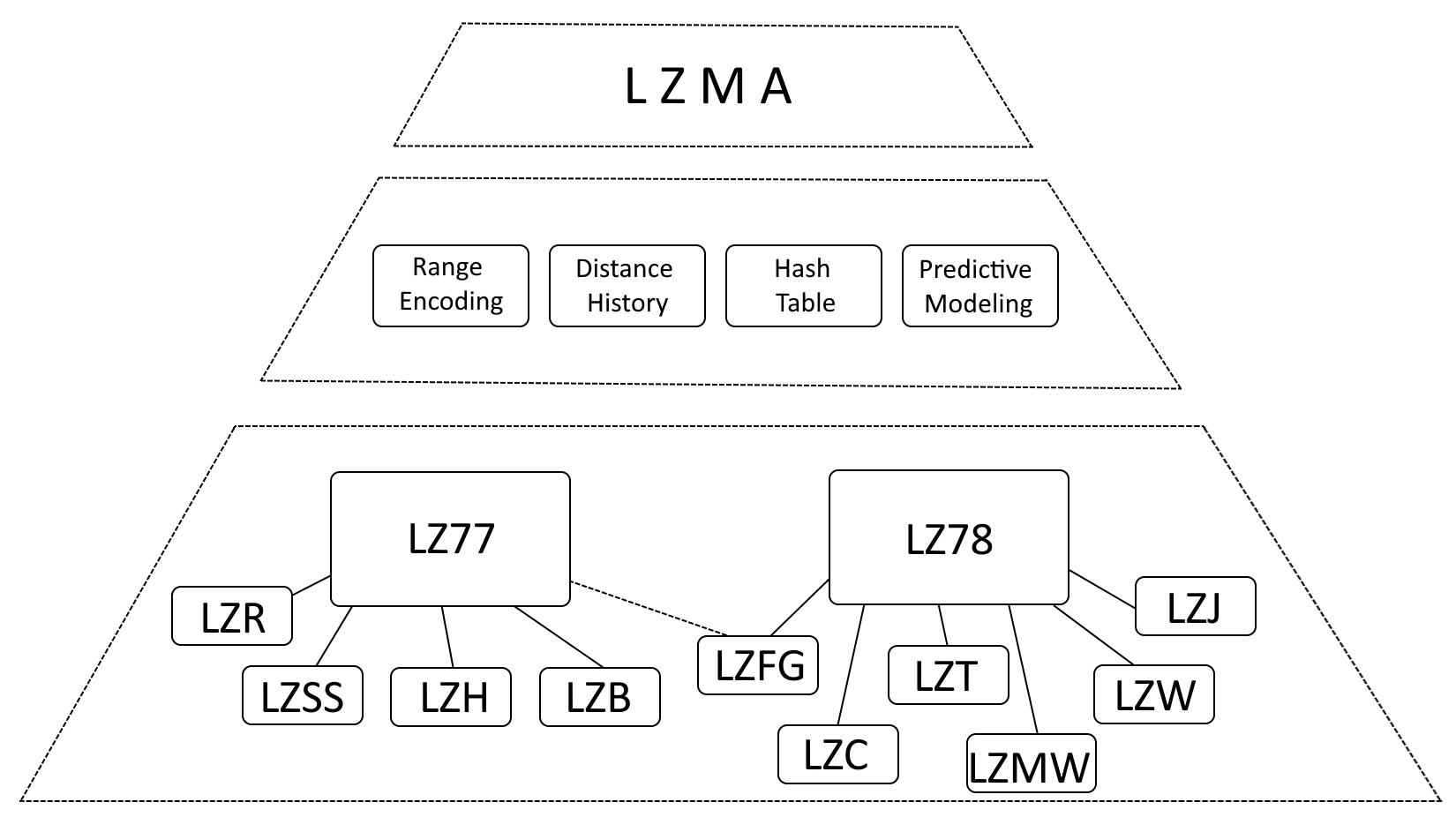
LZMA結構式
雖然可以準確地說LZMA 深受LZ77 (Lempel-Ziv 1977) 和LZ78 (Lempel-Ziv 1978) 的影響,但更準確的說法是將LZMA 描述為這些演算法的演進,並結合了顯著的增強功能。
- 範圍編碼:LZMA以範圍編碼取代了霍夫曼編碼,這是一種更有效的資料表示方法。
- 距離歷史記錄:LZMA 維護常用距離的歷史記錄,加速匹配檢測。
- 哈希表:LZMA 使用哈希表來加快匹配序列的搜尋。
- 預測建模:LZMA 結合了預測建模技術來預測即將出現的資料模式,從而進一步增強壓縮。
內部 LZMA 檔案結構
- 檔案元資料 - 與 tar 檔案類似,每個檔案都儲存修改時間和權限等基本資訊。但是,此部分很靈活,允許根據您的需求省略或包含其他詳細信息,例如存取控制清單 (ACL) 或擴充屬性 (EA)。建議為常規檔案包含強大的雜湊函數(如 SHA1)以確保資料完整性。
- 多個內容流 - 與傳統存檔不同,檔案的內部資料檔案內可以有多個資料流。這對於儲存與檔案關聯的擴充屬性或資源分支非常有用。
- 標頭 - 內部索引檔案保存檔案標頭,鏡像那些分散在內部資料檔案中的標頭。但是,當單獨儲存時,索引標頭必須引用資料檔案中對應資料的起始位置。此外,索引中的目錄條目列出了它們所包含的檔案以及它們在內部檔案索引中的相應偏移量。
- 重複元資料的基本原理 - 這種設計選擇確保了高效的資料流/解碼和隨機檔案存取。此外,元資料壓縮良好,從而將儲存開銷降至最低。測試顯示元資料通常佔用不到 0.3% 的儲存空間,因此這種權衡是值得的。
- 區塊頭 - 區塊頭與外部檔案類似,包含區塊大小資訊和唯一識別碼序列。
使用 LZMA Python 的範例
透過 Aspose.ZIP via Python API,您可以輕鬆管理應用程式中的 LZMA 存檔,無需其他外部軟體。 API 包括 LzmaArchive 類別 ,它簡化了 LZMA 存檔的使用,以及 LzmaCompressionSettings 類別 ,它允許您自訂壓縮設定以獲得最佳效能和減少檔案大小。
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
有關 LZMA 檔案的其他信息
人們一直在問
1. 哪些檔案格式使用 LZMA 壓縮?
LZMA 本身不是一種檔案格式,而是一種在各種存檔格式中使用的壓縮演算法。一些常見的例子包括 7z、XZ,偶爾還有 ZIP。當您遇到具有這些擴展名的檔案時,它可能是使用 LZM 壓縮的
2. LZMA 是開源的嗎?
是的,LZMA 是一種開源演算法,可以免費使用並整合到各種軟體解決方案中。這種開源性質有助於其廣泛採用和持續發展。
3. LZMA 有哪些替代方案?
多種壓縮演算法提供不同的權衡。 ZIP很好地平衡了壓縮和速度,BZIP2相比LZMA以速度為代價提供高壓縮,而XZ基於LZMA,提供強壓縮,常用於Linux環境。