LZMA File Format
How to access, modify, generate, decompress and transform LZMA files
LZMA Archive File Format
LZMA (Lempel-Ziv-Markov chain algorithm) is a modern data compression algorithm renowned for its high efficiency and exceptional compression ratio. Widely used in archive formats like
7z
, LZMA effectively reduces file size without a significant sacrifice in decompression speed. LZMA archives guarantee the preservation of data quality and integrity, making them a perfect solution for storing and managing large datasets efficiently.
The main advantage of LZMA is its ability to handle large files and complex data structures with minimal loss. Using LZMA allows you to optimize disk space and facilitates file transfer over the Internet due to a smaller archive size. This makes LZMA a popular choice among developers and system administrators for efficient data management.
About LZMA Archive Information
LZMA archives support parallelization, which allows efficient use of multi-core processors for faster file compression and decompression. In addition, LZMA is noted for its high resistance to damage, making it a reliable choice for long-term storage of important data. The algorithm also has open source code, which facilitates its wide implementation and adaptation in various software solutions. Due to its advantages, LZMA remains one of the most efficient compression formats, providing optimal data management for users worldwide.
Evolution of the LZMA
The LZMA algorithm, developed by Igor Pavlov in 1998 as part of the 7-Zip project, aimed to create a highly efficient data compression method. Initially, it built upon the classic LZ77 algorithms, incorporating techniques that significantly boosted compression efficiency. Gradually, LZMA gained recognition for its ability to process large datasets with minimal resource consumption. In 2001, LZMA became the core compression algorithm for the 7z format, which swiftly gained popularity due to its outstanding performance. Furthermore, the algorithm has been integrated into numerous archivers and data storage systems, particularly open-source software products. Today, LZMA continues to evolve, maintaining its relevance through continuous updates and optimizations, solidifying its position as an indispensable tool in the digital world.
Principles of the LZMA algorithm
The LZMA algorithm is based on the use of sequential repetitions in the data to achieve a high degree of compression. The main idea of the algorithm is to build and store a dictionary containing previously encountered substrings, which are then replaced by references in this dictionary. This allows you to significantly reduce the amount of data to be stored or transmitted. One of the key feature of LZMA is its use of range encoding instead of Huffman coding. Range encoding offers better compression closer to the data’s entropy and utilizes a binary format, avoiding slow integer division operations.
LZMA uses the LZ77 algorithm to find the longest matches in the search buffer and the prediction buffer, writing them to a compressed file in the form of a triplet (distance, length, next character). If no match is found, a byte in the range [0,255] is appended to the file. If a match is found, a pair of values (distance and length) encoded by the range encoding method is recorded.
To improve efficiency with a large search buffer, the algorithm stores the 4 most common distances in a dedicated distance history array. If any of these distances reappear, they are replaced with a 2-bit code referencing the distance history array, reducing the information needed to store the match.
LZMA uses a 2-byte hash (the current byte and the next byte) to find matches in the search buffer. The size of the hash array is directly tied to the dictionary size. For example, a 1 GB dictionary uses a 512 MB hash array, which minimizes collisions in the hashing function.
This multi-level approach provides efficient data compression and storage without significant resource consumption, making LZMA one of the most efficient data compression algorithms.
Benefits of the .lzma file-format
Here are the main advantages of LZMA, making it an attractive choice for many data compression applications.
- High compression ratio: LZMA provides one of the highest compression ratios among existing algorithms, which allows you to significantly reduce file sizes. Average compression ratios exceed 70% compared to other archive formats.
- Fast decompression: The algorithm is optimized for fast data decompression, making LZMA well-suited for use in software applications and storage systems where rapid data retrieval is essential.
- Efficient management of large files: Due to the large size of the search buffer, LZMA can efficiently process large amounts of data while maintaining a high compression rate.
- Reliability and damage tolerance: LZMA provides high resistance to data damage. Even if errors occur during storage or transmission, its design allows for some error correction, minimizing data loss and ensuring the integrity of your information during long-term storage.
- Open source code: The open-source nature of the LZMA algorithm facilitates its widespread implementation, adaptation, and integration into various software solutions, promoting its adoption and ongoing development.
LZMA Archive Supported Operations
Aspose.ZIP allows users to extract both individual files and the entire archive. For .NET, you can use the LzmaArchiveClass to open a .lzma file, then you can step through its records and extract them to the desired location. A similar approach is used in Java, where you use LzmaArchive to open the .lzma file and extract the records. Thanks to Aspose.ZIP, these operations become simple and convenient for users of any level.
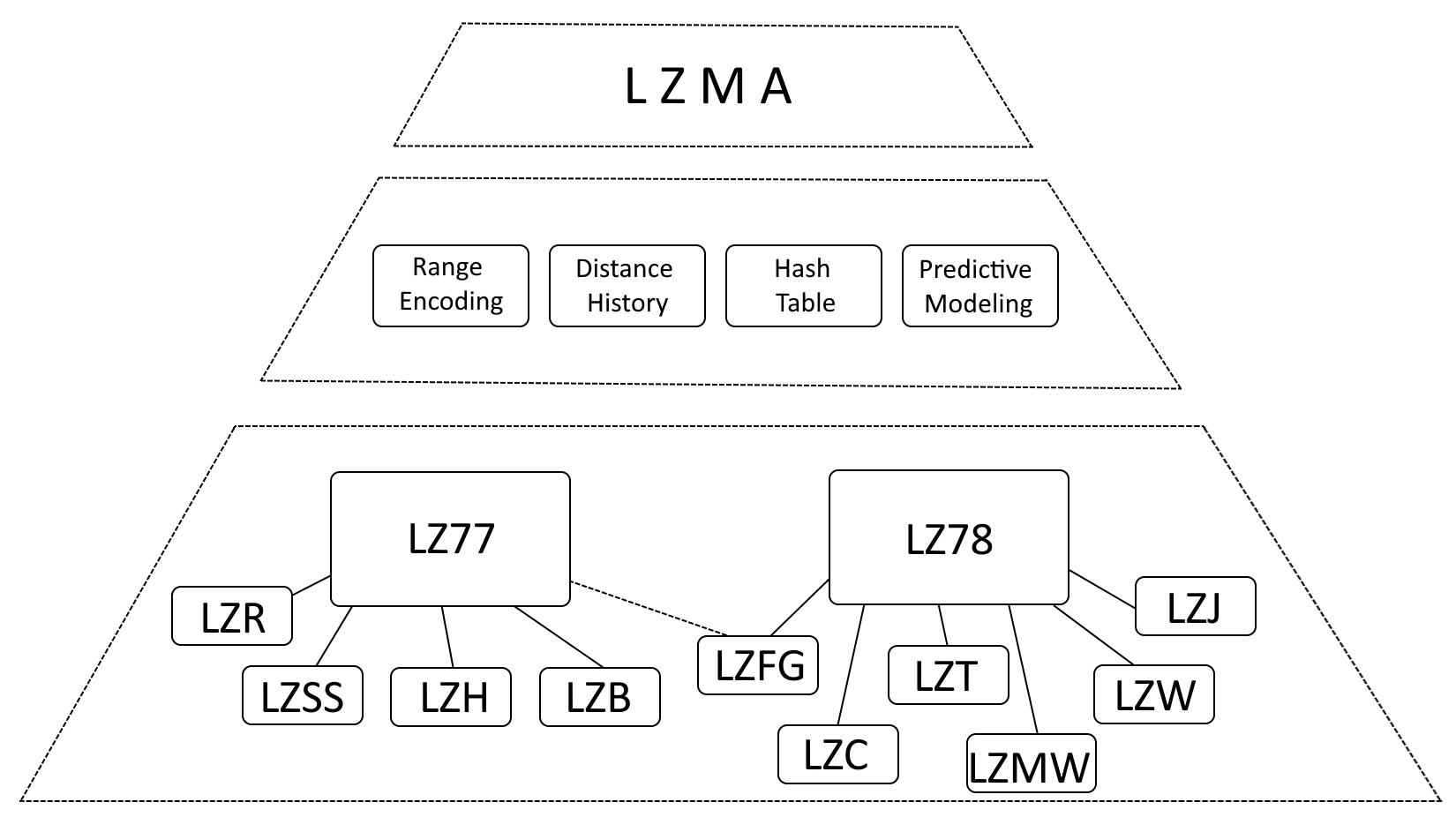
LZMA structure
While it’s accurate to say that LZMA is heavily influenced by LZ77 (Lempel-Ziv 1977) and LZ78 (Lempel-Ziv 1978), it’s more precise to describe LZMA as an evolution of these algorithms, incorporating significant enhancements.
- Range Encoding: LZMA replaces Huffman coding with range encoding, a more efficient data representation method.
- Distance History: LZMA maintains a history of frequently used distances, accelerating match detection.
- Hash Table: LZMA employs a hash table to expedite the search for matching sequences.
- Predictive Modeling: LZMA incorporates predictive modeling techniques to anticipate upcoming data patterns, further enhancing compression.
Inner LZMA Archive Structure
- File Metadata - Similar to a tar archive, each file stores basic information like modification time and permissions. However, this section is flexible and allows omitting or including additional details like access control lists (ACLs) or extended attributes (EAs) based on your needs. It’s recommended to include a strong hash function (like SHA1) for regular files to ensure data integrity.
- Multiple Content Streams - Unlike traditional archives, files can have more than one data stream within the inner data file. This is useful for storing extended attributes or resource forks associated with the file.
- Headers - The inner index file holds file headers, mirroring those scattered throughout the inner data file. But, when stored separately, the index headers must reference the starting position of their corresponding data within the data file. Additionally, directory entries in the index list their contained files and their corresponding offsets within the inner file index.
- Rationale for Duplicate Metadata - This design choice ensures both efficient data streaming/decoding and random file access. Additionally, metadata compresses well, resulting in minimal storage overhead. Tests show metadata typically occupies less than 0.3% of storage space, making the trade-off worthwhile.
- Block Headers - Block headers, similar to the outer file, contain block size information and a unique identifier sequence.
Examples of Using LZMA Python
With the Aspose.ZIP via Python API, you can easily manage LZMA archives in your applications, eliminating the need for other external software. The API includes the LzmaArchive class , which simplifies working with LZMA archives, and the LzmaCompressionSettings class , which allows you to customize compression settings for optimal performance and file size reduction.
LZMA Python .Net Compression
This example demonstrates how to create a 7z archive using the data.bin file. We use LZMA2 compression algorithm with four streams to efficiently compress data more examples here
compression_settings = zp.saving.SevenZipLZMA2CompressionSettings()
compression_settings.compression_threads = 4
entry_settings = zp.saving.SevenZipEntrySettings(compression_settings)
with zp.sevenzip.SevenZipArchive(entry_settings) as archive:
archive.create_entry("data.bin", "data.bin")
archive.save("result.7z")
Additional information about LZMA-archives
People have been asking
1. What file formats use LZMA compression?
LZMA is not a file format itself but a compression algorithm used within various archive formats. Some common examples include 7z, XZ, and occasionally ZIP. When you encounter a file with these extensions, it might be compressed using LZM
2. Is LZMA open-source?
Yes, LZMA is an open-source algorithm, making it freely available for use and integration into various software solutions. This open-source nature has contributed to its widespread adoption and ongoing development.
3. What are some alternatives to LZMA?
Several compression algorithms offer different trade-offs. ZIP balances compression and speed well, BZIP2 provides high compression at the cost of speed compared to LZMA, while XZ, based on LZMA, offers strong compression and is commonly used in Linux environments.