LZ-bestandsindeling
Belangrijkste kenmerken van LZ-archieven - LZ-archieven openen, comprimeren, extraheren en beheren
LZ-archiefformaat
LZ is een archiefformaat dat is ontworpen voor efficiënte gegevenscompressie en dat voornamelijk wordt gebruikt in omgevingen waar het beperken van de opslagruimte en het optimaliseren van de gegevensoverdracht van cruciaal belang zijn. Dit formaat maakt gebruik van het Lempel-Ziv (LZ)-compressie-algoritme en staat bekend om zijn vermogen om grote hoeveelheden gegevens te comprimeren met de nadruk op snelheid en hulpbronnenefficiëntie. LZ-archieven zijn vooral populair in scenario’s die snelle compressie- en decompressiecycli vereisen, waardoor ze geschikt zijn voor zowel softwaredistributie als realtime gegevensverwerking.
Algemene LZ-archiefinformatie
LZ-archieven zijn gecomprimeerde bestandsindelingen die het Lempel-Ziv-algoritme als primaire compressiemethode gebruiken. Bekend om hun snelheid en eenvoud, geven LZ-archieven prioriteit aan efficiënte compressie boven maximale compressieverhoudingen. Dit maakt ze geschikt voor toepassingen die snelle compressie en decompressie vereisen, zoals realtime gegevensverwerking of ingebedde systemen. De .lz-extensie is de meest voorkomende extensie voor LZ-gecomprimeerde bestanden. Hoewel LZ-archieven snelle compressie bieden, maken hun beperkingen in termen van compressieverhouding en metadata ze minder geschikt voor het archiveren van grote datasets of het behouden van bestandskenmerken. Moderne compressieformaten zoals ZIP, gzip en XZ hebben LZ in veel toepassingen verdrongen vanwege hun verbeterde functies en prestaties.
LZ Archief Geschiedenis
- 1977: De basis voor LZ-compressie werd gelegd door de Israëlische computerwetenschappers Abraham Lempel en Jacob Ziv, die het LZ77-algoritme introduceerden. Dit was het eerste algemeen aanvaarde algoritme voor verliesloze datacompressie, waarbij een schuifvenster werd gebruikt om herhaalde datapatronen te comprimeren.
- 1978: Lempel en Ziv introduceren het LZ78-algoritme, een verbetering ten opzichte van LZ77, dat gebruik maakte van een op woordenboeken gebaseerde aanpak. Dit algoritme verbeterde de compressie-efficiëntie verder en inspireerde vele daaropvolgende compressietechnieken.
- 1984: Terry Welch bouwde voort op het LZ78-algoritme om LZW (Lempel-Ziv-Welch) te ontwikkelen, dat populair werd door het gebruik ervan in de Unix-compressieopdracht en het GIF-beeldformaat. LZW was een van de eerste veelgebruikte compressie-algoritmen in commerciële toepassingen.
- Jaren negentig: Varianten van het LZ-algoritme bleven evolueren, wat leidde tot de ontwikkeling van meer geavanceerde compressiemethoden zoals LZMA (Lempel-Ziv-Markov-ketenalgoritme) gebruikt in formaten als 7z en XZ , die hogere compressieverhoudingen bieden.
- Jaren 2000: Op LZ gebaseerde compressietechnieken, met name LZW, raakten ingebed in veel bestandsformaten en protocollen, hoewel sommige, zoals GIF, te maken kregen met patentgerelateerde problemen die het gebruik ervan beïnvloedden.
- Jaren 2010: Op LZ gebaseerde algoritmen, met name LZMA en zijn varianten, blijven fundamenteel in moderne compressiesoftware, waarbij een hoge compressie-efficiëntie in evenwicht wordt gebracht met redelijke prestaties. Ze worden nog steeds veel gebruikt in softwaredistributie, archivering en gegevensopslag.
- Jaren 2020: het LZ-formaat blijft een betrouwbare en efficiënte keuze voor compressie, vooral in omgevingen waar snelheid en eenvoud prioriteit krijgen.
Kenmerken van LZ-archief
Het LZ-archiefformaat volgt een eenvoudige structuur, waarbij snelheid prioriteit krijgt boven uitgebreide functies. Hier is de basisstructuur van het LZ-archief belangrijk voor het werken met oude gecomprimeerde bestanden en het evalueren van de evolutie van compressietechnologieën.
- Compressie van één bestand: comprimeert doorgaans één bestand naar een .lz-archief.
- LZW-algoritme: maakt gebruik van de Lempel-Ziv-Welch-compressiemethode.
- Gebrek aan metadata: er wordt weinig of geen metadata over het originele bestand opgeslagen in het archief.
- Eenvoud: de eenvoudige structuur van het formaat draagt bij aan de hoge compressie- en decompressiesnelheden.
LZ Archief Compressiemethoden
Het LZ-archiefformaat maakt gebruik van het Lempel-Ziv (LZ)-algoritme, dat bekend staat om zijn eenvoud en snelheid, waardoor het een voorkeurskeuze is in scenario’s waarin snelle compressie en decompressie van cruciaal belang zijn. Hieronder vindt u een overzicht van de compressiemethoden die bij LZ horen:
- Lempel-Ziv-algoritme: De kern van het LZ-archiefformaat is gebaseerd op het LZ-algoritme, een verliesvrije compressiemethode die redundantie in gegevens identificeert en elimineert door herhaalde reeksen te vervangen door kortere codes. Het LZ-algoritme werkt door een woordenboek van reeksen op te bouwen terwijl het de gegevens verwerkt, waardoor een efficiënte compressie van grote en repetitieve datasets mogelijk is. Deze methode is vooral effectief in scenario’s waarin gegevenspatronen consistent en voorspelbaar zijn.
- Schuifvenstertechniek: Het LZ-algoritme maakt doorgaans gebruik van een schuifvenstermechanisme, waarbij een venster met een vaste grootte over de invoergegevensstroom beweegt om herhaalde reeksen te vinden. Dankzij deze aanpak kan het algoritme een beheersbare woordenboekgrootte behouden en toch een aanzienlijke compressie bereiken. Het schuifvenster speelt een belangrijke rol bij het balanceren van de compressie-efficiëntie en het geheugengebruik, waardoor de LZ-methode geschikt is voor systemen met beperkte bronnen.
- Controlesom en foutdetectie: Hoewel het LZ-formaat zich richt op compressie, kan het ook basiscontrolesommechanismen bevatten, zoals CRC32, om de integriteit van de gecomprimeerde gegevens te garanderen. Deze controlesommen helpen bij het opsporen van fouten die kunnen optreden tijdens opslag of verzending, zodat de gedecomprimeerde gegevens accuraat en onbeschadigd blijven.
- Optionele verbeteringen: In sommige implementaties kan de LZ-compressiemethode worden uitgebreid met aanvullende technieken zoals run-length-codering (RLE) of delta-codering, waardoor de omvang van de gecomprimeerde gegevens verder kan worden verminderd. Deze optionele verbeteringen worden toegepast op specifieke soorten gegevens binnen het archief, waardoor een efficiëntere compressie van bepaalde inhoudstypen, zoals afbeeldingen of uitvoerbare code, mogelijk wordt.
.lz ondersteunde bewerkingen
Aspose.Zip biedt uitgebreide ondersteuning voor het werken met .lz-archieven, waardoor het eenvoudiger wordt om gecomprimeerde bestanden te beheren. Dit is wat u kunt doen:
- Volledige extractie: Extraheer eenvoudig alle bestanden uit een .lz-archief, waarbij de integriteit en structuur van de originele inhoud behouden blijft.
- Selectieve extractie: Target specifieke bestanden binnen een .lz-archief, waardoor nauwkeurig gegevensherstel of selectieve decompressie mogelijk is op basis van bestandsnamen of andere criteria.
- Gegevenscompressie: Creëer .lz-archieven van bestanden en mappen, met behulp van de efficiënte LZMA2-compressiemethode om de bestandsgrootte aanzienlijk te verkleinen.
- Aangepaste compressie-instellingen: Pas compressieniveaus en andere parameters aan om een evenwicht te vinden tussen compressiesnelheid en bestandsgrootte, zodat het proces wordt afgestemd op uw specifieke behoeften.
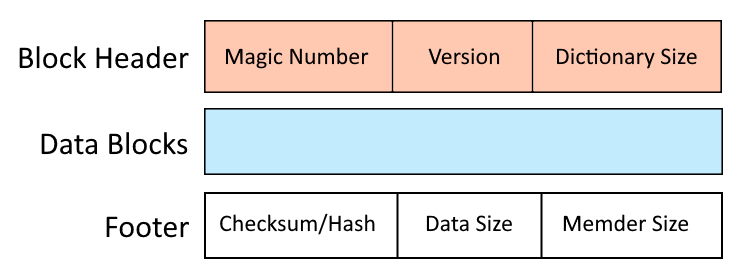
Structuur van .LZ-bestand
Omdat het Lzip-formaat niet meerdere bestanden comprimeert en de metagegevens niet opslaat, wordt het vaak gebruikt met de combinatie van het tar-hulpprogramma. Het Lzip-archiefformaat is ontworpen met de nadruk op efficiëntie en snelheid, waarbij gebruik wordt gemaakt van een gelaagde structuur die snelle compressie en decompressie mogelijk maakt. Het Lzip-archief bestaat uit een of meerdere leden die één voor één in het archief zijn opgeslagen. De structuur van een Lzip-lid omvat de volgende componenten:
- Blokkop:
- Magisch nummer: een unieke identificatie die het begin van het Lzip-archief aangeeft en ervoor zorgt dat het bestand wordt herkend als een geldig Lzip-formaat.
- Versie-informatie: geeft de gebruikte versie van de Lzip aan, wat helpt bij het garanderen van verdere compatibiliteit met verschillende decompressietools. Nu heeft het waarde “1”.
- Woordenboekgrootte: dit veld biedt informatie over de details van de LZMA-compressie die wordt gebruikt voor het komende datablok.
- Gecomprimeerd gegevensblok:
- Gecomprimeerde payload: de kern van het LZ-archief, deze sectie bevat de gecomprimeerde gegevensstroom. Het Lempel-Ziv-Markov-ketenalgoritme verwerkt de originele gegevens tot een reeks codes die herhaalde reeksen vertegenwoordigen, waardoor de bestandsgrootte aanzienlijk wordt verkleind. Hetzelfde compressie-algoritme wordt ondersteund in xz- en 7z-formaten.
- Blokvoettekst:
- Checksum/Hash: Er is een checksum (zoals CRC32) of cryptografische hash (zoals SHA-256) opgenomen om de integriteit van de gecomprimeerde gegevens te verifiëren. Dit zorgt ervoor dat er tijdens de verzending of opslag niet met het archief is geknoeid of beschadigd.
- Gegevensgrootte: de grootte van een deel van het originele bestand dat in dit blok is gecomprimeerd.
- Memdergrootte: een deel van de gedistribueerde index met gecomprimeerde grootte en offset, waarmee blokken onafhankelijk kunnen worden geëxtraheerd.
Populariteit van het LZ-formaat
Het LZ-archiefformaat, gebaseerd op het Lempel-Ziv-compressie-algoritme, is een fundamentele technologie in de wereld van datacompressie. De wijdverbreide acceptatie ervan wordt toegeschreven aan de eenvoud, efficiëntie en het vermogen om aanzienlijke compressieverhoudingen te bereiken, vooral voor gegevens met zich herhalende patronen. Op LZ gebaseerde compressiemethoden zijn opgenomen in verschillende bestandsformaten en compressietools, waardoor het LZ-formaat een veelzijdig en essentieel onderdeel is in gegevensopslag-, transmissie- en archiveringsprocessen. Hoewel er nieuwere compressie-algoritmen zoals LZMA en Brotli zijn verschenen, blijft het LZ-formaat relevant vanwege de balans tussen compressiesnelheid en effectiviteit.
In UNIX- en Linux-omgevingen wordt LZ-compressie vaak gebruikt in combinatie met andere tools, zoals tar, om gecomprimeerde archieven te creëren voor softwaredistributie en gegevensback-up. De integratie ervan in talloze compressiehulpprogramma’s heeft ervoor gezorgd dat het voortdurend kan worden gebruikt op verschillende platforms, waaronder Windows en macOS. Hoewel het LZ-formaat misschien niet zo algemeen wordt erkend als andere compressieformaten zoals ZIP of GZIP, valt de invloed ervan op de datacompressietechnologie niet te ontkennen, en wordt het nog steeds gebruikt in verschillende scenario’s waarin snelle, betrouwbare compressie noodzakelijk is.
Voorbeelden van het gebruik van LZ-archieven
In deze sectie vindt u codevoorbeelden die laten zien hoe u LZ-archieven kunt comprimeren en openen met C#, Java en Python.NET. Deze voorbeelden maken gebruik van bibliotheken en klassen zoals LzipArchive voor het beheren van LZ-bestanden, wat het praktische gebruik van LZ-compressie in moderne programmeeromgevingen illustreert.
Compresses a file into .LZ archive using the LzipArchive class in C#.
using (LzipArchive archive = new LzipArchive())
{
archive.SetSource("data.bin");
archive.Save("data.bin.lz");
}
Extract LZip Archive using C#
using (FileStream sourceLzipFile = File.Open("data.bin.lz", FileMode.Open))
{
using (FileStream extractedFile = File.Open("data.bin", FileMode.Create))
{
using (LzipArchive archive = new LzipArchive(sourceLzipFile))
{
archive.Extract(extractedFile);
}
}
}
Compresses a file into .LZ archive using the LzipArchive class in Java.
try (LzipArchive archive = new LzipArchive()) {
archive.setSource("data.bin");
archive.save("data.bin.lz");
}
Extract LZip Archive using Java
try (FileInputStream sourceLzipFile = new FileInputStream("data.bin.lz")) {
try (FileOutputStream extractedFile = new FileOutputStream("data.bin")) {
try (LzipArchive archive = new LzipArchive(sourceLzipFile)) {
archive.extract(extractedFile);
}
}
} catch (IOException ex) {
}
Compresses a file into .LZ archive using the LzipArchive class using Python.Net
with aspose.zip.lzip.LzipArchive() as archive:
archive.set_source("data.bin")
archive.save("data.bin.lz")
Extract Lzip Archive using Python.Net
with io.FileIO("data.bin.lz", "rb") as source_lzip_file:
with io.FileIO("data.bin", "x") as extracted_file:
with aspose.zip.lzip.LzipArchive(source_lzip_file) as archive:
archive.extract(extracted_file)
Aspose.Zip offers individual archive processing APIs for popular development environments, listed below:
Aanvullende informatie
Mensen hebben ernaar gevraagd
1. Wordt het LZ-archiefformaat ondersteund op alle besturingssystemen?
Het LZ-archiefformaat wordt ondersteund op meerdere platforms, waaronder UNIX, Linux, Windows en macOS. Hoewel het meestal wordt geassocieerd met UNIX-achtige omgevingen, zijn tools en bibliotheken die LZ-archieven verwerken beschikbaar voor alle belangrijke besturingssystemen.
2. Wat zijn de voordelen van het gebruik van LZ-archieven?
LZ-archieven staan bekend om hun efficiëntie bij het comprimeren van gegevens met herhaalde patronen, en bieden een goede balans tussen compressiesnelheid en verkleining van de bestandsgrootte. Ze zijn eenvoudig te implementeren, waardoor ze een betrouwbare keuze zijn voor snelle gegevenscompressie, met name op het gebied van softwaredistributie, gegevensback-up en netwerktransmissie.
3. Kan ik meerdere bestanden comprimeren in één enkel LZ-archief?
Het LZ-formaat wordt doorgaans gebruikt voor het comprimeren van afzonderlijke bestanden. Om meerdere bestanden te comprimeren, moet u ze eerst combineren in een archief (zoals een tarball met behulp van tar) en vervolgens het resulterende archiefbestand comprimeren met LZ-compressie. Dit proces is gebruikelijk in UNIX- en Linux-omgevingen.