LZ filformat
Nyckelfunktioner i LZ-arkiv - Hur man öppnar, komprimerar, extraherar och hanterar LZ-arkiv
LZ arkivformat
LZ är ett arkivformat designat för effektiv datakomprimering, främst använt i miljöer där reducering av lagringsutrymme och optimering av dataöverföring är avgörande. Med hjälp av Lempel-Ziv (LZ) komprimeringsalgoritmen är detta format känt för sin förmåga att komprimera stora datamängder med fokus på hastighet och resurseffektivitet. LZ-arkiv är särskilt populära i scenarier som kräver snabba komprimerings- och dekompressionscykler, vilket gör dem lämpliga för både programvarudistribution och databehandling i realtid.
Allmän LZ-arkivinformation
LZ-arkiv är komprimerade filformat som använder Lempel-Ziv-algoritmen som sin primära komprimeringsmetod. Kända för sin snabbhet och enkelhet, LZ-arkiv prioriterar effektiv komprimering framför maximala kompressionsförhållanden. Detta gör dem lämpliga för applikationer som kräver snabb komprimering och dekompression, såsom databehandling i realtid eller inbyggda system. .lz-tillägget är det vanligaste tillägget för LZ-komprimerade filer. hile LZ-arkiv erbjuder snabb komprimering, deras begränsningar i form av komprimeringsförhållande och metadata gör dem mindre lämpliga för att arkivera stora datamängder eller bevara filattribut. Moderna komprimeringsformat som ZIP, gzip och XZ har ersatt LZ i många applikationer på grund av deras förbättrade funktioner och prestanda.
LZ Arkiv Historia
- 1977: Grunden för LZ-komprimering lades av de israeliska datavetarna Abraham Lempel och Jacob Ziv, som introducerade LZ77-algoritmen. Detta var den första allmänt använda algoritmen för förlustfri datakomprimering, med hjälp av ett glidfönster för att komprimera upprepade datamönster.
- 1978: Lempel och Ziv introducerade LZ78-algoritmen, en förbättring jämfört med LZ77, som använde en ordboksbaserad metod. Denna algoritm förbättrade komprimeringseffektiviteten ytterligare och inspirerade många efterföljande komprimeringstekniker.
- 1984: Terry Welch byggde på LZ78-algoritmen för att utveckla LZW (Lempel-Ziv-Welch), som blev populär genom att den användes i Unix-kommandot och GIF-bildformatet. LZW var en av de första allmänt använda komprimeringsalgoritmerna i kommersiella applikationer.
- 1990-talet: Varianter av LZ-algoritmen fortsatte att utvecklas, vilket ledde till utvecklingen av mer avancerade komprimeringsmetoder som LZMA (Lempel-Ziv-Markov-kedjealgoritm) som används i format som 7z och XZ , som erbjuder högre kompressionsförhållanden.
- 2000-talet: LZ-baserade komprimeringstekniker, särskilt LZW, blev inbäddade i många filformat och protokoll, även om vissa, som GIF, stötte på patentrelaterade problem som påverkade deras användning.
- 2010-talet: LZ-baserade algoritmer, särskilt LZMA och dess varianter, är fortfarande grundläggande i modern komprimeringsprogramvara, och balanserar hög komprimeringseffektivitet med rimlig prestanda. De fortsätter att användas i stor utsträckning inom programvarudistribution, arkivering och datalagring.
- 2020-talet: LZ-formatet fortsätter att vara ett pålitligt och effektivt val för komprimering, speciellt i miljöer där hastighet och enkelhet prioriteras.
Egenskaper för LZ-arkiv
LZ-arkivformatet följer en enkel struktur och prioriterar hastighet framför omfattande funktioner. Här är den grundläggande strukturen i LZ-arkivet viktig för att arbeta med gamla komprimerade filer och utvärdera utvecklingen av komprimeringsteknik.
- Enfilskomprimering: Komprimerar vanligtvis en enda fil till ett .lz-arkiv.
- LZW-algoritm: Använder komprimeringsmetoden Lempel-Ziv-Welch.
- Brist på metadata: Begränsad eller ingen metadata om originalfilen lagras i arkivet.
- Enkelhet: Formatets enkla struktur bidrar till dess snabba komprimerings- och dekompressionshastigheter.
LZ Arkiv Komprimeringsmetoder
LZ-arkivformatet använder Lempel-Ziv (LZ)-algoritmen, som är känd för sin enkelhet och hastighet, vilket gör det till ett föredraget val i scenarier där snabb komprimering och dekompression är avgörande. Nedan finns en översikt över de komprimeringsmetoder som är associerade med LZ:
- Lempel-Ziv-algoritm: Kärnan i LZ-arkivformatet är baserad på LZ-algoritmen, en förlustfri komprimeringsmetod som identifierar och eliminerar redundans i data genom att ersätta upprepade sekvenser med kortare koder. LZ-algoritmen fungerar genom att bygga en ordbok med sekvenser när den bearbetar data, vilket möjliggör effektiv komprimering av stora och repetitiva datamängder. Denna metod är särskilt effektiv i scenarier där datamönster är konsekventa och förutsägbara.
- Sliding Window-teknik: LZ-algoritmen använder vanligtvis en skjutfönstermekanism, där ett fönster med fast storlek rör sig över indataströmmen för att hitta upprepade sekvenser. Detta tillvägagångssätt tillåter algoritmen att bibehålla en hanterbar ordboksstorlek samtidigt som den uppnår betydande komprimering. Det skjutbara fönstret är avgörande för att balansera komprimeringseffektivitet med minnesanvändning, vilket gör LZ-metoden lämplig för system med begränsade resurser.
- Kontrollsumma och feldetektering: Även om LZ-formatet fokuserar på komprimering, kan det också innehålla grundläggande kontrollsummemekanismer som CRC32 för att säkerställa integriteten hos den komprimerade datan. Dessa kontrollsummor hjälper till att upptäcka fel som kan uppstå under lagring eller överföring, vilket säkerställer att de komprimerade data förblir korrekta och oförstörda.
- Valfria förbättringar: I vissa implementeringar kan LZ-komprimeringsmetoden förbättras med ytterligare tekniker som run-length-kodning (RLE) eller deltakodning, vilket ytterligare kan minska storleken på den komprimerade datan. Dessa valfria förbättringar tillämpas på specifika typer av data i arkivet, vilket möjliggör mer effektiv komprimering av vissa innehållstyper, såsom bilder eller körbar kod.
.lz Operations som stöds
Aspose.Zip erbjuder omfattande stöd för att arbeta med .lz-arkiv, vilket gör det lättare att hantera komprimerade filer. Så här kan du göra:
- Fullständig extraktion: Extrahera enkelt alla filer från ett .lz-arkiv, bevara integriteten och strukturen för det ursprungliga innehållet.
- Selektiv extraktion: Rikta in specifika filer i ett .lz-arkiv, vilket möjliggör exakt dataåterställning eller selektiv dekomprimering baserat på filnamn eller andra kriterier.
- Datakomprimering: Skapa .lz-arkiv från filer och kataloger, med den effektiva LZMA2-komprimeringsmetoden för att minska filstorlekarna avsevärt.
- Anpassade komprimeringsinställningar: Justera komprimeringsnivåer och andra parametrar för att balansera mellan komprimeringshastighet och filstorlek, skräddarsy processen efter dina specifika behov.
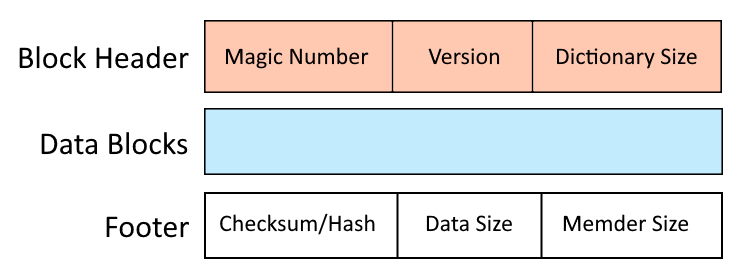
Struktur för .LZ-fil
Lzip-arkivformatet är designat med fokus på effektivitet och hastighet, med en skiktad struktur som underlättar snabb komprimering och dekompression. Lzip-arkivet består av en eller flera medlemmar lagrade i arkivet en efter en. Strukturen för en Lzip-medlem inkluderar följande komponenter:
Blockrubrik:
- Magiskt nummer: En unik identifierare som signalerar början av Lzip-arkivet, vilket säkerställer att filen känns igen som ett giltigt Lzip-format.
- Versionsinformation: Indikerar vilken version av Lzip som används, vilket hjälper till att säkerställa ytterligare kompatibilitet med olika dekompressionsverktyg. Nu har den värdet “1”.
- Ordboksstorlek: Detta fält ger information om detaljerna för LZMA-komprimering som används för kommande datablock.
Komprimerat datablock:
- Komprimerad nyttolast: Kärnan i LZ-arkivet, det här avsnittet innehåller den komprimerade dataströmmen. Lempel-Ziv-Markov-kedjealgoritmen bearbetar originaldata till en serie koder som representerar upprepade sekvenser, vilket avsevärt minskar filstorleken. Samma komprimeringsalgoritm stöds i xz- och 7z-format.
Blockera sidfot:
- Checksumma/Hash: En checksumma (som CRC32) eller kryptografisk hash (som SHA-256) ingår för att verifiera integriteten hos den komprimerade datan. Detta säkerställer att arkivet inte har manipulerats eller skadats under överföring eller lagring.
- Datastorlek: En storlek på en bit av originalfilen komprimerad i detta block.
- Memder Size: en del av distribuerat index med komprimerad storlek och offset, vilket gör det möjligt att extrahera block oberoende.
Eftersom Lzip-formatet inte komprimerar flera filer och inte lagrar dess metadata, används det ofta med kombinationsverktyget tar.
LZ-formatets popularitet
LZ-arkivformatet, baserat på Lempel-Ziv-komprimeringsalgoritmen, har varit en grundläggande teknik inom datakomprimeringsvärlden. Dess utbredda användning tillskrivs dess enkelhet, effektivitet och förmåga att uppnå betydande kompressionsförhållanden, särskilt för data med upprepade mönster. LZ-baserade komprimeringsmetoder har införlivats i olika filformat och komprimeringsverktyg, vilket gör LZ-formatet till en mångsidig och viktig komponent i datalagring, överföring och arkiveringsprocesser. Även om nyare komprimeringsalgoritmer som LZMA och Brotli har dykt upp, förblir LZ-formatet relevant på grund av dess balans mellan komprimeringshastighet och effektivitet.
I UNIX- och Linux-miljöer används LZ-komprimering ofta i kombination med andra verktyg, som tar, att skapa komprimerade arkiv för distribution av programvara och säkerhetskopiering av data. Dess integrering i många komprimeringsverktyg har säkerställt att den fortsätter att användas på olika plattformar, inklusive Windows och macOS. Även om LZ-formatet kanske inte är lika allmänt känt som andra komprimeringsformat som ZIP eller GZIP, är dess inflytande på datakomprimeringsteknik obestridlig, och det fortsätter att användas i olika scenarier där snabb, pålitlig komprimering är nödvändig.
Exempel på användning av LZ Archives
Det här avsnittet ger kodexempel som visar hur man komprimerar och öppnar LZ-arkiv med C#, Java och Python.NET. Dessa exempel använder bibliotek och klasser som LzipArchive för att hantera LZ-filer, vilket illustrerar den praktiska användningen av LZ-komprimering i moderna programmeringsmiljöer.
Compresses a file into .LZ archive using the LzipArchive class in C#.
using (LzipArchive archive = new LzipArchive())
{
archive.SetSource("data.bin");
archive.Save("data.bin.lz");
}
Extract LZip Archive using C#
using (FileStream sourceLzipFile = File.Open("data.bin.lz", FileMode.Open))
{
using (FileStream extractedFile = File.Open("data.bin", FileMode.Create))
{
using (LzipArchive archive = new LzipArchive(sourceLzipFile))
{
archive.Extract(extractedFile);
}
}
}
Compresses a file into .LZ archive using the LzipArchive class in Java.
try (LzipArchive archive = new LzipArchive()) {
archive.setSource("data.bin");
archive.save("data.bin.lz");
}
Extract LZip Archive using Java
try (FileInputStream sourceLzipFile = new FileInputStream("data.bin.lz")) {
try (FileOutputStream extractedFile = new FileOutputStream("data.bin")) {
try (LzipArchive archive = new LzipArchive(sourceLzipFile)) {
archive.extract(extractedFile);
}
}
} catch (IOException ex) {
}
Compresses a file into .LZ archive using the LzipArchive class using Python.Net
with aspose.zip.lzip.LzipArchive() as archive:
archive.set_source("data.bin")
archive.save("data.bin.lz")
Extract Lzip Archive using Python.Net
with io.FileIO("data.bin.lz", "rb") as source_lzip_file:
with io.FileIO("data.bin", "x") as extracted_file:
with aspose.zip.lzip.LzipArchive(source_lzip_file) as archive:
archive.extract(extracted_file)
Aspose.Zip offers individual archive processing APIs for popular development environments, listed below:
Ytterligare information
Folk har frågat
1. Stöds LZ-arkivformatet på alla operativsystem?
LZ-arkivformatet stöds på flera plattformar, inklusive UNIX, Linux, Windows och macOS. Även om det oftast förknippas med UNIX-liknande miljöer, är verktyg och bibliotek som hanterar LZ-arkiv tillgängliga för alla större operativsystem.
2. Vilka är fördelarna med att använda LZ-arkiv?
LZ-arkiv är kända för sin effektivitet i att komprimera data med upprepade mönster, vilket ger en bra balans mellan komprimeringshastighet och filstorleksminskning. De är enkla att implementera, vilket gör dem till ett pålitligt val för snabba datakomprimeringsbehov, särskilt vid distribution av programvara, säkerhetskopiering av data och nätverksöverföring.
3. Kan jag komprimera flera filer till ett enda LZ-arkiv?
LZ-formatet används vanligtvis för att komprimera enstaka filer. För att komprimera flera filer måste du först kombinera dem till ett arkiv (som en tarball med tar) och sedan komprimera den resulterande arkivfilen med LZ-komprimering. Denna process är vanlig i UNIX- och Linux-miljöer.